
Trong giới khoa học dữ liệu, cuộc tranh luận giữa việc sử dụng Python hay R chưa bao giờ kết thúc. Python sở hữu thế mạnh vượt trội về khả năng tích hợp hệ thống, xử lý học sâu và xây dựng ứng dụng thực tế. Trong khi đó, R lại là ông vua trong lĩnh vực phân tích thống kê chuyên sâu, dự báo chuỗi thời gian và sở hữu các gói thư viện được thiết kế tối ưu bởi cộng đồng các nhà thống kê học.
Thay vì phải đau đầu lựa chọn một trong hai ngôn ngữ, việc kết hợp sức mạnh của cả hai ngay trong một quy trình làm việc là giải pháp tối ưu nhất. Thư viện rtopy chính là cầu nối hiện đại giúp bạn thực hiện điều này một cách mượt mà. Bài viết này sẽ giới thiệu những cải tiến mới nhất của thư viện rtopy, giúp việc chuyển dịch và gọi mã nguồn R từ Python trở nên đơn giản hơn bao giờ hết.
Cài đặt các công cụ cần thiết
Để bắt đầu, bạn cần cài đặt thư viện rtopy trong môi trường Python và một số gói thư viện R phổ biến phục vụ cho việc tính toán thống kê và học máy.
Đầu tiên, chúng ta cài đặt các gói thư viện R cần thiết bằng cách sử dụng trình quản lý gói pak để tối ưu hóa tốc độ tải:
1install.packages("pak")
2pak::pak(c("e1071", "forecast", "randomForest"))
3library(jsonlite)Tiếp theo, tiến hành cài đặt rtopy trong môi trường Python của bạn:
1pip install rtopyKhám phá các tính năng của RBridge và call_r
Hai cải tiến quan trọng nhất trong phiên bản mới của rtopy tập trung vào lớp RBridge và hàm call_r.
Lớp RBridge hướng đến tính bền vững và liên tục của phiên làm việc. Nó cho phép bạn duy trì một phiên làm việc R chạy ngầm, giữ lại các biến số và môi trường đã khởi tạo để phục vụ cho các bước tính toán tiếp theo.
Trong khi đó, hàm call_r hướng đến sự tiện lợi và nhanh chóng. Hàm này rất phù hợp cho các tác vụ độc lập, nơi bạn chỉ cần truyền dữ liệu vào một hàm R, nhận kết quả trả về và đóng phiên làm việc ngay lập tức.
Các ví dụ ứng dụng thực tế với RBridge
Hãy cùng đi sâu vào các ví dụ thực tế dưới đây để thấy rtopy giải quyết các bài toán từ phân loại, hồi quy, phân tích chuỗi thời gian cho đến kiểm định giả thuyết thống kê một cách dễ dàng như thế nào.
Phân loại bằng thuật toán SVM với gói e1071
Gói e1071 của R cực kỳ nổi tiếng với các thuật toán phân loại thống kê. Dưới đây là cách chúng ta tạo dữ liệu mẫu bằng numpy trong Python, sau đó gửi sang R để huấn luyện mô hình SVM và nhận kết quả trả về dưới dạng dictionary của Python.
1import numpy as np
2from rtopy import RBridge
3# Khởi tạo dữ liệu huấn luyện ngẫu nhiên
4np.random.seed(42)
5n_samples = 100
6# Nhóm 0 tập trung quanh tọa độ (-1, -1)
7X0 = np.random.randn(n_samples // 2, 2) * 0.5 + np.array([-1, -1])
8# Nhóm 1 tập trung quanh tọa độ (1, 1)
9X1 = np.random.randn(n_samples // 2, 2) * 0.5 + np.array([1, 1])
10X_train = np.vstack([X0, X1])
11y_train = np.array([0] * (n_samples // 2) + [1] * (n_samples // 2))
12# Đoạn mã R thực hiện huấn luyện SVM và dự báo
13svm_code = """
14library(e1071)
15train_svm <- function(X, y, kernel_type = "radial") {
16 df <- data.frame(
17 x1 = X[, 1],
18 x2 = X[, 2],
19 y = as.factor(y)
20 )
21 model <- e1071::svm(y ~ x1 + x2, data = df, kernel = kernel_type, cost = 1)
22 predictions <- predict(model, df)
23 accuracy <- mean(predictions == df$y)
24 list(
25 predictions = as.numeric(as.character(predictions)),
26 accuracy = accuracy,
27 n_support = model$tot.nSV
28 )
29}
30"""
31# Gọi RBridge để thực thi hàm R
32rb = RBridge(verbose=True)
33result = rb.call(
34 svm_code,
35 "train_svm",
36 return_type="dict",
37 X=X_train,
38 y=y_train,
39 kernel_type="radial"
40)
41print(f"Độ chính xác huấn luyện: {result['accuracy']:.2%}")
42print(f"Số lượng vector hỗ trợ: {result['n_support']}")
43print(f"Dự báo mẫu: {result['predictions'][:10]}")Dự báo chuỗi thời gian với gói forecast
Dự báo chuỗi thời gian là thế mạnh tuyệt đối của R với thuật toán tự động tìm kiếm mô hình ARIMA tối ưu. Chúng ta có thể tận dụng điều này trực tiếp từ Python.
1# Tạo dữ liệu chuỗi thời gian giả lập
2time_series = np.sin(np.linspace(0, 4*np.pi, 50)) + np.random.randn(50) * 0.1
3ts_code = """
4library(forecast)
5forecast_ts <- function(x, h = 10) {
6 ts_data <- ts(x, frequency = 12)
7 fit <- auto.arima(ts_data, seasonal = FALSE)
8 fc <- forecast(fit, h = h)
9 list(
10 forecast_mean = as.numeric(fc$mean),
11 forecast_lower = as.numeric(fc$lower[, 2]), # Khoảng tin cậy 95% biên dưới
12 forecast_upper = as.numeric(fc$upper[, 2]), # Khoảng tin cậy 95% biên trên
13 model_aic = fit$aic,
14 model_order = paste0("ARIMA(",
15 paste(arimaorder(fit), collapse = ","),
16 ")")
17 )
18}
19"""
20result = rb.call(
21 ts_code,
22 "forecast_ts",
23 return_type="dict",
24 x=time_series.tolist(),
25 h=10
26)
27print(f"Mô hình được chọn: {result['model_order']}")
28print(f"Chỉ số AIC: {result['model_aic']:.2f}")
29print(f"Dự báo 5 bước tiếp theo: {np.array(result['forecast_mean'])[:5]}")Hồi quy Random Forest
Mô hình Random Forest trong R cung cấp các thông số đánh giá chi tiết về độ quan trọng của các đặc trưng một cách rất trực quan.
1# Tạo dữ liệu hồi quy
2np.random.seed(123)
3X = np.random.rand(200, 3) * 10
4y = 2*X[:, 0] + 3*X[:, 1] - X[:, 2] + np.random.randn(200) * 2
5rf_code = """
6library(randomForest)
7train_rf <- function(X, y, ntree = 500) {
8 df <- data.frame(
9 x1 = X[, 1],
10 x2 = X[, 2],
11 x3 = X[, 3],
12 y = y
13 )
14 rf_model <- randomForest(y ~ ., data = df, ntree = ntree, importance = TRUE)
15 predictions <- predict(rf_model, df)
16 r_squared <- 1 - sum((y - predictions)^2) / sum((y - mean(y))^2)
17 importance_scores <- importance(rf_model)[, 1]
18 list(
19 r_squared = r_squared,
20 mse = rf_model$mse[ntree],
21 predictions = predictions,
22 importance = importance_scores
23 )
24}
25"""
26result = rb.call(
27 rf_code,
28 "train_rf",
29 return_type="dict",
30 X=X,
31 y=y.tolist(),
32 ntree=500
33)
34print(f"Hệ số xác định R2: {result['r_squared']:.3f}")
35print(f"Sai số bình phương trung bình MSE: {result['mse']:.3f}")
36print(f"Độ quan trọng của các đặc trưng: {result['importance']}")Kiểm định giả thuyết thống kê chuyên sâu
R cung cấp các công cụ kiểm định thống kê chuẩn xác và nhanh chóng. Dưới đây là cách thực hiện đồng thời kiểm định t, kiểm định Wilcoxon và kiểm định Kolmogorov-Smirnov trên hai nhóm dữ liệu độc lập.
1group1 = np.random.normal(5, 2, 50)
2group2 = np.random.normal(6, 2, 50)
3stats_code = """
4perform_tests <- function(group1, group2) {
5 t_result <- t.test(group1, group2)
6 w_result <- wilcox.test(group1, group2)
7 ks_result <- ks.test(group1, group2)
8 list(
9 t_test = list(
10 statistic = t_result$statistic,
11 p_value = t_result$p.value,
12 conf_int = t_result$conf.int
13 ),
14 wilcox_test = list(
15 statistic = w_result$statistic,
16 p_value = w_result$p.value
17 ),
18 ks_test = list(
19 statistic = ks_result$statistic,
20 p_value = ks_result$p.value
21 ),
22 summary_stats = list(
23 group1_mean = mean(group1),
24 group2_mean = mean(group2),
25 group1_sd = sd(group1),
26 group2_sd = sd(group2)
27 )
28 )
29}
30"""
31result = rb.call(
32 stats_code,
33 "perform_tests",
34 return_type="dict",
35 group1=group1.tolist(),
36 group2=group2.tolist()
37)
38print(f"Trung bình nhóm 1: {result['summary_stats']['group1_mean']:.2f}")
39print(f"Trung bình nhóm 2: {result['summary_stats']['group2_mean']:.2f}")
40print(f"Kiểm định t có p-value: {result['t_test']['p_value']:.4f}")
41print(f"Kiểm định Wilcoxon có p-value: {result['wilcox_test']['p_value']:.4f}")Xử lý dữ liệu bảng với dplyr
Thư viện dplyr của R nổi tiếng với cú pháp xử lý dữ liệu dạng đường ống cực kỳ tường minh. Chúng ta có thể chuyển trực tiếp một data frame từ thư viện pandas của Python sang R, xử lý bằng dplyr rồi nhận lại kết quả là một pandas data frame mới.
1import pandas as pd
2data = pd.DataFrame({
3 'id': range(1, 101),
4 'group': np.random.choice(['A', 'B', 'C'], 100),
5 'value': np.random.randn(100) * 10 + 50,
6 'score': np.random.randint(1, 101, 100)
7})
8dplyr_code = """
9library(dplyr)
10process_data <- function(df) {
11 data <- as.data.frame(df)
12 result <- data %>%
13 filter(score > 50) %>%
14 group_by(group) %>%
15 summarise(
16 n = n(),
17 mean_value = mean(value),
18 median_score = median(score),
19 sd_value = sd(value)
20 ) %>%
21 arrange(desc(mean_value))
22 as.list(result)
23}
24"""
25result = rb.call(
26 dplyr_code,
27 "process_data",
28 return_type="pandas",
29 df=data
30)
31print("Kết quả thống kê nhóm sau khi xử lý bằng dplyr:")
32print(result)Phân cụm dữ liệu với gói cluster và trực quan hóa
Để hoàn thành chu trình làm việc, chúng ta sẽ thực hiện phân cụm K-means và phân cụm phân cấp trên R, sau đó chuyển kết quả phân cụm về Python để trực quan hóa bằng các thư viện đồ họa mạnh mẽ là matplotlib và seaborn.
1# Tạo dữ liệu phân cụm giả lập
2np.random.seed(42)
3cluster_data = np.vstack([
4 np.random.randn(30, 2) * 0.5 + np.array([0, 0]),
5 np.random.randn(30, 2) * 0.5 + np.array([3, 3]),
6 np.random.randn(30, 2) * 0.5 + np.array([0, 3])
7])
8cluster_code = """
9library(cluster)
10perform_clustering <- function(X, k = 3) {
11 data_matrix <- as.matrix(X)
12 # Phân cụm K-means
13 kmeans_result <- kmeans(data_matrix, centers = k, nstart = 25)
14 # Phân cụm phân cấp
15 dist_matrix <- dist(data_matrix)
16 hc <- hclust(dist_matrix, method = "ward.D2")
17 hc_clusters <- cutree(hc, k = k)
18 # Phân tích Silhouette để đánh giá chất lượng phân cụm
19 sil <- silhouette(kmeans_result$cluster, dist_matrix)
20 avg_silhouette <- mean(sil[, 3])
21 list(
22 kmeans_clusters = kmeans_result$cluster,
23 kmeans_centers = kmeans_result$centers,
24 kmeans_withinss = kmeans_result$tot.withinss,
25 hc_clusters = hc_clusters,
26 silhouette_score = avg_silhouette
27 )
28}
29"""
30result = rb.call(
31 cluster_code,
32 "perform_clustering",
33 return_type="dict",
34 X=cluster_data,
35 k=3
36)
37print(f"Tổng bình phương khoảng cách trong cụm của K-means: {result['kmeans_withinss']:.2f}")
38print(f"Điểm số Silhouette trung bình: {result['silhouette_score']:.3f}")Sau khi nhận được nhãn phân cụm và tọa độ tâm cụm từ thuật toán chạy trên R, chúng ta tiến hành vẽ biểu đồ phân tán trong Python:
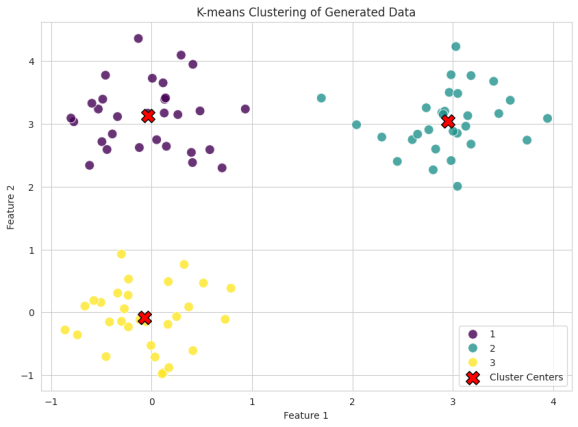
1import matplotlib.pyplot as plt
2import seaborn as sns
3sns.set_style("whitegrid")
4plt.figure(figsize=(10, 7))
5# Vẽ các điểm dữ liệu theo màu sắc của từng cụm
6sns.scatterplot(
7 x=cluster_data[:, 0],
8 y=cluster_data[:, 1],
9 hue=result['kmeans_clusters'],
10 palette='viridis',
11 s=100,
12 alpha=0.8,
13 legend='full'
14)
15# Vẽ vị trí các tâm cụm được tính toán từ thuật toán K-means của R
16centers = np.array(result['kmeans_centers'])
17plt.scatter(
18 centers[:, 0],
19 centers[:, 1],
20 marker='X',
21 s=200,
22 color='red',
23 edgecolors='black',
24 label='Tâm cụm'
25)
26plt.title('Biểu đồ phân cụm K-means kết hợp giữa R và Python')
27plt.xlabel('Đặc trưng 1')
28plt.ylabel('Đặc trưng 2')
29plt.legend()
30plt.grid(True)
31plt.show()✨ Giá trị đắt giá: Thư viện rtopy phá bỏ ranh giới ngăn cách giữa hai hệ sinh thái ngôn ngữ phổ biến nhất trong khoa học dữ liệu. Bằng cách cho phép chạy song song và truyền nhận dữ liệu trực tiếp giữa R và Python mà không cần ghi file trung gian, bạn có thể xây dựng các mô hình sản xuất ứng dụng bằng Python nhưng vẫn tận dụng được các thuật toán thống kê chuẩn mực nhất từ R.
Bài tập thực hành và câu hỏi tư duy
Hãy thử áp dụng những kiến thức trên để giải quyết bài toán sau:
Sử dụng bộ dữ liệu Boston có sẵn trong gói thư viện MASS của R để xây dựng một mô hình SVM phân loại nhà giá cao dựa trên các đặc trưng đô thị. Hãy viết một đoạn mã Python sử dụng rtopy để huấn luyện mô hình này và trả về ma trận nhầm lẫn của kết quả dự báo.
Gợi ý khung mã nguồn thực hiện bài tập:
1# Hãy điền mã nguồn R để lấy dữ liệu Boston và phân loại bằng SVM
2svm_boston_code = """
3library(MASS)
4library(e1071)
5train_boston_svm <- function(kernel_type = "radial", cost = 1) {
6 data(Boston)
7 # Xác định mục tiêu phân loại nhị phân: giá nhà cao hơn mức trung vị
8 Boston$high_medv <- as.factor(ifelse(Boston$medv > median(Boston$medv), 1, 0))
9 # Huấn luyện mô hình SVM và dự báo
10 # Hãy tự viết tiếp phần còn lại để trả về độ chính xác và ma trận nhầm lẫn
11}
12"""
13# Thực hiện cuộc gọi qua RBridge và in kết quả ra màn hình
