Trong các bài viết trước, chúng ta đã tìm hiểu cách sử dụng lệnh table thế hệ mới để tạo bảng và các lệnh collect để tùy chỉnh cũng như xuất dữ liệu. Trong bài viết này, tôi sẽ hướng dẫn các bạn cách kết hợp những công cụ này để tạo ra một bảng thống kê mô tả chuyên nghiệp, thường được gọi là Bảng 1 trong các báo cáo khoa học. Mục tiêu của chúng ta là tạo ra một bảng dữ liệu hoàn chỉnh trong tài liệu Microsoft Word với định dạng chuẩn mực.
Khởi Tạo Bảng Cơ Bản
Đầu tiên, chúng ta sẽ sử dụng bộ dữ liệu NHANES và lệnh table để tạo cấu trúc bảng ban đầu. Tôi sẽ sử dụng tùy chọn nototal để loại bỏ dòng tổng số nhằm giữ cho bảng gọn gàng hơn.
1webuse nhanes2l
2table (var) (highbp),
3 statistic(fvfrequency sex )
4 statistic(fvpercent sex)
5 statistic(mean age)
6 statistic(sd age)
7 nototalLệnh table sẽ tự động tạo ra một tập hợp kết quả. Chúng ta có thể kiểm tra các chiều trong tập hợp này bằng lệnh collect dims. Trong đó, chiều result chứa các thống kê mà chúng ta vừa khai báo. Khi liệt kê chi tiết các nhãn trong result, chúng ta thấy có bốn thành phần: tần suất biến phân loại, phần trăm biến phân loại, trung bình và độ lệch chuẩn.
Theo mặc định, các thống kê này được xếp chồng lên nhau. Để bảng chuyên nghiệp hơn, chúng ta nên đặt chúng nằm cạnh nhau. Chúng ta sẽ sử dụng lệnh collect recode để tạo ra hai cấp độ mới là column1 và column2. Sau đó, chúng ta xếp tần suất và trung bình vào cột 1, còn phần trăm và độ lệch chuẩn vào cột 2.
1collect recode result fvfrequency = column1
2 fvpercent = column2
3 mean = column1
4 sd = column2Thay Đổi Bố Cục Và Mở Rộng Bảng
Sau khi đã phân nhóm các chỉ số thống kê, chúng ta sử dụng lệnh collect layout để sắp xếp lại cấu trúc. Chúng ta sẽ lồng column1 và column2 dưới biến phân loại chính để tạo ra cấu trúc cột kép.
1collect layout (var) (highbp#result[column1 column2])Bây giờ, khi đã có bố cục cơ bản, chúng ta sẽ thêm vào các biến số khác như chỉ số khối cơ thể, chủng tộc, tình trạng sức khỏe và các chỉ số xét nghiệm máu. Thứ tự của các dòng trong bảng sẽ được quyết định bởi thứ tự mà chúng ta liệt kê các biến trong tùy chọn statistic.
1table (var) (highbp),
2 statistic(mean age bmi)
3 statistic(sd age bmi)
4 statistic(fvfrequency sex race hlthstat)
5 statistic(fvpercent sex race hlthstat)
6 statistic(mean tcresult tgresult hdresult)
7 statistic(sd tcresult tgresult hdresult)
8 nototal
9collect recode result fvfrequency = column1
10 fvpercent = column2
11 mean = column1
12 sd = column2
13collect layout (var) (highbp#result[column1 column2])Tùy Chỉnh Định Dạng Số Và Nhãn
Bảng hiện tại đã có đầy đủ thông tin nhưng các con số cần được định dạng lại để dễ đọc hơn. Chúng ta sẽ sử dụng collect style cell để áp dụng các kiểu hiển thị khác nhau cho từng loại dữ liệu.
Đối với các biến phân loại, chúng ta định dạng tần suất ở column1 là số nguyên có dấu phẩy ngăn cách hàng nghìn, và phần trăm ở column2 với một chữ số thập phân kèm ký hiệu %. Đối với các biến liên tục, chúng ta để một chữ số thập phân cho cả trung bình và độ lệch chuẩn, đồng thời thêm dấu ngoặc đơn bao quanh độ lệch chuẩn để phân biệt.
1collect style cell var[sex race hlthstat]#result[column1], nformat(%6.0fc)
2collect style cell var[sex race hlthstat]#result[column2], nformat(%6.1f) sformat("%s%%")
3collect style cell var[age bmi tcresult tgresult hdresult]#result[column1 column2], nformat(%6.1f)
4collect style cell var[age bmi tcresult tgresult hdresult]#result[column2], sformat("(%s)")
5collect previewTiếp theo, chúng ta tinh chỉnh các nhãn tiêu đề. Chúng ta sẽ đổi tên biến highbp thành Tăng huyết áp, sửa các nhãn giá trị thành Không và Có. Để bảng thoáng hơn, chúng ta ẩn các tiêu đề cột trung gian và loại bỏ đường kẻ dọc ngăn cách.
1collect label dim highbp "Hypertension", modify
2collect label levels highbp 0 "No" 1 "Yes"
3collect style header result, level(hide)
4collect style row stack, nobinder spacer
5collect style cell border_block, border(right, pattern(nil))
6collect previewXuất Bảng Ra Microsoft Word
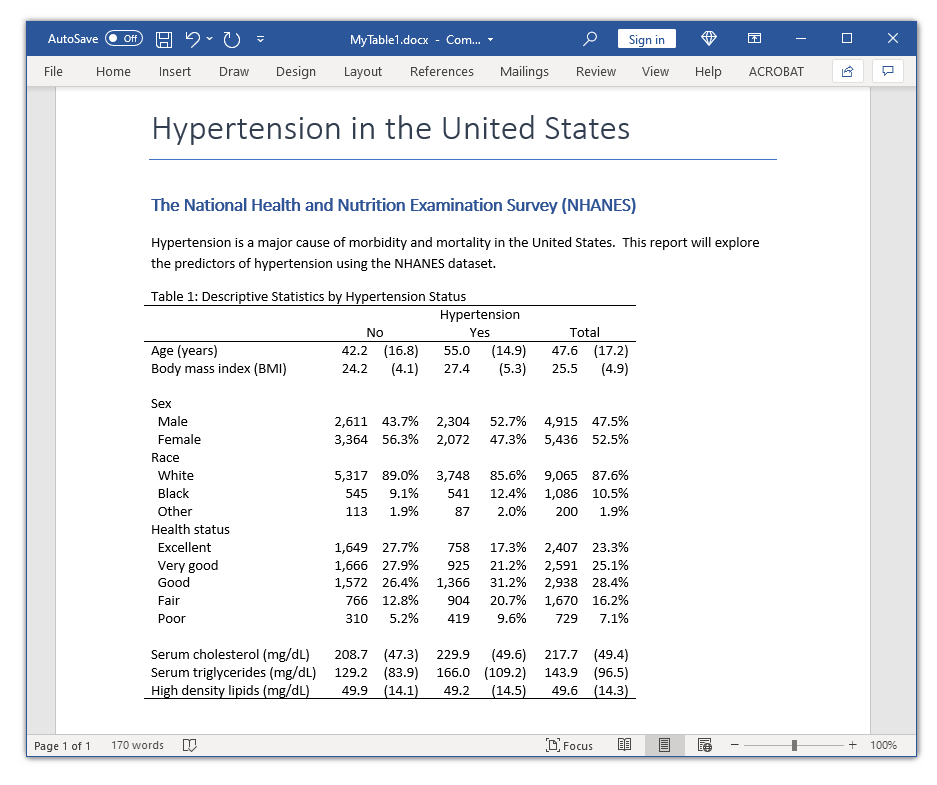
Khi đã hài lòng với bố cục, bước cuối cùng là xuất bảng. Chúng ta sử dụng hệ thống lệnh putdocx để tạo tiêu đề văn bản, thêm các đoạn mô tả và sau đó chèn bảng vào. Một tùy chọn quan trọng là layout(autofitcontents) giúp bảng giữ nguyên kích thước tối ưu thay vì bị kéo giãn quá mức trong Word.
1putdocx begin
2putdocx paragraph, style(Title)
3putdocx text ("Hypertension in the United States")
4putdocx paragraph, style(Heading1)
5putdocx text ("The National Health and Nutrition Examination Survey (NHANES)")
6collect style putdocx, layout(autofitcontents) title("Table 1: Descriptive Statistics by Hypertension Status")
7putdocx collect
8putdocx save MyTable1.docx, replaceViệc nắm vững các lệnh collect không chỉ giúp bạn tạo ra các bảng biểu đúng chuẩn thống kê mà còn tiết kiệm đáng kể thời gian trình bày báo cáo. Thay vì sao chép thủ công từng con số, bạn có thể tạo ra quy trình làm việc tự động và chính xác tuyệt đối.
✨ Giá trị đắt giá: Khả năng kết hợp toán tử tương tác # với lệnh collect style cell cho phép bạn nhắm mục tiêu chính xác đến từng ô cụ thể trong bảng để định dạng, giúp tách biệt hoàn toàn giữa nội dung dữ liệu và hình thức trình bày.
Bài tập ứng dụng
Dựa trên quy trình trên, bạn hãy thử thêm cột Total vào bảng bằng cách loại bỏ tùy chọn nototal trong lệnh table, sau đó thực hiện định dạng cột tổng số này sao cho đồng nhất với các cột nhóm bệnh lý hiện có.

