
Trong quá trình phân tích dữ liệu, việc trực quan hóa các dự báo từ mô hình luôn là một thách thức, đặc biệt là khi chúng ta đối mặt với các mô hình có nhiều biến tương tác. Mặc dù visreg hay ggeffects là những công cụ phổ biến, nhưng sự xuất hiện của modelbased trong hệ sinh thái easystats đã mang đến một hướng tiếp cận mới mẻ và mạnh mẽ hơn để xử lý các tương tác phức tạp trong mô hình hồi quy tổng quát.
Khởi đầu với hệ sinh thái easystats
Gói thư viện modelbased là một thành phần quan trọng của easystats, được thiết kế để đơn giản hóa việc phân tích và trình bày các mô hình thống kê. Để bắt đầu, chúng ta sẽ sử dụng dữ liệu thực tế về độ che phủ của san hô và sự phong phú của các loài cá để minh họa cách gói thư viện này hoạt động.
1library(ggplot2)
2library(dplyr)
3library(easystats)
4library(readr)
5dat_url <- "https://raw.githubusercontent.com/cbrown5/example-ecological-data/refs/heads/main/data/benthic-reefs-and-fish/fish-coral-cover-sites.csv"
6dat <- read_csv(dat_url) %>%
7 mutate(
8 cb_cover = cb_cover / n_pts,
9 soft_cover = soft_cover / n_pts
10 )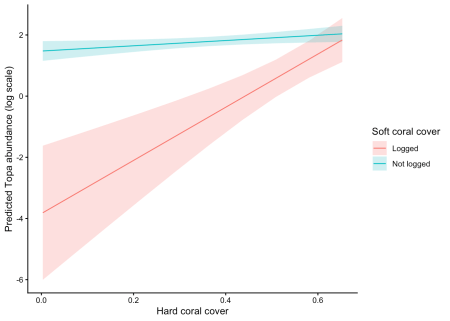
Xây dựng mô hình hồi quy Poisson
Chúng ta sẽ thiết lập một mô hình hồi quy Poisson để dự báo số lượng cá topa dựa trên độ che phủ của san hô cứng và trạng thái khai thác gỗ tại khu vực đó. Biến tương tác giữa độ che phủ san hô và trạng thái khai thác gỗ sẽ giúp chúng ta hiểu rõ hơn liệu tác động của san hô lên số lượng cá có thay đổi tùy theo môi trường bị ô nhiễm hay không.
1m1 <- glm(pres.topa ~ cb_cover * logged,
2 data = dat,
3 family = poisson)
4summary(m1)Kết quả từ mô hình cho thấy sự tương tác giữa các biến có ý nghĩa thống kê cao. Tuy nhiên, để thực sự hiểu được bản chất của tương tác này, việc quan sát các con số trong bảng hệ số là chưa đủ. Chúng ta cần trực quan hóa chúng.
Trực quan hóa các tác động tương tác
Sử dụng hàm estimate_means từ modelbased, chúng ta có thể dễ dàng tính toán các giá trị trung bình biên dự báo và vẽ đồ thị. Ở đây, chúng ta sẽ thực hiện việc tính toán trên thang đo liên kết của mô hình hồi quy Poisson.
1pr <- estimate_means(m1, by = c("cb_cover", "logged"),
2 estimate = "typical",
3 type = "link")
4plot(pr) +
5 labs(
6 x = "Hard coral cover",
7 y = "Predicted Topa abundance (log scale)",
8 color = "Soft coral cover",
9 fill = "Soft coral cover"
10 ) +
11 theme_classic()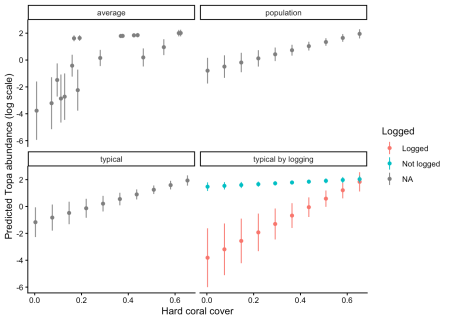
Các phương pháp ước lượng giá trị trung bình biên
Một điểm đặc biệt của modelbased là cung cấp nhiều tùy chọn khác nhau để ước lượng giá trị trung bình biên. Phương pháp mặc định là typical, tính toán tại giá trị trung bình của các biến số thực và trung bình theo tần suất của các biến phân loại. Ngoài ra, chúng ta còn có phương pháp average để tính trung bình dựa trên phân phối mẫu và population để tạo ra các tình huống giả định cho mọi tổ hợp biến số có thể xảy ra.
Dưới đây là mã nguồn để so sánh các phương pháp này:
1pr_typical <- estimate_means(m1, by = "cb_cover",
2 estimate = "typical",
3 type = "link")
4pr_average <- estimate_means(m1,
5 by = list(cb_cover = unique(dat$cb_cover)),
6 estimate = "average",
7 type = "link")
8pr_population <- estimate_means(m1, by = c("cb_cover"),
9 estimate = "population",
10 type = "link")
11pr_all <- bind_rows(
12 pr %>% mutate(method = "typical by logging"),
13 pr_typical %>% mutate(method = "typical"),
14 pr_average %>% mutate(method = "average"),
15 pr_population %>% mutate(method = "population")
16)
17ggplot(pr_all, aes(x = cb_cover, y = Mean, color = logged)) +
18 geom_point() +
19 geom_linerange(aes(ymin = CI_low, ymax = CI_high)) +
20 facet_wrap(~method) +
21 labs(
22 x = "Hard coral cover",
23 y = "Predicted Topa abundance (log scale)",
24 color = "Logged"
25 ) +
26 theme_classic()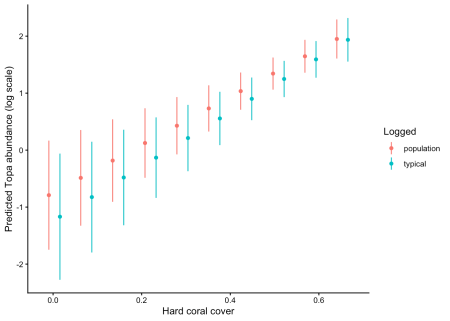
Sự khác biệt giữa các phương pháp ước lượng
Khi dữ liệu không cân bằng, ví dụ như số lượng điểm quan sát tại khu vực không khai thác gỗ nhiều hơn khu vực có khai thác gỗ, phương pháp typical sẽ cho ra kết quả khác biệt so với population. Phương pháp population và typical thường nằm giữa các dự báo có điều kiện vì chúng đại diện cho các kiểu trung bình hóa khác nhau trên các nhóm dữ liệu. Trong khi đó, phương pháp average có thể cho thấy các mô hình không nhất quán do nó phụ thuộc trực tiếp vào đặc điểm của các mẫu cụ thể.
Kiểm chứng với dữ liệu cân bằng
Để chứng minh rằng sự khác biệt giữa các phương pháp ước lượng chủ yếu do dữ liệu không cân bằng, chúng ta có thể thử nghiệm trên một tập dữ liệu đã được làm cho cân bằng bằng cách loại bỏ ngẫu nhiên một số quan sát.
1set.seed(707)
2irm <- sample(which(dat$logged == "Not logged"), 7)
3dat2 <- dat[-irm, ]
4m2 <- glm(pres.topa ~ cb_cover * logged,
5 data = dat2,
6 family = poisson)
7pr_typical2 <- estimate_means(m2, by = "cb_cover",
8 estimate = "typical",
9 type = "link")
10pr_population2 <- estimate_means(m2, by = c("cb_cover"),
11 estimate = "population",
12 type = "link")
13pr_all2 <- bind_rows(
14 pr_typical2 %>% mutate(method = "typical"),
15 pr_population2 %>% mutate(method = "population")
16)
17pd <- position_dodge(width = 0.02)
18ggplot(pr_all2, aes(x = cb_cover, y = Mean,
19 color = method)) +
20 geom_point(position = pd) +
21 geom_linerange(aes(ymin = CI_low, ymax = CI_high),
22 position = pd) +
23 labs(
24 x = "Hard coral cover",
25 y = "Predicted Topa abundance (log scale)",
26 color = "Logged"
27 ) +
28 theme_classic()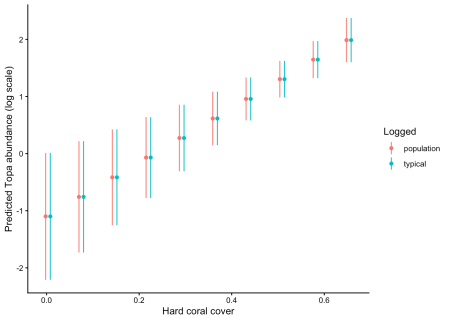
Kết quả cho thấy khi dữ liệu cân bằng, các dự báo từ phương pháp typical và population trở nên hoàn toàn trùng khớp. Điều này nhấn mạnh tầm quan trọng của việc hiểu rõ cấu trúc dữ liệu khi lựa chọn phương pháp trực quan hóa tương tác.
✨ Giá trị đắt giá: Việc nắm vững các tùy chọn ước lượng trong modelbased giúp nhà phân tích không chỉ vẽ ra những biểu đồ đẹp mắt mà còn phản ánh chính xác bản chất thống kê của dữ liệu, đặc biệt là khi xử lý các tập dữ liệu thực tế thường xuyên gặp tình trạng không cân bằng giữa các nhóm.
Câu hỏi tư duy: Trong trường hợp bạn đang xây dựng một mô hình dự báo để áp dụng cho một quần thể hoàn toàn mới với tỉ lệ các nhóm khác biệt so với mẫu hiện tại, bạn nên ưu tiên sử dụng phương pháp ước lượng nào trong modelbased để có cái nhìn khách quan nhất về các tác động biên? Vì sao?

