Trong bài viết này, tôi sẽ giới thiệu cho bạn một cách tiếp cận tương đối đơn giản về thống kê Bayes. Phương pháp Bayes ngày càng trở nên phổ biến và bạn có thể thực hiện các mô hình này bằng lệnh bayesmh trong phần mềm Stata. Nội dung hôm nay sẽ tập trung vào các khái niệm, thuật ngữ chuyên môn và cú pháp cơ bản. Trong bài viết tiếp theo, chúng ta sẽ cùng tìm hiểu sâu hơn về mô hình Markov chain Monte Carlo thông qua thuật toán Metropolis-Hastings.
Thống kê bayes qua ví dụ thực tế
Nhiều người trong chúng ta được đào tạo theo trường phái thống kê tần suất, nơi các tham số được coi là các đại lượng cố định nhưng chưa biết giá trị. Chúng ta ước lượng các tham số này bằng cách lấy mẫu từ quần thể, và các mẫu khác nhau sẽ cho ra các ước lượng khác nhau. Tập hợp các ước lượng này tạo nên phân phối mẫu, giúp định lượng sự không chắc chắn của kết quả. Tuy nhiên, bản thân tham số vẫn luôn được xem là một hằng số cố định.
Thống kê Bayes mang đến một tư duy hoàn toàn khác. Ở đây, các tham số được đối xử như các biến ngẫu nhiên và có thể được mô tả bằng các phân phối xác suất. Chúng ta thậm chí không cần dữ liệu để mô tả phân phối của một tham số, bởi xác suất đơn giản là mức độ tin tưởng của chúng ta vào giá trị đó.
Hãy lấy ví dụ về việc tung đồng xu để xây dựng trực giác. Tôi gọi hai mặt của đồng xu là mặt ngửa và mặt sấp. Khi tung đồng xu, nó phải rơi vào một trong hai mặt này. Tôi sẽ dùng ký hiệu theta để chỉ xác suất đồng xu hiện mặt ngửa.
Phân phối tiên nghiệm
Bước đầu tiên trong phân phối Bayes là xác định phân phối tiên nghiệm cho theta. Đây là biểu thức toán học thể hiện niềm tin của chúng ta về sự phân bổ của tham số trước khi có dữ liệu thực tế. Niềm tin này có thể dựa trên kinh nghiệm, các giả định hoặc thậm chí chỉ là một dự đoán sơ bộ. Ví dụ, tôi có thể dùng phân phối đều để thể hiện rằng xác suất xuất hiện mặt ngửa có thể nằm bất kỳ đâu từ 0 đến 1 với khả năng như nhau. Hình 1 cho thấy một phân phối beta với các tham số là 1 và 1, tương đương với một phân phối đều trên khoảng từ 0 đến 1.
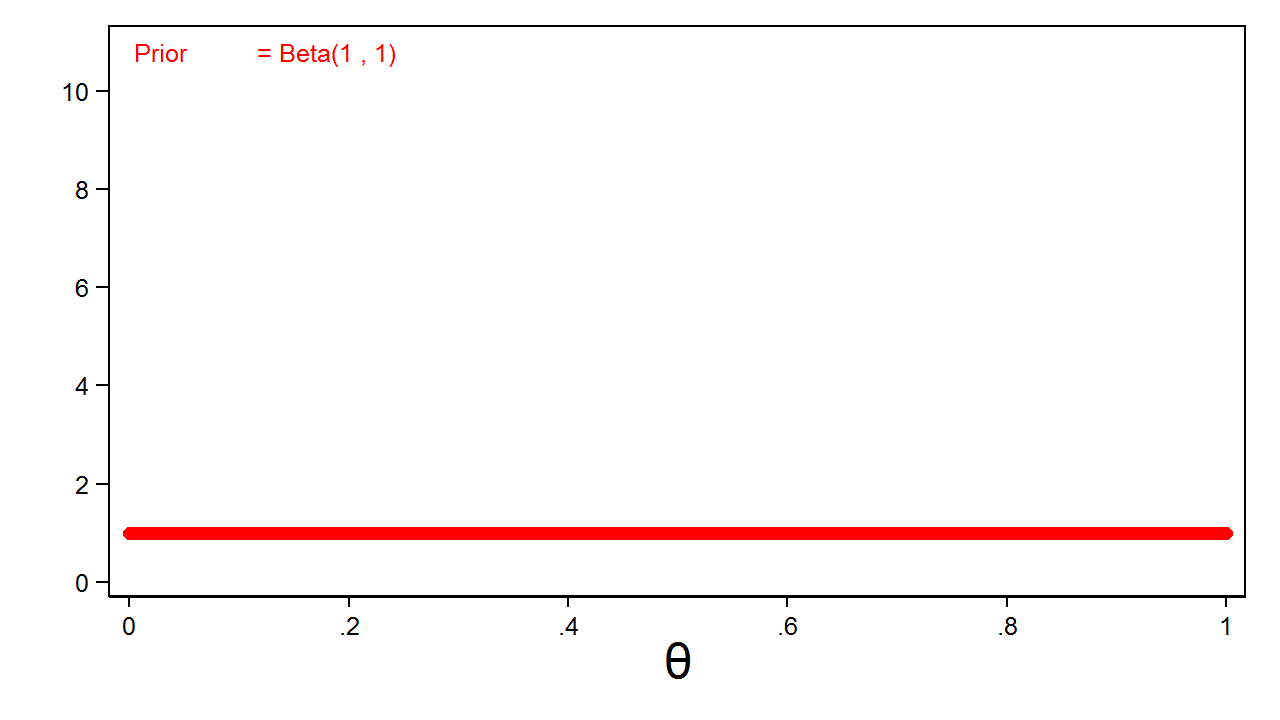
Phân phối beta(1,1) này được gọi là phân phối tiên nghiệm không có thông tin vì tất cả các giá trị của tham số đều có xác suất xảy ra như nhau.
Tuy nhiên, kinh nghiệm thông thường cho thấy xác suất mặt ngửa sẽ gần mức 0.5. Tôi có thể diễn đạt niềm tin này bằng cách tăng các tham số của phân phối beta. Hình 2 hiển thị phân phối beta với các tham số là 30 và 30.
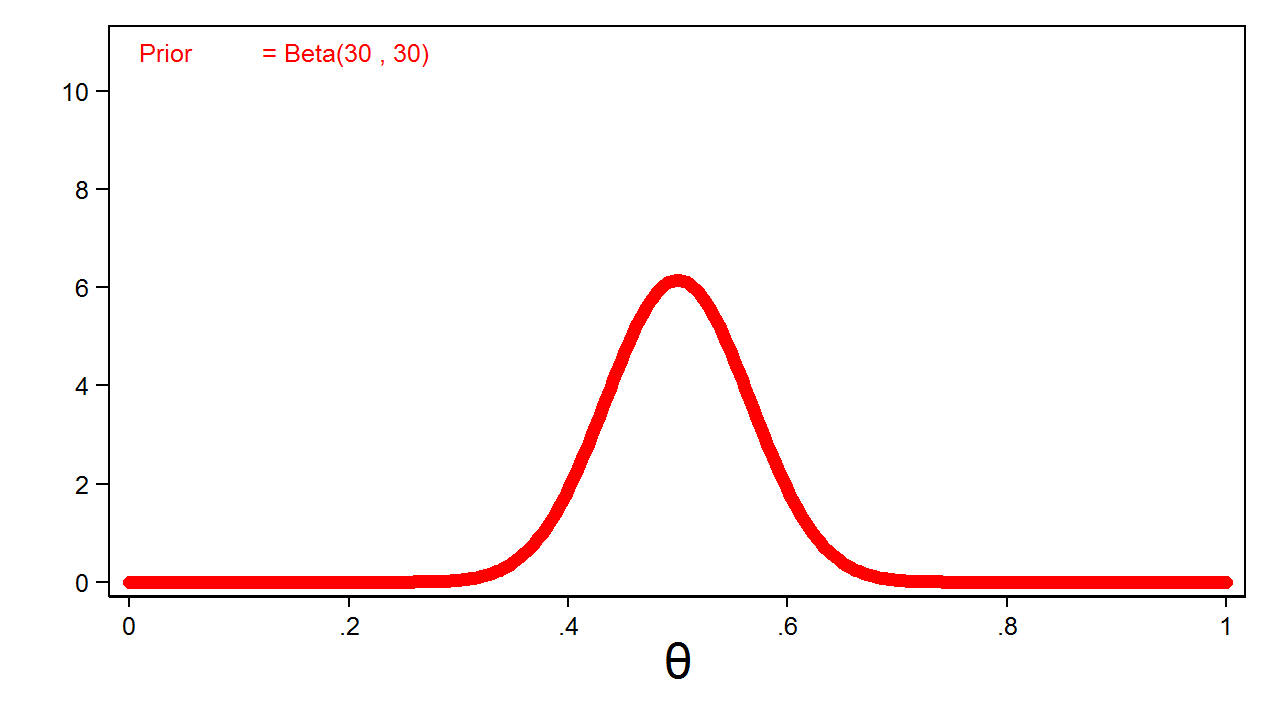
Đây được gọi là phân phối tiên nghiệm có thông tin vì các giá trị tham số không còn có xác suất bằng nhau nữa, mà tập trung quanh một vùng giá trị nhất định.
Hàm hợp lý
Bước thứ hai là thu thập dữ liệu và xác định hàm hợp lý. Giả sử tôi tung đồng xu 10 lần và quan sát thấy có 4 lần hiện mặt ngửa. Tôi sẽ nhập kết quả này vào Stata để xử lý.
1clear
2input heads
30
40
51
60
70
81
91
100
110
121Tiếp theo, tôi cần xác định hàm hợp lý cho dữ liệu của mình. Trong khi phân phối xác suất định lượng khả năng xảy ra của dữ liệu dựa trên một giá trị tham số cho trước, thì hàm hợp lý lại định lượng khả năng của một giá trị tham số khi đã biết dữ liệu. Về mặt hình thức toán học, hai khái niệm này thường được sử dụng thay thế cho nhau.
Phân phối xác suất nhị thức thường được dùng để tính số lần thành công trong một số lần thử cố định. Ở đây, tôi có thể định lượng kết quả thí nghiệm bằng hàm hợp lý nhị thức cho tham số theta khi có 4 lần mặt ngửa trong 10 lần tung.
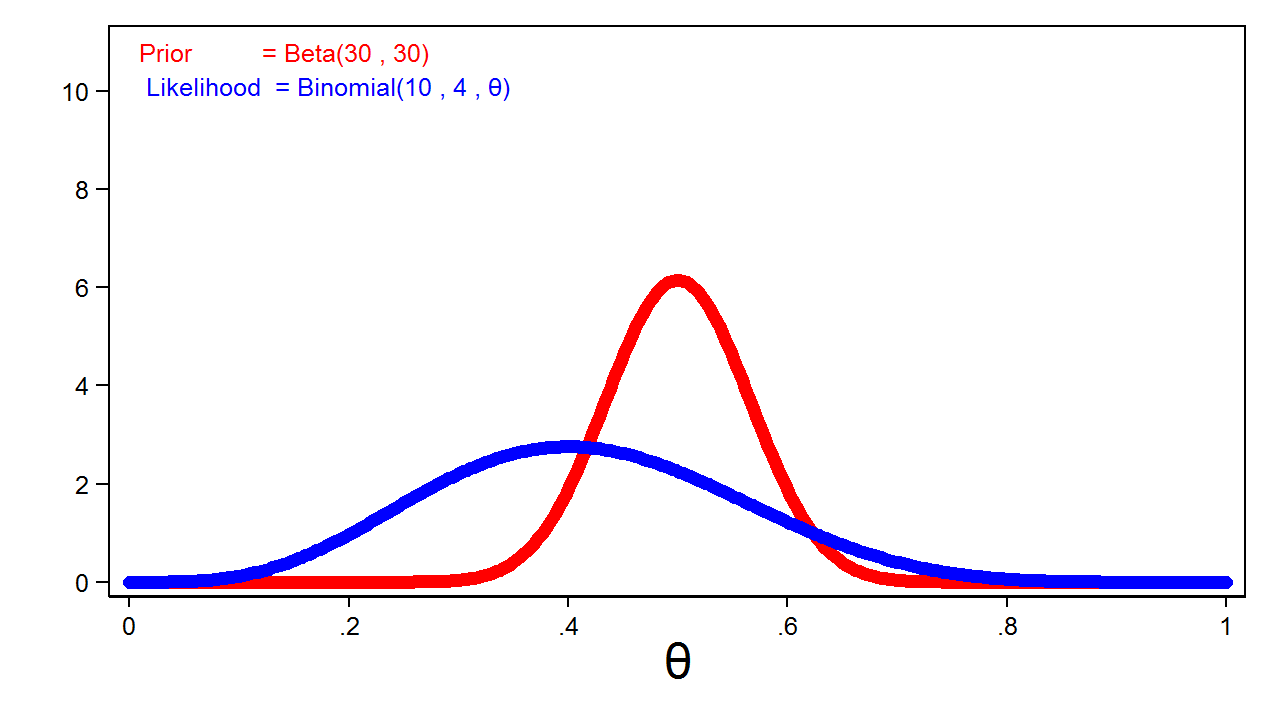
Đường màu xanh trong hình 3 hiển thị hàm hợp lý nhị thức cho theta. Tôi đã điều chỉnh tỷ lệ sao cho diện tích dưới đường cong bằng 1 để dễ dàng so sánh với phân phối tiên nghiệm màu đỏ.
Phân phối hậu nghiệm
Bước thứ ba là tính toán phân phối hậu nghiệm. Điều này cho phép chúng ta cập nhật niềm tin về tham số sau khi đã có kết quả thực nghiệm. Trong các trường hợp đơn giản, chúng ta tính phân phối hậu nghiệm bằng cách nhân phân phối tiên nghiệm với hàm hợp lý. Nói một cách chính xác, phân phối hậu nghiệm tỉ lệ thuận với tích của tiên nghiệm và hợp lý.
Phân phối hậu nghiệm bằng Phân phối tiên nghiệm nhân với Hàm hợp lý.
Trong ví dụ này, phân phối beta được gọi là tiên nghiệm liên hợp cho hàm hợp lý nhị thức vì phân phối hậu nghiệm thu được cũng thuộc cùng họ phân phối với phân phối tiên nghiệm.
Hình 4 hiển thị phân phối hậu nghiệm của theta cùng với phân phối tiên nghiệm và hàm hợp lý.
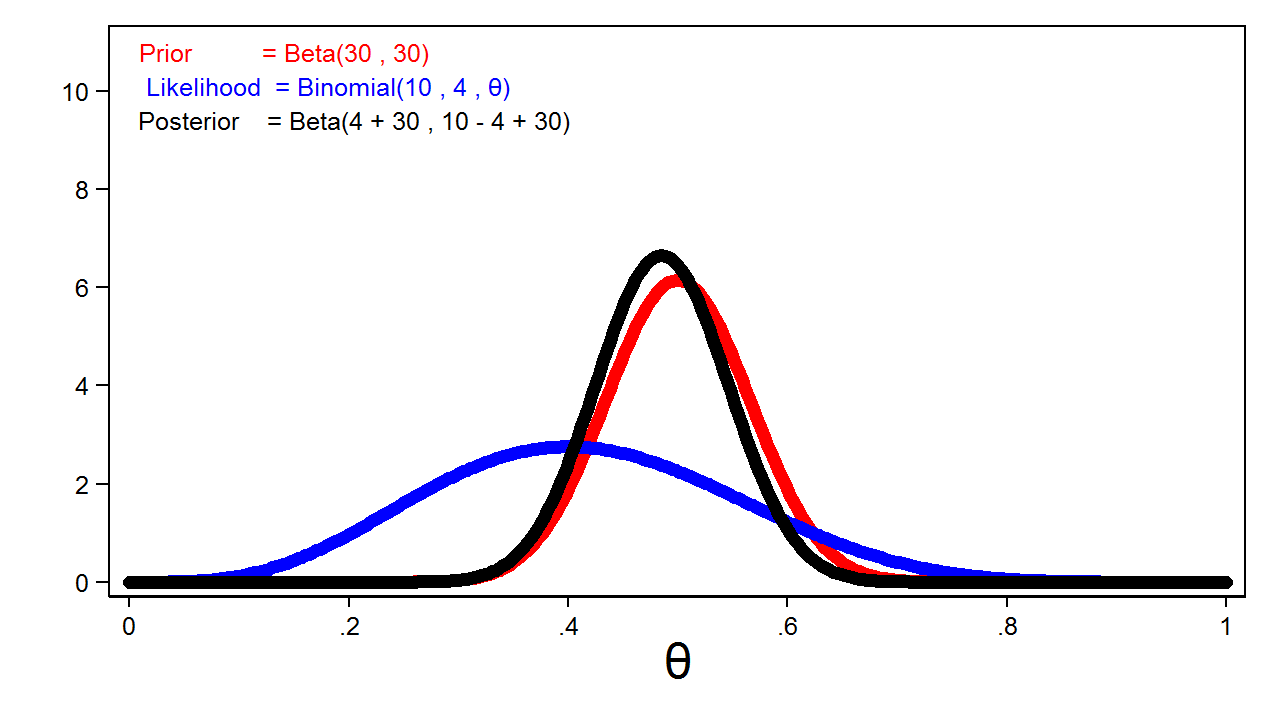
Bạn có thể thấy phân phối hậu nghiệm trông rất giống phân phối tiên nghiệm. Điều này xảy ra do chúng ta đã sử dụng một tiên nghiệm có thông tin mạnh trong khi kích thước mẫu lại tương đối nhỏ.
Hãy cùng xem xét ảnh hưởng của các loại tiên nghiệm và kích thước mẫu khác nhau. Trong hình 5, đường màu đỏ thể hiện phân phối tiên nghiệm beta(1,1) hoàn toàn không có thông tin. Đường màu xanh là hàm hợp lý. Bạn sẽ thấy đường màu xanh bị che lấp bởi đường màu đen của phân phối hậu nghiệm.
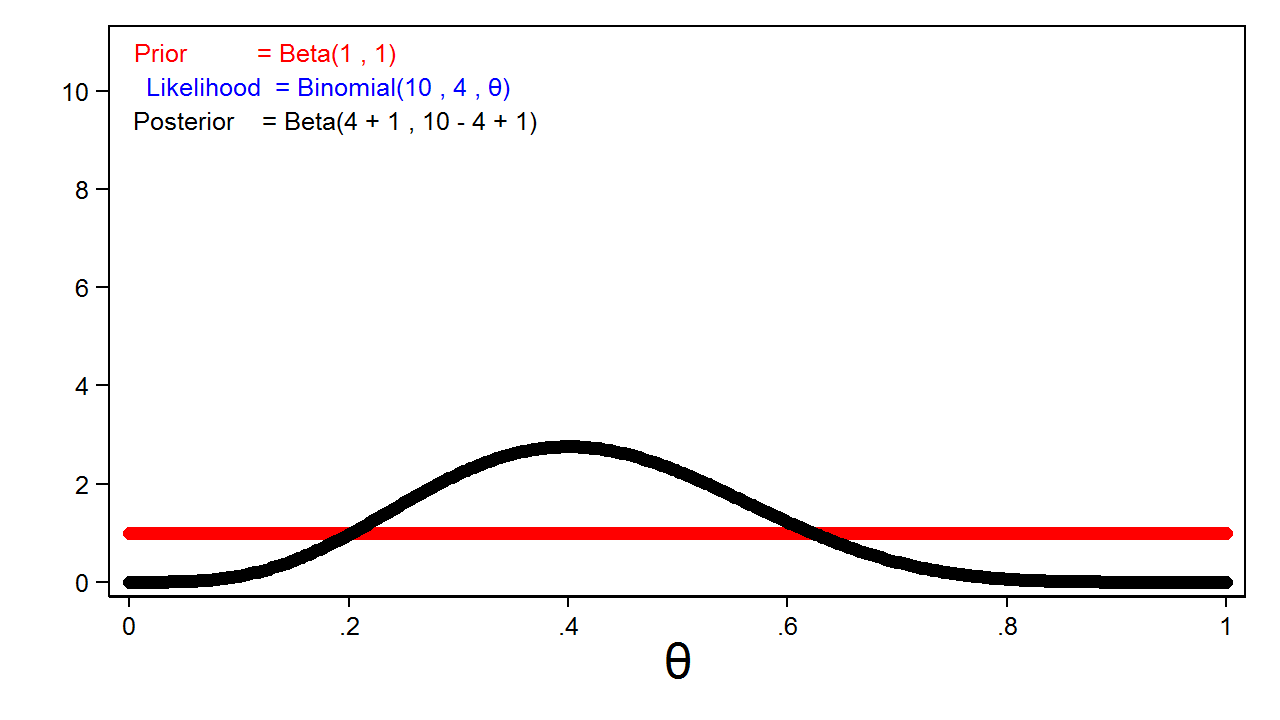
Đây là một đặc điểm quan trọng: phân phối hậu nghiệm thường sẽ tương đương với hàm hợp lý khi chúng ta sử dụng các phân phối tiên nghiệm hoàn toàn không có thông tin.
Trong thực tế, điều này có nghĩa là chúng ta có thể giảm độ lệch chuẩn của phân phối hậu nghiệm với kích thước mẫu nhỏ hơn nếu sử dụng các tiên nghiệm có thông tin tốt. Ngược lại, nếu dùng tiên nghiệm yếu, chúng ta cần mẫu lớn hơn để đạt được độ chính xác tương đương.
Sau khi tính được phân phối hậu nghiệm, chúng ta có thể xác định các giá trị như trung bình, trung vị, khoảng tin cậy 95%, xác suất theta nằm trong một khoảng nhất định và nhiều thống kê khác.
Thực hành với lệnh bayesmh trong stata
Hãy phân tích thí nghiệm tung đồng xu bằng lệnh bayesmh. Tôi sử dụng biến heads đã lưu ở trên, đặt tên tham số là {theta}, chỉ định hàm hợp lý Bernoulli và sử dụng phân phối tiên nghiệm beta(1,1).
1. bayesmh heads, likelihood(dbernoulli({theta})) prior({theta}, beta(1,1))
2Burn-in ...
3Simulation ...
4Model summary
5------------------------------------------------------------------------------
6Likelihood:
7 heads ~ bernoulli({theta})
8Prior:
9 {theta} ~ beta(1,1)
10------------------------------------------------------------------------------
11Bayesian Bernoulli model MCMC iterations = 12,500
12Random-walk Metropolis-Hastings sampling Burn-in = 2,500
13 MCMC sample size = 10,000
14 Number of obs = 10
15 Acceptance rate = .4454
16Log marginal likelihood = -7.7989401 Efficiency = .2391
17------------------------------------------------------------------------------
18 | Equal-tailed
19 | Mean Std. Dev. MCSE Median [95% Cred. Interval]
20-------------+----------------------------------------------------------------
21 theta | .4132299 .1370017 .002802 .4101121 .159595 .6818718
22------------------------------------------------------------------------------Kết quả cho thấy giá trị trung bình của phân phối hậu nghiệm là 0.41 và trung vị cũng là 0.41. Độ lệch chuẩn là 0.14 và khoảng tin cậy 95% nằm trong đoạn từ 0.16 đến 0.68. Chúng ta có thể diễn giải khoảng tin cậy này một cách rất trực quan: có 95% khả năng theta nằm trong khoảng này.
Chúng ta cũng có thể tính xác suất theta nằm trong một khoảng bất kỳ bằng lệnh bayestest interval. Ví dụ, kiểm tra xác suất theta nằm giữa 0.4 và 0.6.
1. bayestest interval {theta}, lower(0.4) upper(0.6)
2Interval tests MCMC sample size = 10,000
3 prob1 : 0.4 < {theta} < 0.6
4-----------------------------------------------
5 | Mean Std. Dev. MCSE
6-------------+---------------------------------
7 prob1 | .4265 0.49459 .0094961
8-----------------------------------------------Kết quả cho thấy có khoảng 43% khả năng giá trị thực của theta nằm trong khoảng từ 0.4 đến 0.6.
Tại sao nên sử dụng thống kê bayes?
Có nhiều lý do khiến phương pháp Bayes trở nên hấp dẫn. Điểm mạnh lớn nhất là khả năng kế thừa: phân phối hậu nghiệm từ một nghiên cứu trước đó có thể đóng vai trò là phân phối tiên nghiệm cho các nghiên cứu tiếp theo. Chẳng hạn, bạn có thể thực hiện một nghiên cứu thử nghiệm nhỏ với tiên nghiệm không có thông tin, sau đó dùng kết quả thu được làm tiên nghiệm cho nghiên cứu chính thức. Cách tiếp cận này giúp tăng độ chính xác cho mô hình cuối cùng một cách đáng kể.
✨ Thống kê Bayes không chỉ là một phương pháp tính toán, mà là một quy trình cập nhật tri thức liên tục. Nó cho phép kết hợp kinh nghiệm chuyên gia vào mô hình toán học và đưa ra những diễn giải xác suất trực quan, gần gũi với cách con người tư duy về sự không chắc chắn.
Hãy thử suy nghĩ: Nếu bạn có một phân phối tiên nghiệm rất mạnh (ví dụ một chuyên gia khẳng định chắc chắn theta bằng 0.5) nhưng dữ liệu thực tế thu được lại hoàn toàn trái ngược, phân phối hậu nghiệm sẽ bị kéo về phía nào nhiều hơn? Điều gì sẽ xảy ra nếu bạn tiếp tục tăng kích thước mẫu lên hàng nghìn lần?

