
Chúng ta đã làm quen với các khái niệm cơ bản về dược động học và dược lực học. Hôm nay, chúng ta sẽ ứng dụng những kiến thức đó vào bộ đôi kháng sinh piperacillin/tazobactam và vi khuẩn Pseudomonas. Gần đây, một tuyên bố của FDA vào tháng hai năm 2024 đã chỉ ra rằng đối với điểm gãy phụ thuộc liều nhạy cảm là 16 mcg/mL, chúng ta nên sử dụng liều 4.5g mỗi sáu giờ truyền kéo dài trong ba giờ. Lý do là vì phác đồ chuẩn 4.5g truyền tĩnh mạch mỗi sáu giờ trong vòng nửa giờ không đủ để đạt PTA lớn hơn 90 phần trăm. Tuyên bố này cũng đề cập đến một hạn chế khi sử dụng chỉ số thời gian nồng độ thuốc tự do lớn hơn mic đạt 50 phần trăm để tính toán PTA, một chỉ số chưa được kiểm chứng đầy đủ cho Pseudomonas. Đây là cơ hội tuyệt vời để chúng ta tự mình kiểm chứng điều này thông qua dữ liệu.
Xây dựng mô hình dược động học quần thể
Đầu tiên, chúng ta cần thu thập các thông số popPK, xây dựng mô hình, thực hiện mô phỏng và trực quan hóa PTA. Chúng ta sẽ dựa trên một phân tích gộp về dược động học cho piperacillin/tazobactam trên nhiều nhóm bệnh nhân khác nhau, từ trẻ sinh non đến người cao tuổi. Mô hình gộp này phức tạp và tinh vi hơn rất nhiều so với các mô hình đơn lẻ.
Dưới đây là đoạn mã khởi tạo mô hình cơ bản sử dụng ngôn ngữ R và gói mrgsolve.
1library(mrgsolve)
2library(tidyverse)
3mod <- mcode(model = "piptazo", code = '
4$PARAM
5theta_V1_PIP = 10.4,
6theta_CL_PIP = 10.6,
7theta_V2_PIP = 11.6,
8theta_Q2_PIP = 15.2,
9theta_V1_TAZ = 10.5,
10theta_CL_TAZ = 9.58,
11theta_V2_TAZ = 13.7,
12theta_Q2_TAZ = 16.8,
13MAT50_wk = 54.2,
14gamma1 = 3.35,
15DEC50_PIP_yr = 89.1,
16DEC50_TAZ_yr = 61.6,
17gamma2 = 1.92,
18theta_SCR = 0.346,
19fUNB_PIP = 0.645,
20fDBS_PIP = 0.368,
21fDBS_TAZ = 0.448,
22theta_CL_Sime = 1.0,
23theta_V2_Sime = 1.0,
24TBW = 70,
25PMA_yr = 35,
26SCR = 0.83
27$CMT CENT_PIP PERI_PIP CENT_TAZ PERI_TAZ
28$MAIN
29double FSIZE = TBW / 70.0;
30double PMA_wk = PMA_yr * 52.1775;
31double FMAT = pow(PMA_wk, gamma1) /
32 (pow(PMA_wk, gamma1) + pow(MAT50_wk, gamma1));
33double FDEC_PIP = 1.0 - pow(PMA_yr, gamma2) /
34 (pow(PMA_yr, gamma2) + pow(DEC50_PIP_yr, gamma2));
35double FDEC_TAZ = 1.0 - pow(PMA_yr, gamma2) /
36 (pow(PMA_yr, gamma2) + pow(DEC50_TAZ_yr, gamma2));
37double SCR_std = exp(1.42 - (1.17 + 0.203 * log(PMA_yr / 100.0)) /
38 sqrt(PMA_yr / 100.0));
39double FSCR = exp(-theta_SCR * (SCR - SCR_std));
40double V1_PIP = theta_V1_PIP * FSIZE * exp(ETA(1));
41double CL_PIP = theta_CL_PIP * pow(FSIZE, 0.75) * FMAT * FDEC_PIP * FSCR
42 * theta_CL_Sime * exp(ETA(2));
43double V2_PIP = theta_V2_PIP * FSIZE * theta_V2_Sime * exp(ETA(4));
44double Q2_PIP = theta_Q2_PIP *
45 pow(V2_PIP / (theta_V2_PIP * FSIZE * theta_V2_Sime), 0.75) *
46 exp(ETA(5));
47double V1_TAZ = theta_V1_TAZ * FSIZE * exp(ETA(1));
48double CL_TAZ = theta_CL_TAZ * pow(FSIZE, 0.75) * FMAT * FDEC_TAZ * FSCR
49 * exp(ETA(3));
50double V2_TAZ = theta_V2_TAZ * FSIZE * exp(ETA(4));
51double Q2_TAZ = theta_Q2_TAZ *
52 pow(V2_TAZ / (theta_V2_TAZ * FSIZE), 0.75) *
53 exp(ETA(5));
54$OMEGA
550.1537
560.1598
570.1480
580.5218
590.3598
60$SIGMA
610.0912
620.0216
630.0812
640.0000
65$ODE
66dxdt_CENT_PIP = -(CL_PIP / V1_PIP) * CENT_PIP
67 - (Q2_PIP / V1_PIP) * CENT_PIP
68 + (Q2_PIP / V2_PIP) * PERI_PIP;
69dxdt_PERI_PIP = (Q2_PIP / V1_PIP) * CENT_PIP
70 - (Q2_PIP / V2_PIP) * PERI_PIP;
71dxdt_CENT_TAZ = -(CL_TAZ / V1_TAZ) * CENT_TAZ
72 - (Q2_TAZ / V1_TAZ) * CENT_TAZ
73 + (Q2_TAZ / V2_TAZ) * PERI_TAZ;
74dxdt_PERI_TAZ = (Q2_TAZ / V1_TAZ) * CENT_TAZ
75 - (Q2_TAZ / V2_TAZ) * PERI_TAZ;
76$TABLE
77double Cp_PIP_total = (CENT_PIP / V1_PIP) * (1.0 + EPS(1)) + EPS(2);
78double Cp_PIP_unbound = fUNB_PIP * (CENT_PIP / V1_PIP);
79double Cp_TAZ_total = (CENT_TAZ / V1_TAZ) * (1.0 + EPS(3)) + EPS(4);
80double Cp_PIP_DBS = fDBS_PIP * (CENT_PIP / V1_PIP);
81double Cp_TAZ_DBS = fDBS_TAZ * (CENT_TAZ / V1_TAZ);
82$CAPTURE
83Cp_PIP_total Cp_PIP_unbound Cp_TAZ_total
84Cp_PIP_DBS Cp_TAZ_DBS
85V1_PIP CL_PIP V2_PIP Q2_PIP
86V1_TAZ CL_TAZ V2_TAZ Q2_TAZ
87FSIZE FMAT FDEC_PIP FDEC_TAZ FSCR SCR_std
88')Mô hình trên định nghĩa rõ các thông số cố định đại diện cho một người trưởng thành chuẩn nặng 70kg, 35 tuổi và nồng độ creatinine huyết thanh 0.83 mg/dL. Các biến số về thể trọng, tuổi kinh nguyệt và creatinine huyết thanh được tính toán chi tiết. Hệ phương trình vi phân mô tả sự thay đổi lượng thuốc trong các khoang trung tâm và ngoại vi theo thời gian.
Tuy nhiên, để tối ưu cho việc mô phỏng chuyên sâu nồng độ piperacillin tự do, chúng ta có thể tinh gọn lại mô hình. Nồng độ tự do mới là yếu tố quyết định giá trị MIC, do đó không cần thiết phải đưa các sai số tỷ lệ hay sai số cộng gộp vào nếu chúng ta không ước lượng phương sai của kết quả xét nghiệm.
1mod <- mcode(model = "piptazo_ken", code = '
2$PARAM
3theta_v1_pip = 10.4,
4tbw = 70,
5theta_cl_pip = 10.6,
6pma_year = 35,
7gamma1 = 3.35,
8gamma2 = 1.92,
9scr = 0.82,
10theta_scr = 0.346,
11dec50_pip = 89.1,
12theta_cl_sime = 1,
13theta_v2_sime = 1,
14funb_pip = 0.645,
15fdbs_pip = 1,
16theta_v2_pip = 11.6,
17theta_q2_pip = 15.2,
18mat50 = 54.2
19$CMT CENT_PIP PERI_PIP
20$MAIN
21double fsize = tbw / 70;
22double pma_week = pma_year * 52.17;
23double fmat = pow(pma_week,gamma1) / (pow(pma_week,gamma1) + pow(mat50,gamma1));
24double fdec_pip = 1 - (pow(pma_year, gamma2) / (pow(pma_year, gamma2) + pow(dec50_pip, gamma2)));
25double scrstd = exp(1.42 - (1.17 + 0.203 * log(pma_year / 100.0)) / sqrt(pma_year / 100.0));
26double fscr = exp(-theta_scr*(scr-scrstd));
27double v1_pip = theta_v1_pip * fsize * exp(ETA(1));
28double cl_pip = theta_cl_pip * pow(fsize, 0.75) * fmat * fdec_pip * fscr * theta_cl_sime * exp(ETA(2));
29double v2_pip = theta_v2_pip * fsize * theta_v2_sime * exp(ETA(4));
30double q2_pip = theta_q2_pip * pow(v2_pip/theta_v2_pip, 0.75) * exp(ETA(5));
31$OMEGA
320.1667645
330.1711123
340.1589037
350.547726
360.3579094
37$ODE
38dxdt_CENT_PIP = -(cl_pip/v1_pip)*CENT_PIP - (q2_pip/v1_pip)*CENT_PIP + (q2_pip/v2_pip)*PERI_PIP;
39dxdt_PERI_PIP = -(q2_pip/v2_pip)*PERI_PIP + (q2_pip/v1_pip)*CENT_PIP;
40$TABLE
41double free_pip = (CENT_PIP/v1_pip) * funb_pip;
42$CAPTURE
43free_pip')Đánh giá xác suất đạt mục tiêu trên các nhóm bệnh nhân
Nhóm bệnh nhân tiêu chuẩn
Hãy xem xét một quần thể bệnh nhân không nằm phòng chăm sóc tích cực, không bị sốt giảm bạch cầu hạt, có cân nặng 90kg, 35 tuổi và nồng độ creatinine là 0.83.
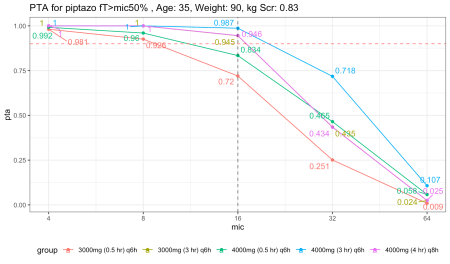
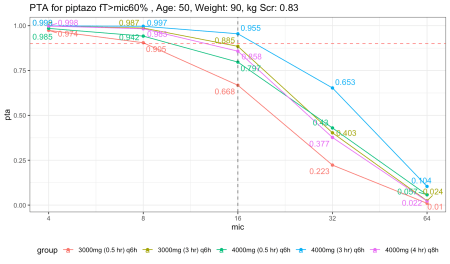
Để dễ quan sát, một đường đứt nét ngang màu đỏ được dùng để biểu thị ngưỡng PTA 90 phần trăm, cùng với một đường đứt nét dọc màu đen chỉ ra MIC bằng 16, mức cao nhất để vi khuẩn vẫn được coi là nhạy cảm với piperacillin/tazobactam. Kết quả cho thấy cả hai phương án truyền 30 phút đều có PTA dưới 90 phần trăm, bất kể liều lượng.
Sự thay đổi theo độ tuổi và chức năng thận
Nếu tăng nhẹ độ tuổi và mức creatinine để phản ánh trung bình nhóm người bệnh thường xuyên cần dùng loại kháng sinh này, ví dụ như tuổi 50 và creatinine bằng 1, kết quả sẽ có sự dịch chuyển.
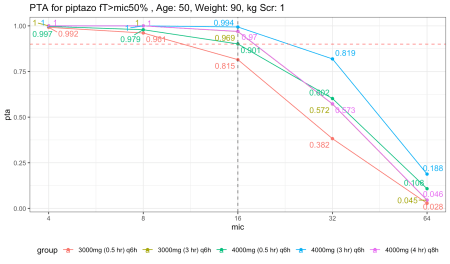
Với thông số này, phương pháp truyền ngắt quãng có vẻ chấp nhận được miễn là giữ ở mức liều 4g. Tuy nhiên, điều trị kháng sinh hiếm khi dừng lại ở mức trung bình.
Quần thể chăm sóc tích cực và sốt giảm bạch cầu hạt
Tiếp tục đánh giá trên nhóm bệnh nhân chăm sóc tích cực có dấu hiệu nhiễm trùng huyết giai đoạn sớm.
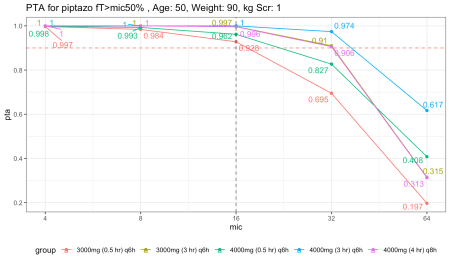
Kết quả trên nhóm chăm sóc tích cực có vẻ khá khác thường. Dựa trên tính toán, điều này có thể bắt nguồn từ việc thiết lập tỷ lệ thuốc tự do bằng 1, khiến nồng độ thuốc tự do tăng cao. Nhưng trong thực tế sinh lý, điều này cũng đồng nghĩa với việc độ thanh thải diễn ra nhanh hơn và mạnh hơn. Do cấu trúc mã lệnh hiện tại chưa bao hàm trọn vẹn sự bù trừ này, chúng ta cần diễn giải kết quả một cách cẩn trọng.
Tình hình trở nên vô cùng căng thẳng khi mô phỏng trên nhóm bệnh nhân sốt giảm bạch cầu hạt.
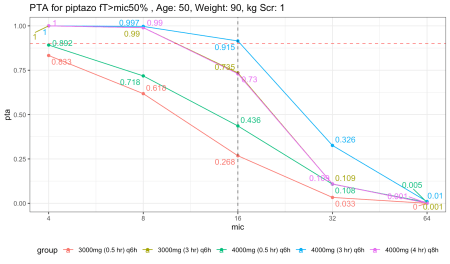
Sự sụt giảm diễn ra rất mạnh. Ngay cả khi áp dụng phương pháp truyền kéo dài, ngoại trừ liều 4g truyền trong 3 giờ mỗi sáu tiếng, các phác đồ khác chỉ vừa vặn chạm mốc PTA 90 phần trăm.
Thay đổi ngưỡng thời gian nồng độ vượt mức phân lập
Nhiều tài liệu y khoa chỉ ra rằng ngưỡng thời gian nồng độ thuốc tự do lớn hơn mic đạt 50 phần trăm là không đủ để tiêu diệt Pseudomonas, mặc dù chưa có sự đồng thuận tuyệt đối về con số tối ưu. Một số nghiên cứu đề xuất mức 70 phần trăm hoặc thậm chí 100 phần trăm.
Khi áp dụng ngưỡng thời gian nồng độ thuốc tự do lớn hơn mic đạt 100 phần trăm, chỉ số PTA sụt giảm đáng kể. Một số chuyên gia thậm chí còn khuyến cáo quần thể bệnh nhân nặng có thể cần duy trì thời gian nồng độ thuốc lớn hơn bốn lần mic đạt 100 phần trăm để có kết quả lâm sàng tốt nhất. Mô phỏng thử nghiệm với chỉ số khắt khe này cho thấy một sự sụt giảm cực kỳ nghiêm trọng, phù hợp với các số liệu từ tài liệu gốc khi đánh giá hiệu quả của phương pháp truyền kéo dài.
Phân tích gen kháng thuốc trên cơ sở dữ liệu NCBI
Một câu hỏi thú vị được đặt ra là tại sao chúng ta lại cần tazobactam khi bản thân piperacillin đã có hoạt tính chống lại Pseudomonas? Để trả lời, chúng ta tiến hành trích xuất toàn bộ dữ liệu vi khuẩn Pseudomonas nhạy cảm với piperacillin/tazobactam và kiểm tra các gen mã hóa men beta-lactamase thông qua đối sánh trực tiếp.
Chúng ta tìm kiếm các alen thuộc nhóm kháng thuốc phổ biến như blaTEM, blaSHV, blaCTX-M, và đặc biệt là nhóm blaOXA. Từ 212 mẫu Pseudomonas nhạy cảm với piperacillin/tazobactam, có 124 mẫu có sẵn bản gen hoàn chỉnh. Trong số 124 mẫu này, khoảng 46 phần trăm chứa gen blaOXA-2. Điều này chứng tỏ nếu không có tazobactam đóng vai trò chất ức chế, piperacillin có khả năng cao sẽ bị thủy phân và mất tác dụng hoàn toàn.
✨ Giá trị đắt giá: Việc kết hợp mô hình popPK với dữ liệu gen kháng thuốc cho thấy sức mạnh tuyệt vời của khoa học dữ liệu trong y học. Nó không chỉ giải thích bằng toán học lý do FDA thay đổi hướng dẫn truyền kháng sinh, mà còn chứng minh bằng dữ liệu thực tế tại sao một số phác đồ phối hợp chất ức chế men lại mang tính sống còn đối với bệnh nhân suy giảm miễn dịch.
Câu hỏi tư duy: Nếu nồng độ albumin máu của bệnh nhân giảm mạnh trong giai đoạn sốc nhiễm khuẩn, điều này sẽ tác động như thế nào đến tỷ lệ phần trăm thuốc tự do và bạn sẽ điều chỉnh hàm số thanh thải trong mô hình mrgsolve ra sao để phản ánh đúng hiện tượng này?

