
Trong phân tích tài chính và quản trị rủi ro, việc mô phỏng dữ liệu đồng thời của nhiều tài sản mà vẫn giữ nguyên được cấu trúc phụ thuộc phức tạp là một thách thức lớn. Các phương pháp mô hình hóa truyền thống thường dựa vào giả định phân phối chuẩn, vốn dễ dàng thất bại khi đối mặt với dữ liệu thực tế có phân phối đuôi dày hoặc mối quan hệ phi tuyến. Để giải quyết vấn đề này, phương pháp R-vine copula nổi lên như một công cụ mạnh mẽ, cho phép chúng ta ghép nối các phân phối biên khác nhau thành một phân phối chung một cách linh hoạt. Bài viết này sẽ hướng dẫn cách sử dụng thư viện esgtoolkit trong ngôn ngữ R để xây dựng mô hình R-vine copula và tạo dữ liệu giả lập chất lượng cao.
Tìm hiểu về R-vine copula và thư viện esgtoolkit
Copula là một hàm toán học dùng để liên kết các phân phối biên của các biến ngẫu nhiên đơn lẻ nhằm tạo ra một phân phối đồng thời. Trong số các cấu trúc copula, vine copula phân rã phân phối đồng thời đa chiều thành các cặp copula hai chiều thông qua một cấu trúc dạng cây liên kết. Điều này giúp kiểm soát tốt các mối quan hệ phụ thuộc không đối xứng ở vùng đuôi, một hiện tượng cực kỳ phổ biến trong dữ liệu tài chính khi thị trường sụt giảm mạnh cùng một lúc.
Thư viện esgtoolkit cung cấp một giao diện lập trình trực quan và tối ưu hóa để ước lượng các tham số của mô hình R-vine copula, đồng thời chạy các lượt mô phỏng thử nghiệm để tìm ra bộ dữ liệu giả lập khớp nhất với dữ liệu thực tế.
Quy trình mô phỏng dữ liệu với esgtoolkit
Để minh họa, chúng ta sẽ sử dụng bộ dữ liệu chỉ số chứng khoán châu Âu có sẵn trong R bao gồm các chỉ số DAX, SMI, CAC và FTSE. Quy trình thực hiện bao gồm cài đặt thư viện, tính toán tỷ suất sinh lợi logarit, ước lượng mô hình và tiến hành mô phỏng dữ liệu giả lập.
Cài đặt và chuẩn bị dữ liệu
Trước tiên, chúng ta cần cài đặt thư viện esgtoolkit trực tiếp từ nguồn mã nguồn mở GitHub và chuẩn bị dữ liệu lịch sử để huấn luyện mô hình.
1devtools::install_github("Techtonique/esgtoolkit")
2library(esgtoolkit)
3y <- esgtoolkit::calculatereturns(ts(EuStockMarkets[1:250, ], start=start(EuStockMarkets),
4 frequency=frequency(EuStockMarkets)), type = "log")
5# Chạy mô phỏng dữ liệu với 5 lượt thử nghiệm
6result <- simulate_rvine(y, n = 500, verbose = TRUE, n_trials = 5)
7# Hiển thị tóm tắt kết quả
8print(result)
9# Vẽ biểu đồ phân phối và tương quan
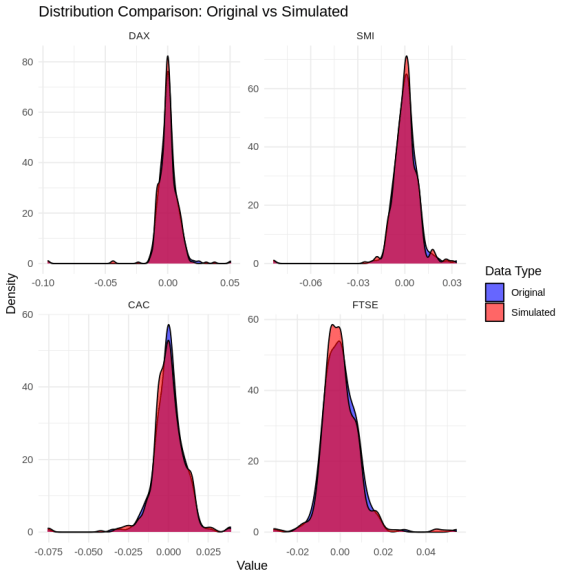
10plot(result, type = "distribution")
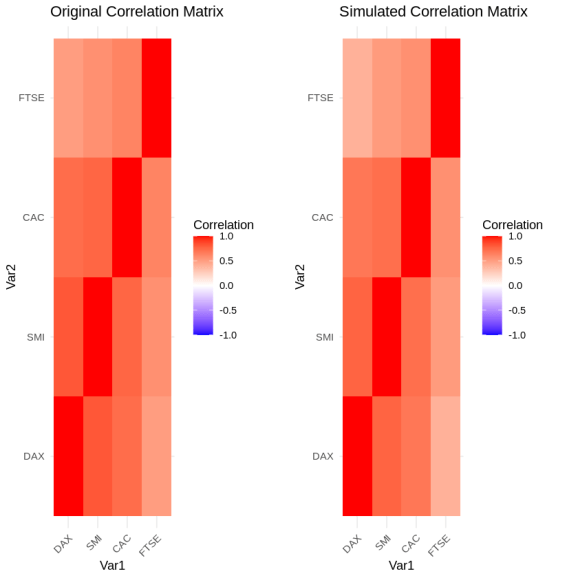
11plot(result, type = "correlation")
12# Truy cập thông tin chẩn đoán chi tiết
13str(result$diagnostics)
14# Trích xuất dữ liệu mô phỏng
15sim_data <- result$simulated_data
16head(sim_data)Phân tích kết quả mô hình
Quá trình chạy hàm mô phỏng sẽ tự động chuyển đổi dữ liệu thực tế sang phân phối đều ở các rìa biên để xử lý các điểm biên tốt hơn. Sau đó, hệ thống tiến hành khớp cấu trúc R-vine copula phù hợp nhất dựa trên tiêu chí thông tin để tối ưu hóa cấu trúc cây.
Kết quả ước lượng cấu trúc cây cho thấy các cặp biến được liên kết bằng nhiều họ copula khác nhau tùy thuộc vào đặc tính phụ thuộc của chúng. Ví dụ, mối quan hệ giữa một số cặp chỉ số được mô tả bằng phân phối chuẩn, trong khi các cặp khác lại sử dụng các họ phân phối có đuôi bất đối xứng để phản ánh chính xác xu hướng biến động đồng thời khi thị trường có biến động mạnh.
Với 5 lượt mô phỏng thử nghiệm, thuật toán tự động chọn ra lượt có điểm số chất lượng tốt nhất là khoảng 0.0984. Sai số tuyệt đối trung bình của hệ số tương quan Kendall và Pearson lần lượt là 0.0077 và 0.0428, chứng minh dữ liệu giả lập có độ tương quan cực kỳ sát với dữ liệu gốc ban đầu.
Kiểm định chất lượng dữ liệu giả lập
Bên cạnh việc so sánh hệ số tương quan, chúng ta cũng có thể truy cập các thông số chẩn đoán chi tiết để đánh giá mức độ tương đồng về mặt phân phối thông qua kiểm định Kolmogorov-Smirnov. Giá trị p-value lớn của kiểm định này cho cả bốn chỉ số chứng khoán cho thấy không có sự khác biệt có ý nghĩa thống kê giữa phân phối của dữ liệu mô phỏng và dữ liệu gốc. Điều này đảm bảo dữ liệu giả lập hoàn toàn có thể được dùng tin cậy cho các mô hình kiểm thử áp lực hoặc định giá tài sản tài chính phức tạp.
Dữ liệu mô phỏng thu được
Dưới đây là một vài dòng dữ liệu đầu tiên trong số 500 quan sát giả lập được tạo ra cho các chỉ số DAX, SMI, CAC và FTSE, thể hiện rõ các đặc tính biến động đồng thời của thị trường thực tế:
Dữ liệu mô phỏng mẫu:
Dòng 1: DAX là -0.001398544, SMI là -0.0015309795, CAC là 0.003170410, FTSE là 0.0008758254
Dòng 2: DAX là 0.004458917, SMI là 0.0026640098, CAC là 0.011666435, FTSE là 0.0057322484
Dòng 3: DAX là -0.001597764, SMI là -0.0001979084, CAC là -0.004832143, FTSE là 0.0011097778
Dòng 4: DAX là -0.001501251, SMI là -0.0034774275, CAC là -0.003218613, FTSE là 0.0020315141
Dòng 5: DAX là 0.000000000, SMI là 0.0045969506, CAC là 0.001912011, FTSE là -0.0044810433
Dòng 6: DAX là -0.002419004, SMI là -0.0004654500, CAC là -0.004832588, FTSE là -0.0055430360
✨ Giá trị đắt giá: Việc mô phỏng dữ liệu đa biến bằng R-vine copula giúp các nhà nghiên cứu và phân tích định lượng vượt qua giới hạn của các giả định phân phối chuẩn truyền thống. Bằng cách bảo toàn chính xác cấu trúc tương quan đuôi phi tuyến tính giữa các tài sản tài chính, công cụ này giúp các kịch bản kiểm thử rủi ro trở nên thực tế và chuẩn xác hơn bao giờ hết, tránh hiện tượng đánh giá thấp rủi ro hệ thống trong các giai đoạn thị trường căng thẳng.
Câu hỏi tư duy: Hãy thử thay đổi số lượng thử nghiệm mô phỏng và trọng số đánh giá chất lượng trong mô hình để quan sát sự thay đổi của sai số tương quan Kendall và Pearson. Theo bạn, khi số lượng biến số tăng lên quá lớn, cấu trúc dạng cây của R-vine copula sẽ gặp phải những thách thức gì về mặt hiệu năng tính toán và làm thế nào để tối ưu hóa điều đó?

