Trong phân tích dữ liệu y sinh và dịch tễ học, việc so sánh các chỉ số giữa các nhóm đối tượng là bước không thể thiếu. Trước khi đi sâu vào mô hình hồi quy, các nhà nghiên cứu thường cần một bảng tổng hợp kết quả kiểm định giả thiết để đánh giá sự khác biệt trung bình hoặc phân phối. Bài viết này sẽ hướng dẫn bạn cách tận dụng tùy chọn lệnh trong cấu trúc bảng của phiên bản mới, biến các đầu ra của kiểm định thống kê thành một báo cáo chuẩn học thuật chỉ bằng vài dòng mã gọn gàng.
Chuẩn bị dữ liệu và nền tảng kiểm định
Chúng ta bắt đầu bằng cách tải bộ dữ liệu khảo sát sức khỏe quốc gia đã được tích hợp sẵn. Mục tiêu cụ thể ở đây là so sánh các chỉ số sinh học và nhân trắc học giữa nhóm có tiền sử tăng huyết áp và nhóm không có. Biến mã hóa nhóm là highbp.
1webuse nhanes2l
2describe age hgb hct iron albumin height weight bmi bpsystolĐể kiểm tra sự khác biệt về tuổi tác giữa hai nhóm, chúng ta sử dụng lệnh kiểm định t. Khi chạy xong, phần mềm sẽ tạm lưu một loạt các thống kê trung gian vào bộ nhớ. Việc gọi hiển thị các giá trị này là bước then chốt để trích xuất sau này.
1ttest age, by(highbp)
2return listCác giá trị lưu trữ dưới dạng đại lượng vô hướng bao gồm r(mu_1) là trung bình nhóm không tăng huyết áp, r(mu_2) là trung bình nhóm có tăng huyết áp, và r(p) là xác suất kiểm định. Đây chính là những thành phần sẽ đi thẳng vào cột của bảng báo cáo.
Cấu trúc hóa bảng kiểm định đơn lẻ
Cú pháp cốt lõi để đưa kết quả kiểm định vào khung bảng rất trực quan. Chúng ta thiết lập hàng đại diện cho lệnh thực thi và cột đại diện cho kết quả thu về. Bằng cách định nghĩa rõ ràng tên cột và ánh xạ chúng với các đại lượng trả về, bảng số liệu sẽ được sắp xếp ngay lập tức.
1table (command) (result), command(Normotensive = r(mu_1) Hypertensive = r(mu_2) Diff = r(mu_2)-r(mu_1) pval = r(p) : ttest age, by(highbp))Giao diện mặc định thường hiển thị nguyên dòng lệnh ở hàng tiêu đề. Để chuyên nghiệp hơn, ta cần gán nhãn lại cho chiều không gian này.
1collect label levels command 1 "Tuổi" modify
2collect preview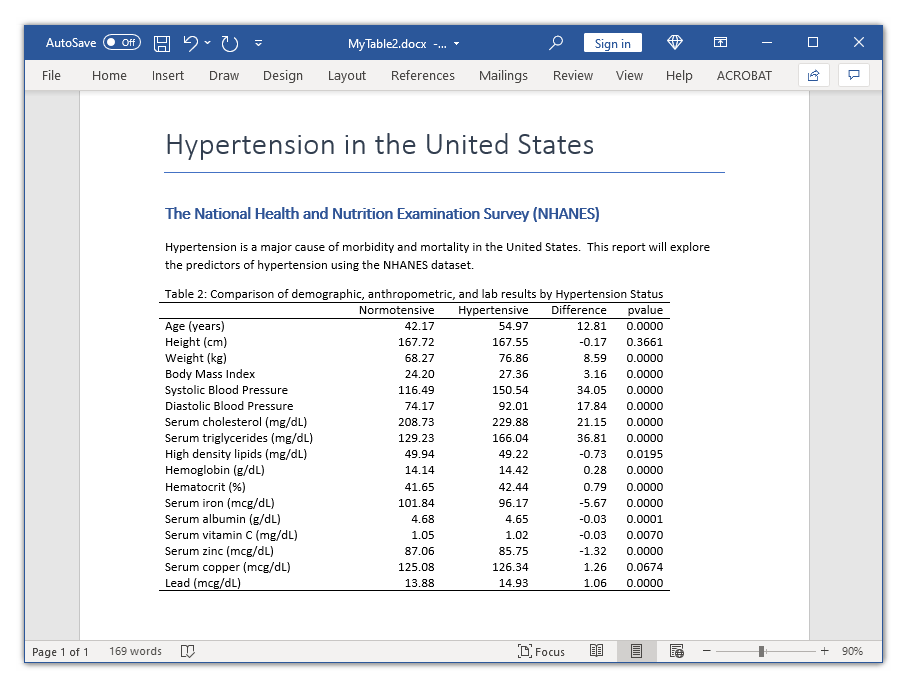
Sau khi bố cục hình thành, bước tinh chỉnh cuối cùng là định dạng số thập phân và đường viền. Lệnh điều khiển kiểu ô cho phép áp dụng định dạng phần trăm hoặc số thực cho từng cột riêng biệt, đồng thời loại bỏ các nét kẻ dọc không cần thiết ở cột đầu tiên để đạt chuẩn xuất bản.
1collect style cell result[Normotensive], nformat(%6.1f)
2collect style cell result[Hypertensive], nformat(%6.1f)
3collect style cell result[Diff], nformat(%6.1f)
4collect style cell result[pval], nformat(%6.4f)
5collect style cell border_block border(right pattern(nil))
6collect previewNhân rộng bảng với kỹ thuật biến lưu trữ cục bộ
Khi cần kiểm định cho hàng loạt biến như nồng độ cholesterol, trọng lượng, hay chỉ số khối cơ thể, việc lặp lại nguyên khối cú pháp trên sẽ khiến câu lệnh trở nên dài dòng và khó bảo trì. Giải pháp tối ưu là lưu trữ phần ánh xạ cột vào một biến giữ giá trị tạm thời.
1local resmap "Normotensive = r(mu_1) Hypertensive = r(mu_2) Diff = r(mu_2)-r(mu_1) pval = r(p)"Bây giờ chúng ta chỉ cần gọi biến này vào bên trong mỗi tùy chọn lệnh, giúp cấu trúc gọn nhẹ và dễ đọc hơn rất nhiều.
1table (command) (result), command(`resmap' : ttest age by(highbp)) command(`resmap' : ttest height by(highbp)) command(`resmap' : ttest weight by(highbp)) nformat(%6.2f Normotensive Hypertensive Diff) nformat(%6.4f pval)Việc đổi tên nhãn cho các hàng tương ứng cũng được thực hiện tương tự, chỉ cần liệt kê từng vị trí và chuỗi ký tự mô tả mới. Khi bảng hoàn chỉnh, bạn đã có một ma trận so sánh đầy đủ cho cả nhóm biến định lượng.
Xuất bản báo cáo sang tài liệu văn phòng
Sau khi hài lòng với định dạng hiển thị trên màn hình, bước chuyển đổi sang tài liệu báo cáo chỉ đòi hỏi ba lệnh liên tiếp. Hệ sinh thái báo cáo cho phép nhúng trực tiếp đối tượng bảng vào tập tin văn bản, kèm theo tự động căn chỉnh độ rộng cột.
1putdocx clear
2putdocx begin
3putdocx paragraph style(Title)
4putdocx text ("So sánh chỉ số sức khỏe theo nhóm tăng huyết áp")
5collect style putdocx layout(autofitcontents) title("Bảng kiểm định thống kê mô tả")
6putdocx collect
7putdocx save report.docx replaceQuy trình này đảm bảo tính nhất quán tuyệt đối giữa kết quả tính toán và văn bản báo cáo, loại bỏ hoàn toàn sai sót do sao chép thủ công.
✨ Giá trị đắt giá: Khả năng tự động hóa việc trích xuất giá trị trả về giúp bạn xây dựng các tập lệnh có thể tái sử dụng cho nhiều bộ dữ liệu khác nhau. Thay vì ghi nhớ các bước sao chép thủ công vào bảng tính, bạn chỉ cần điều chỉnh tên biến và cơ chế ánh xạ sẽ tự sinh ra toàn bộ cấu trúc bảng. Đây là nền tảng tư duy quan trọng để chuyển dịch từ thao tác thủ công sang quy trình phân tích lặp lại có độ tin cậy cao.
Câu hỏi tư duy: Nếu bạn muốn bổ sung thêm các chỉ số như trung vị hoặc độ lệch chuẩn, các đại lượng trả về r() sẽ được thay thế như thế nào? Hãy thử mở rộng phép ánh xạ cột để bao gồm cả khoảng tin cậy chín mươi lăm phần trăm của chênh lệch trung bình và định dạng lại các cột tương ứng.

