Trong quá trình thực hiện kiểm định giả thuyết không hoặc xây dựng mô hình hồi quy, chúng ta thường xuyên phải đối mặt với bài toán xử lý dữ liệu bị thiếu. Một lời khuyên rất phổ biến là thực hiện điền giá trị trung bình. Cách làm này hiểu đơn giản là thay thế bất kỳ giá trị nào bị khuyết bằng trung bình của biến số đó, được tính toán từ các quan sát hiện có. Tuy nhiên, phương pháp này mang lại những rủi ro ngầm và trong nhiều trường hợp còn tệ hơn là bỏ qua dữ liệu thiếu. Hãy cùng sử dụng ngôn ngữ lập trình để chứng minh điều này.
Tác động đến phương sai và độ lệch chuẩn
Để bắt đầu, chúng ta sẽ mô phỏng một vector dữ liệu có tên là x tuân theo phân phối chuẩn ngẫu nhiên.
1set.seed(2112)
2x <- rnorm(100, mean = 0, sd = 1)
3(mean1 <- mean(x))
4[1] 0.01129628
5(sd1 <- sd(x))
6[1] 1.032159Chúng ta có thể thấy giá trị trung bình và độ lệch chuẩn lần lượt xấp xỉ 0 và 1. Ở bước tiếp theo, chúng ta sẽ chọn ngẫu nhiên 20% các quan sát và biến chúng thành giá trị NA. Chúng ta vẫn có thể tính toán lại trung bình và độ lệch chuẩn khi loại trừ các giá trị bị thiếu này. Kết quả cho thấy các chỉ số vẫn tương đối ổn định.
1x[sample(length(x), length(x) * 0.2, replace = FALSE)] <- NA
2(mean2 <- mean(x, na.rm = TRUE))
3[1] 0.02136184
4(sd2 <- sd(x, na.rm = TRUE))
5[1] 1.071757Bây giờ, chúng ta sẽ thay thế các giá trị NA vừa tạo bằng giá trị trung bình. Lúc này, độ lệch chuẩn đã nhỏ hơn khá nhiều, đồng nghĩa với việc phương sai của ước lượng đã bị thu hẹp. Vì rất nhiều kiểm định thống kê phụ thuộc trực tiếp vào phương sai, việc làm giảm phương sai một cách giả tạo có thể dẫn đến những kết luận sai lệch nghiêm trọng.
1x[is.na(x)] <- mean(x, na.rm = TRUE)
2(mean3 <- mean(x))
3[1] 0.02136184
4(sd3 <- sd(x))
5[1] 0.9573977Chứng minh thông qua mô phỏng lặp lại
Để cho thấy đây không phải là một sự bất thường ngẫu nhiên chỉ xảy ra với một mẫu thử duy nhất, chúng ta sẽ lặp lại quy trình trên một nghìn lần và lưu trữ kết quả vào một data frame.
1n_samples <- 1000
2percent_missing <- 0.10
3sd_diffs <- data.frame(sample = 1:n_samples,
4 sd_drop_miss = numeric(n_samples),
5 sd_impute_miss = numeric(n_samples))
6for(i in seq_len(n_samples)) {
7 x2 <- x
8 x2[sample(length(x), length(x) * percent_missing, replace = FALSE)] <- NA
9 sd_diffs[i,]$sd_drop_miss <- sd(x2, na.rm = TRUE)
10 x2[is.na(x2)] <- mean(x2, na.rm = TRUE)
11 sd_diffs[i,]$sd_impute_miss <- sd(x2)
12}
13sd_diffs |>
14 reshape2::melt(id.vars = 'sample', variable.name = 'calculation_type', value.name = 'sd') |>
15 ggplot(aes(x = sd, color = calculation_type)) +
16 geom_vline(xintercept = sd(x)) +
17 geom_density() +
18 xlab('Standard Deviation') +
19 theme_minimal()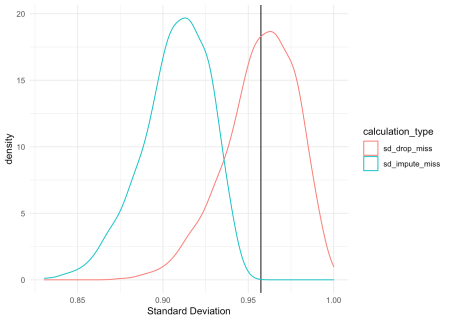
Như biểu đồ mật độ phân phối phía trên minh họa, có một sự khác biệt rất rõ rệt trong các ước lượng độ lệch chuẩn giữa hai trường hợp: tính toán chỉ dùng giá trị quan sát thực tế và tính toán sau khi đã điền các giá trị thiếu bằng trung bình. Phép t-test dưới đây sẽ củng cố thêm nhận định này.
1t.test(sd_diffs$sd_drop_miss, sd_diffs$sd_impute_miss)
2Welch Two Sample t-test
3data: sd_diffs$sd_drop_miss and sd_diffs$sd_impute_miss
4t = 54.288, df = 1992.4, p-value < 2.2e-16
5alternative hypothesis: true difference in means is not equal to 0
695 percent confidence interval:
7 0.04782442 0.05140925
8sample estimates:
9mean of x mean of y
100.9569447 0.9073278Tác động sai lệch đến kiểm định tương quan
Bây giờ hãy xem xét cách phương pháp điền trung bình có thể ảnh hưởng đến việc ước lượng tương quan giữa hai biến số. Chúng ta sẽ mô phỏng hai biến có mức độ tương quan tổng thể là 0.18.
1n <- 100
2mean_x <- 0
3mean_y <- 0
4sd_x <- 1
5sd_y <- 1
6rho <- 0.18
7set.seed(2112)
8df <- mvtnorm::rmvnorm(
9 n = 100,
10 mean = c(mean_x, mean_y),
11 sigma = matrix(c(sd_x^2, rho * (sd_x * sd_y),
12 rho * (sd_x * sd_y), sd_y^2), 2, 2)) |>
13 as.data.frame() |>
14 dplyr::rename(x = V1, y = V2)
15cor.test(df$x, df$y)
16Pearson's product-moment correlation
17data: df$x and df$y
18t = 1.8314, df = 98, p-value = 0.07008
19alternative hypothesis: true correlation is not equal to 0
2095 percent confidence interval:
21 -0.01504323 0.36527878
22sample estimates:
23 cor
240.1819124Kiểm định cho thấy với bộ dữ liệu ban đầu, chỉ số p-value lớn hơn mức ý nghĩa 0.05, tức là chúng ta không thể bác bỏ giả thuyết không rằng tương quan bằng 0. Tiếp theo, chúng ta chọn ngẫu nhiên 20% giá trị của biến x và đặt thành NA, sau đó kiểm tra lại tương quan trên các dữ liệu còn lại.
1df_miss <- df
2df_miss[sample(n, size = 0.2 * n, replace = FALSE),]$x <- NA
3cor.test(df_miss$x, df_miss$y)
4Pearson's product-moment correlation
5data: df_miss$x and df_miss$y
6t = 1.8392, df = 78, p-value = 0.06969
7alternative hypothesis: true correlation is not equal to 0
895 percent confidence interval:
9 -0.01658176 0.40543327
10sample estimates:
11 cor
120.2038779Lưu ý rằng p-value cho cả trường hợp dữ liệu đầy đủ và trường hợp dữ liệu đã bị khuyết một phần (chỉ tính trên các dòng hoàn chỉnh) đều lớn hơn 0.05. Nghĩa là về mặt thống kê, mối tương quan vẫn không có ý nghĩa.
Vấn đề thực sự nảy sinh khi chúng ta quyết định điền các giá trị thiếu bằng mức trung bình và chạy lại hàm tính tương quan.
1df_miss[is.na(df_miss$x),] <- mean(df$x, na.rm = TRUE)
2cor.test(df_miss$x, df_miss$y)
3Pearson's product-moment correlation
4data: df_miss$x and df_miss$y
5t = 2.0582, df = 98, p-value = 0.04223
6alternative hypothesis: true correlation is not equal to 0
795 percent confidence interval:
8 0.007431517 0.384594022
9sample estimates:
10 cor
110.2035525Lúc này, p-value bất ngờ giảm xuống dưới 0.05. Theo nguyên tắc thống kê, chúng ta sẽ bác bỏ giả thuyết không và vội vàng kết luận rằng có một mối tương quan mang ý nghĩa thống kê giữa x và y. Đây hoàn toàn là một kết quả giả do thao tác làm mượt dữ liệu gây ra, bởi bộ dữ liệu gốc được dùng để mô phỏng ngay từ đầu vốn dĩ không hề thể hiện mối tương quan này.
✨ Việc thay thế dữ liệu khuyết bằng giá trị trung bình không chỉ làm giảm phương sai giả tạo mà còn có nguy cơ đẩy các mối quan hệ biến số vượt qua ngưỡng ý nghĩa thống kê một cách sai lệch, dẫn đến việc nhà phân tích dữ liệu vô tình rút ra những kết luận sai lầm về bản chất của mô hình.
Bạn thường dùng phương pháp nào thay thế cho việc điền giá trị trung bình khi gặp phải tập dữ liệu có tỷ lệ khuyết cao, và phương pháp đó giải quyết vấn đề hao hụt phương sai như thế nào?