Machine learning, deep learning và trí tuệ nhân tạo là tập hợp các thuật toán dùng để nhận diện các mẫu trong dữ liệu. Các thuật toán này thường có tên gọi khá đặc biệt như random forests, neural networks hay spectral clustering. Bài viết này trình bày cách sử dụng một trong những thuật toán phổ biến mang tên Support Vector Machines hay còn được gọi tắt là SVM. Mục tiêu là ứng dụng mô hình SVM để phân biệt những người có khả năng mắc bệnh tiểu đường và những người không mắc bệnh thông qua hai biến số là tuổi và mức HbA1c. Tuổi được tính bằng năm, còn HbA1c là chỉ số xét nghiệm máu đo lường mức độ kiểm soát đường huyết. Mô hình SVM sẽ dự đoán rằng những người lớn tuổi với mức HbA1c cao có nguy cơ mắc bệnh tiểu đường cao hơn, trong khi những người trẻ tuổi với mức HbA1c thấp ít có nguy cơ mắc bệnh hơn.
Tải, gộp và làm sạch dữ liệu bằng Stata
Dữ liệu được sử dụng lấy từ Khảo sát Kiểm tra Sức khỏe và Dinh dưỡng Quốc gia Hoa Kỳ. Cụ thể, biến số tuổi trích xuất từ tập dữ liệu nhân khẩu học, chỉ số HbA1c từ dữ liệu hemoglobin và trạng thái bệnh từ dữ liệu tiểu đường. Quá trình bắt đầu bằng việc tải các tệp gốc từ trang web, lưu thành các tập dữ liệu Stata cục bộ và tiến hành gộp chúng lại với nhau. Sau khi gộp, các biến số sẽ được đổi tên và mã hóa lại cho đồng nhất. Những quan sát có giá trị bị khuyết sẽ được loại bỏ hoàn toàn để đảm bảo chất lượng cho bước huấn luyện mô hình.
1import sasxport5 "https://wwwn.cdc.gov/Nchs/Nhanes/2015-2016/DEMO_I.XPT", clear
2save age.dta, replace
3import sasxport5 "https://wwwn.cdc.gov/Nchs/Nhanes/2015-2016/GHB_I.XPT", clear
4save glucose.dta, replace
5import sasxport5 "https://wwwn.cdc.gov/Nchs/Nhanes/2015-2016/DIQ_I.XPT", clear
6save diabetes, replace
7merge 1:1 seqn using "glucose.dta"
8drop _merge
9merge 1:1 seqn using "age.dta"
10rename ridageyr age
11rename lbxgh HbA1c
12rename diq010 diabetes
13recode diabetes (1 = 1) (2/3 = 0) (9=.)
14keep diabetes age HbA1c
15drop if missing(diabetes, age, HbA1c)
16save diabetes, replace
17erase age.dta
18erase glucose.dtaMở và trực quan hóa dữ liệu gốc bằng Python
Sau khi dữ liệu được làm sạch bằng Stata, bước tiếp theo là nạp tập dữ liệu này vào một data frame thông qua thư viện pandas. Phương thức đọc dữ liệu được cấu hình để nhận diện các biến số phân loại dưới dạng số học thay vì chuyển đổi chúng thành nhãn văn bản, đồng thời duy trì nguyên vẹn kiểu dữ liệu gốc. Trong thuật ngữ máy học, biến số tuổi và HbA1c được nhóm vào một ma trận tính năng độc lập, trong khi trạng thái bệnh tiểu đường đóng vai trò là biến số mục tiêu phụ thuộc.
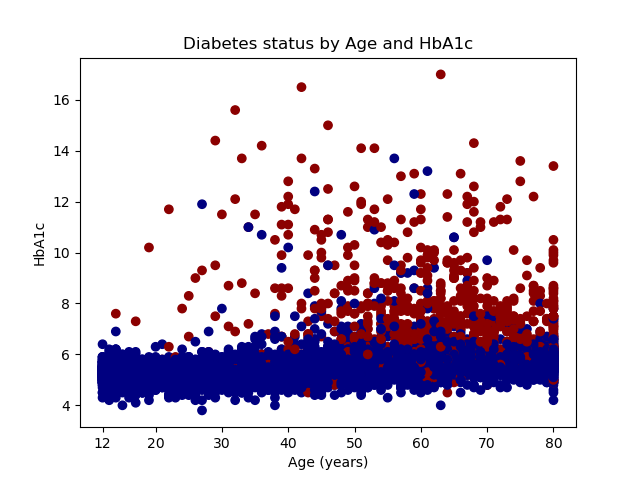
Biểu đồ phân tán được tạo ra bằng matplotlib sẽ ánh xạ biến số tuổi lên trục hoành và biến số HbA1c lên trục tung. Điểm dữ liệu của những người không mắc bệnh được biểu diễn bằng màu xanh dương, trong khi những người mắc bệnh được hiển thị bằng màu đỏ sẫm.
1import pandas as pd
2import matplotlib.pyplot as plt
3import matplotlib.colors as mcolors
4data = pd.read_stata('diabetes.dta',
5convert_categoricals=False,
6preserve_dtypes=True,
7convert_missing=False)
8X = data[['age','HbA1c']]
9y = data['diabetes']
10plt.scatter(X['age'], X['HbA1c'],
11c=y,
12cmap = mcolors.ListedColormap(["navy", "darkred"]))
13plt.xlabel('Age (years)')
14plt.ylabel('HbA1c')
15plt.xticks((12,20,30,40,50,60,70,80))
16plt.yticks((4,6,8,10,12,14,16))
17plt.title('Diabetes status by Age and HbA1c')
18plt.savefig("scatterplot.png")Phân chia dữ liệu và tìm kiếm tham số tối ưu
Một nguyên tắc cốt lõi trong xây dựng mô hình là phân chia tập dữ liệu hiện có thành tập huấn luyện và tập kiểm tra. Việc sử dụng sáu mươi phần trăm dữ liệu để huấn luyện và giữ lại bốn mươi phần trăm để kiểm tra giúp ngăn chặn hiện tượng quá khớp, đảm bảo mô hình có khả năng tổng quát hóa trên các tập dữ liệu mới.
Sau khi chia dữ liệu, quá trình thiết lập mô hình SVC bắt đầu. Để chọn ra các tham số tối ưu cho hàm hạt nhân đa thức, phương pháp tìm kiếm lưới kết hợp với kiểm chứng chéo mười thư mục được áp dụng. Kỹ thuật này tự động thử nghiệm nhiều tổ hợp tham số khác nhau, chia nhỏ tập huấn luyện để đánh giá chéo và tính toán điểm chính xác trung bình. Kết quả tìm kiếm chỉ ra rằng mô hình đạt độ khớp hoàn hảo nhất khi tham số điều chuẩn bằng ba và bậc của đa thức cũng bằng ba.
1from sklearn.model_selection import train_test_split
2from sklearn import svm
3from sklearn.model_selection import cross_val_score
4from sklearn.model_selection import GridSearchCV
5X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,
6random_state=0)
7model = svm.SVC(kernel='poly')
8parameters = {'degree':[1,2,3], 'C':[1,2,3]}
9poly_svc = GridSearchCV(model,
10parameters,
11cv=10,
12scoring='accuracy').fit(X_train, y_train)
13poly_svc.fit(X_train,y_train)
14print(poly_svc.best_params_)Đánh giá mô hình và vẽ đường ranh giới quyết định
Sử dụng tập tham số tối ưu vừa tìm được, mô hình SVM chính thức được huấn luyện và đưa vào thử nghiệm trên tập dữ liệu kiểm tra. Kết quả trả về cho thấy bộ phân loại đạt độ chính xác lên đến chín mươi ba phần trăm trong việc dự đoán trạng thái mắc bệnh tiểu đường.
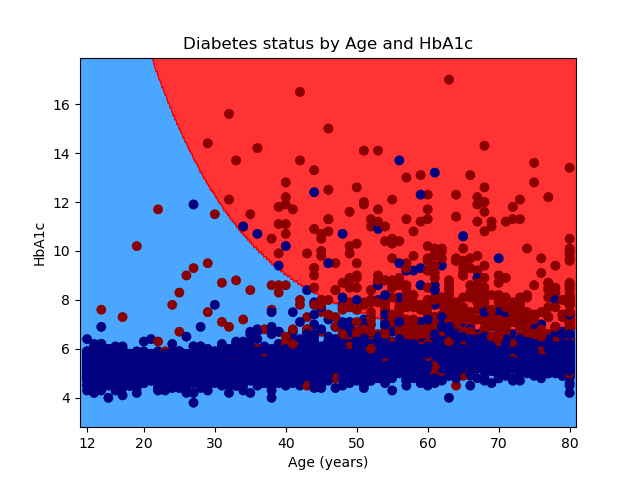
Để cung cấp cái nhìn trực quan về cách mô hình hoạt động, một biểu đồ đường viền được xây dựng dựa trên lưới tọa độ hai chiều. Phương thức dự đoán quét qua từng điểm trên không gian lưới và phân loại chúng vào vùng nguy cơ hoặc vùng an toàn. Các điểm dữ liệu gốc sau đó được phủ lên trên ranh giới quyết định này, minh họa rõ ràng cách thuật toán phân chia không gian không tuyến tính thành các khu vực phân loại rành mạch.
1import numpy as np
2poly_svc = svm.SVC(kernel='poly', degree=3, C=3).fit(X_train, y_train)
3scores = cross_val_score(poly_svc, X_test, y_test, cv=10, scoring='accuracy')
4h = 0.1
5x_min, x_max = X['age'].min() - 1, X['age'].max() + 1
6y_min, y_max = X['HbA1c'].min() - 1, X['HbA1c'].max() + 1
7xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
8np.arange(y_min, y_max, h))
9Z = poly_svc.predict(np.c_[xx.ravel(), yy.ravel()])
10Z = Z.reshape(xx.shape)
11plt.contourf(xx, yy, Z,
12cmap = mcolors.ListedColormap(["dodgerblue", "red"]),
13alpha=0.8)
14plt.scatter(X['age'], X['HbA1c'],
15c=y,
16cmap = mcolors.ListedColormap(["navy", "darkred"]))
17plt.xlabel('Age (years)')
18plt.ylabel('HbA1c')
19plt.xlim(xx.min(), xx.max())
20plt.ylim(yy.min(), yy.max())
21plt.xticks((12,20,30,40,50,60,70,80))
22plt.yticks((4,6,8,10,12,14,16))
23plt.title('Diabetes status by Age and HbA1c')
24plt.savefig("contourplot.png")✨ Giá trị cốt lõi: Sự kết hợp giữa khả năng xử lý dữ liệu mạnh mẽ của Stata và hệ sinh thái thuật toán tiên tiến của Python mở ra một quy trình làm việc liền mạch. Kỹ thuật kiểm chứng chéo giúp loại bỏ rủi ro lệch mô hình do sự phân bổ ngẫu nhiên của dữ liệu, tạo ra một ranh giới quyết định không tuyến tính phản ánh sát thực tế lâm sàng của tập dữ liệu y tế.
Bài tập ứng dụng: Nếu bạn muốn thay đổi mô hình SVM từ việc sử dụng hàm hạt nhân đa thức sang hàm hạt nhân cơ sở xuyên tâm, bạn sẽ phải thay đổi tham số cấu hình nào trong không gian tìm kiếm lưới và điều này sẽ tác động ra sao đến độ cong của ranh giới quyết định trên không gian hai chiều?

