
Thư viện flextable phiên bản mới nhất 0.9.11 đã chính thức xuất hiện trên CRAN, mang lại những cải tiến vượt trội giúp đơn giản hóa quy trình báo cáo dữ liệu của bạn. Trong bản cập nhật lần này, hai tính năng nổi bật nhất chính là sự tích hợp mượt mà với patchwork và khả năng hỗ trợ định dạng Quarto trực tiếp trong từng ô dữ liệu thông qua hàm as_qmd. Hãy cùng khám phá xem những công cụ này sẽ thay đổi cách chúng ta thiết kế các bảng biểu báo cáo khoa học dữ liệu như thế nào.
Tích hợp patchwork: Thiết kế bố cục biểu đồ và bảng số liệu chuyên nghiệp
Trước đây, việc căn chỉnh một bảng số liệu nằm song song hoặc đồng bộ với một biểu đồ thường đòi hỏi rất nhiều công sức căn chỉnh thủ công. Giờ đây, với sự hỗ trợ của patchwork, quy trình này trở nên vô cùng đơn giản. Hàm mới wrap_flextable cho phép biến đổi các đối tượng flextable thành các thành phần có thể dễ dàng ghép nối bằng các toán tử cộng, vạch đứng hoặc gạch chéo của patchwork.
Để minh họa, chúng ta sẽ xây dựng một biểu đồ quả tạ biểu diễn số liệu thống kê của các đội bóng tại giải Bundesliga, sau đó ghép nối nó với một bảng số liệu tương ứng.
Đầu tiên, hãy khởi tạo tập dữ liệu cơ sở:
1dataset <- data.frame(
2 team = c(
3 "FC Bayern Munchen", "SV Werder Bremen", "Borussia Dortmund",
4 "VfB Stuttgart", "Borussia M'gladbach", "Hamburger SV",
5 "Eintracht Frankfurt", "FC Schalke 04", "1. FC Koln",
6 "Bayer 04 Leverkusen"
7 ),
8 matches = c(2000, 1992, 1924, 1924, 1898, 1866, 1856, 1832, 1754, 1524),
9 won = c(1206, 818, 881, 782, 763, 746, 683, 700, 674, 669),
10 lost = c( 363, 676, 563, 673, 636, 625, 693, 669, 628, 447)
11)
12dataset$win_pct <- dataset$won / dataset$matches * 100
13dataset$loss_pct <- dataset$lost / dataset$matches * 100
14dataset$team <- factor(dataset$team, levels = rev(dataset$team))Tiếp theo, chúng ta vẽ biểu đồ quả tạ thể hiện tỷ lệ thắng và thua của từng đội bóng:
1pal <- c(lost = "#EFAC00", won = "#28A87D")
2df_long <- reshape(dataset, direction = "long",
3 varying = list(c("loss_pct", "win_pct")),
4 v.names = "pct", timevar = "type",
5 times = c("lost", "won"), idvar = "team"
6)
7p <- ggplot(df_long, aes(x = pct / 100, y = team)) +
8 stat_summary(
9 geom = "linerange", fun.min = "min", fun.max = "max",
10 linewidth = .7, color = "grey60"
11 ) +
12 geom_point(aes(fill = type), size = 4, shape = 21,
13 stroke = .8, color = "white"
14 ) +
15 scale_x_continuous(
16 labels = scales::percent,
17 expand = expansion(add = c(.02, .02))
18 ) +
19 scale_y_discrete(name = NULL, guide = "none") +
20 scale_fill_manual(
21 values = pal,
22 labels = c(lost = "Lost", won = "Won")
23 ) +
24 labs(x = NULL, fill = NULL) +
25 theme(
26 legend.position = "top",
27 legend.justification = "left",
28 panel.grid.minor = element_blank(),
29 panel.grid.major.y = element_blank()
30 )
31p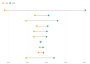
Bây giờ, chúng ta sẽ tạo một bảng dữ liệu flextable tương ứng để chuẩn bị cho quá trình ghép nối:
1ft_dat <- dataset[, c("matches", "win_pct", "loss_pct", "team")]
2ft_dat$team <- as.character(ft_dat$team)
3ft <- flextable(ft_dat) |>
4 border_remove() |>
5 bold(part = "header") |>
6 colformat_double(j = c("win_pct", "loss_pct"), digits = 1, suffix = "%") |>
7 set_header_labels(team = "Team", matches = "GP", win_pct = "Won", loss_pct = "Lost") |>
8 color(color = c("#28A87D", "#EFAC00"), j = c("win_pct", "loss_pct")) |>
9 italic(j = "team", italic = TRUE, part = "all") |>
10 align(align = "right", part = "all") |>
11 autofit()
12ftCăn chỉnh các dòng với thuộc tính flex_body
Khi thiết lập thuộc tính flex_body bằng TRUE, các dòng dữ liệu trong phần thân bảng sẽ tự động giãn ra để khớp chính xác với chiều cao của phân vùng biểu đồ bên cạnh. Lúc này, từng dòng của bảng sẽ khớp hoàn hảo với danh mục tương ứng trên trục tung của biểu đồ, tạo nên một chỉnh thể thống nhất cực kỳ chuyên nghiệp. Phần tiêu đề đầu trang và chân trang vẫn giữ nguyên kích thước cố định để đảm bảo tính dễ đọc.
1wrap_flextable(ft, flex_body = TRUE, just = "right") +
2 p +
3 plot_layout(widths = c(1.1, 2))
Với cách tiếp cận này, bảng số liệu và biểu đồ hòa làm một, giúp người xem dễ dàng đối chiếu số liệu chi tiết ngay bên cạnh các điểm trực quan hóa.
Căn chỉnh các cột với thuộc tính flex_cols
Tương tự như việc căn chỉnh dòng, khi chúng ta đặt thuộc tính flex_cols bằng TRUE, các cột dữ liệu sẽ tự động giãn rộng để lấp đầy chiều rộng của phân vùng được xác định bởi biểu đồ lân cận. Mỗi cột của bảng sẽ nằm thẳng hàng với danh mục tương ứng trên trục hoành của biểu đồ cột phía dưới.
Hãy cùng thực hiện ví dụ thực tế dưới đây để thấy rõ sự tiện lợi này:
1cyl_mpg <- mtcars |>
2 mutate(
3 cyl = factor(cyl, levels = c(4, 6, 8), labels = c("4-cyl", "6-cyl", "8-cyl"))
4 ) |>
5 summarise(
6 `mpg mean` = mean(mpg, na.rm = TRUE),
7 `mpg sd` = sd(mpg, na.rm = TRUE),
8 n = n(),
9 .by = c(cyl)
10 )
11gg_bar <- ggplot(cyl_mpg, aes(cyl, `mpg mean`)) +
12 geom_col(fill = "#28A87D", width = 0.7) +
13 labs(x = "Cylinders", y = "Mean MPG") +
14 theme(axis.text.x = element_blank())
15cyl_pivoted <- cyl_mpg |>
16 pivot_longer(
17 cols = where(is.numeric)
18 ) |>
19 pivot_wider(
20 id_cols = name,
21 names_from = cyl, values_from = value,
22 names_sort = TRUE
23 )
24set_flextable_defaults(border.color = "#28A87D")
25ft_cyl <- flextable(cyl_pivoted) |>
26 set_header_labels(name = "") |>
27 align(align = "center", part = "all") |>
28 align(align = "right", j = 1, part = "all") |>
29 colformat_double(i = 1:2, digits = 2) |>
30 colformat_double(i = 3, digits = 0) |>
31 autofit()
32wrap_flextable(ft_cyl, n_row_headers = 1, flex_cols = TRUE) /
33 gg_bar +
34 plot_layout(heights = c(1, 4))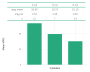
Sự đồng bộ hoàn hảo giữa biểu đồ cột và các cột số liệu phía trên tạo ra trải nghiệm đọc báo cáo liền mạch và rõ ràng hơn bao giờ hết.
Trình bày mã nguồn Quarto trực tiếp trong ô dữ liệu
Trước phiên bản này, flextable chưa hỗ trợ định dạng markdown bên trong các ô dữ liệu. Điều này đồng nghĩa với việc bạn không thể chèn các liên kết, công thức toán học hay thực hiện tham chiếu chéo trong tài liệu Quarto một cách trực tiếp. Hàm mới as_qmd đã giải quyết triệt để hạn chế này.
Tính năng as_qmd hoạt động tương thích với nhiều định dạng đầu ra bao gồm HTML, PDF và tài liệu Word.
Để bắt đầu sử dụng tính năng này trong một dự án Quarto, trước tiên bạn cần cài đặt phần mở rộng lọc Lua đồng hành bằng cách chạy lệnh use_flextable_qmd, sau đó khai báo bộ lọc này trong phần cấu hình YAML của tài liệu.
Dưới đây là một ví dụ về cấu trúc mã nguồn khi sử dụng as_qmd để định dạng văn bản và tham chiếu chéo ngay bên trong các ô của bảng:
1# Cau hinh bo loc YAML trong file Quarto (.qmd)
2# filters:
3# - flextable-qmd
4# - at: post-render
5# path: _extensions/flextable-qmd/unwrap-float.lua
6# Doan ma nguon R trien khai trong tai lieu Quarto:
7library(flextable)
8dat <- data.frame(
9 Feature = c("Tham chieu cheo", "Dinh dang chu", "Cong thuc toan", "Lien ket"),
10 Demo = c(
11 "Xem tai Table tbl-example",
12 "van ban quan trong",
13 "E = mc^2",
14 "ardata.fr"
15 ),
16 stringsAsFactors = FALSE
17)
18flextable(dat) |>
19 mk_par(j = "Demo",
20 value = as_paragraph(as_qmd(Demo))) |>
21 autofit() |>
22 theme_vanilla()
Việc kết xuất ra định dạng tài liệu Word giờ đây trở nên vô cùng trực quan và lưu giữ trọn vẹn các định dạng mong muốn ngay trong bảng biểu của bạn.
✨ Giá trị đắt giá
Sự kết hợp giữa wrap_flextable và patchwork giúp xóa nhòa ranh giới giữa bảng số liệu tĩnh và biểu đồ động. Thay vì tạo ra hai phần độc lập, giờ đây bạn có thể hợp nhất chúng thành một sản phẩm truyền thông dữ liệu duy nhất, đồng bộ tuyệt đối về mặt thị giác. Điều này không chỉ nâng cao tính thẩm mỹ mà còn giúp giảm thiểu đáng kể thời gian thiết kế báo cáo thủ công cho các nhà phân tích dữ liệu.
Câu hỏi tư duy hoặc bài tập ứng dụng
Hãy thử áp dụng hàm wrap_flextable vào tập dữ liệu hiện tại của bạn. Bạn sẽ lựa chọn phương án đồng bộ dòng flex_body hay đồng bộ cột flex_cols để tối ưu hóa khả năng truyền tải thông tin của báo cáo? Hãy chia sẻ thiết kế của bạn và những cải thiện về mặt thời gian xử lý mà tính năng mới này mang lại.

