Mô hình hồi quy tự vectơ cấu trúc là một công cụ mạnh mẽ trong kinh tế lượng vĩ mô, giúp chúng ta nhận diện các cú sốc kinh tế và đánh giá tác động của chúng qua thời gian. Trong bài viết này, chúng ta sẽ tìm hiểu cách thiết lập các ràng buộc dài hạn trong mô hình này bằng cách tái hiện lại nghiên cứu kinh điển của hai tác giả Blanchard và Quah năm 1989 trên phần mềm Stata.
Khung Lý Thuyết Cơ Bản
Trong các nghiên cứu trước đây về hồi quy tự vectơ cấu trúc, việc nhận diện các tham số thường dựa trên các ràng buộc ngắn hạn, tức là cách các cú sốc tác động ngay lập tức lên các biến nội sinh tại thời điểm xảy ra cú sốc. Ngược lại, Blanchard và Quah đạt được sự nhận diện bằng cách áp dụng các ràng buộc lên tác động dài hạn của các cú sốc, tức là phản ứng giới hạn của một biến nội sinh khi thời gian tiến về vô hạn.
Trong một hệ hồi quy tự vectơ dừng, phản ứng của mỗi biến đối với từng cú sốc phải tiến về không trong dài hạn. Blanchard và Quah phân tích một hệ thống gồm tổng sản phẩm quốc gia thực tế GNP và tỷ lệ thất nghiệp, trong đó tốc độ tăng trưởng GNP và mức thất nghiệp được giả định là các chuỗi dừng. Hệ thống này có hai cú sốc là cú sốc cung và cú sốc cầu. Phản ứng dài hạn của tăng trưởng GNP và thất nghiệp đối với các cú sốc này phải bằng không vì các biến này là dừng.
Ràng buộc nhận diện ở đây là một xung từ cú sốc cầu không có tác động dài hạn đến mức GNP. Do đó, phản ứng tích lũy của tăng trưởng GNP đối với cú sốc cầu sẽ bị ràng buộc bằng không. Cú sốc cung được định nghĩa là cú sốc dẫn đến sự thay đổi dài hạn trong mức GNP, còn cú sốc cầu là cú sốc không làm thay đổi mức GNP trong dài hạn.
Mô hình của Blanchard và Quah có thể biểu diễn qua toán học với ma trận độ trễ AL tác động lên vectơ tăng trưởng GNP và tỷ lệ thất nghiệp bằng ma trận B nhân với vectơ cú sốc cung và cú sốc cầu. Khi nghịch đảo mô hình này, chúng ta thu được dạng biểu diễn chuyển động trung bình vô hạn với ma trận hệ số CL hai nhân hai thể hiện phản ứng dài hạn. Giả định nhận diện yêu cầu phần tử hàng một cột hai của ma trận này bằng không, tương đương với việc mức GNP cuối cùng sẽ quay trở lại xu hướng ban đầu sau một cú sốc cầu.
Chuẩn Bị Dữ Liệu Và Tiền Xử Lý
Dữ liệu cho bài thực hành này được lấy từ cơ sở dữ liệu FRED với các mã GNPC96 và UNRATE. Tỷ lệ thất nghiệp được tính bằng trung bình quý từ các quan sát tháng. Tốc độ tăng trưởng GNP được tính bằng bốn trăm lần sai phân logarit của GNP thực tế theo quý. Vì dữ liệu trên FRED liên tục được cập nhật và điều chỉnh, kết quả kiểm định có thể có sai lệch nhỏ so với số liệu gốc của bài báo năm 1989.
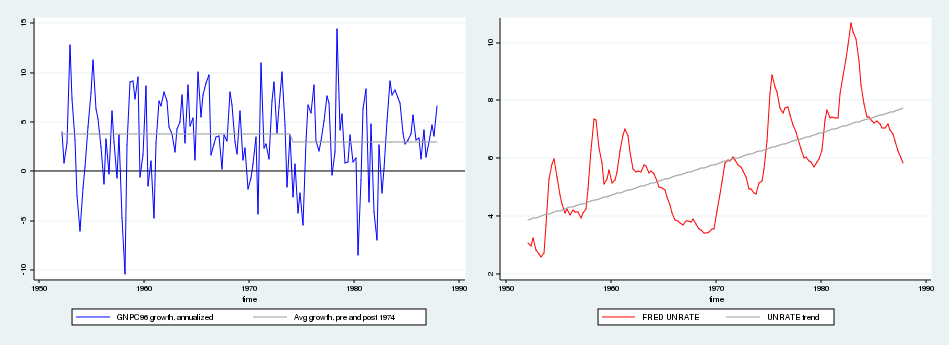
Nghiên cứu gốc sử dụng dữ liệu quý từ năm 1952 đến năm 1987. Các tác giả điều chỉnh dữ liệu thô bằng cách loại bỏ giá trị trung bình khỏi chuỗi tăng trưởng GNP một cách riêng biệt cho hai giai đoạn trước và sau năm 1974, đồng thời loại bỏ xu hướng thời gian tuyến tính khỏi chuỗi tỷ lệ thất nghiệp.
Chúng ta tiến hành tải dữ liệu và thực hiện các bước lọc xu hướng này trong Stata.
1use lrsvar.dta
2keep if year >= 1952
3keep if year <= 1987
4quietly regress unrate t
5predict unrate_adj, residBa dòng lệnh đầu tiên thực hiện tải dữ liệu và giới hạn mẫu từ năm 1952 đến năm 1987. Hai dòng tiếp theo thực hiện hồi quy tỷ lệ thất nghiệp theo biến thời gian và lưu phần dư vào biến mới để có chuỗi thất nghiệp đã hiệu chỉnh xu hướng.
Tiếp theo, chúng ta hiệu chỉnh chuỗi tăng trưởng GNP theo đúng phương pháp của Blanchard và Quah.
1generate bp1 = (year<1974)
2generate bp2 = (year>=1974)
3quietly regress growth bp1 bp2, noconstant
4predict growth_adj, residHai dòng lệnh đầu tiên tạo các biến giả tương ứng với hai giai đoạn trước và sau điểm gãy cấu trúc năm 1974. Hai dòng cuối cùng loại bỏ giá trị trung bình riêng biệt của từng thời kỳ và lưu phần dư vào biến tăng trưởng đã hiệu chỉnh.
Ước Lượng Mô Hình Và Phân Tích Hàm Phản Ứng Đẩy
Mô hình tự vectơ hồi quy cấu trúc dài hạn được ước lượng bằng lệnh svar với tùy chọn lreq. Chúng ta đặt biến tăng trưởng GNP lên trước trong thứ tự sắp xếp. Khi đó, ràng buộc nhận diện là phản ứng dài hạn của GNP đối với cú sốc thất nghiệp bằng không, dẫn đến việc thiết lập ma trận ràng buộc C có phần tử hàng một cột hai bằng không và các phần tử còn lại để trống để tự do ước lượng. Chúng ta sử dụng độ trễ bằng tám theo đúng bài báo gốc.
1matrix C = (., 0 \ .,.)
2svar growth_adj unrate_adj, lags(1/8) lreq(C)
3irf create lr, set(lrirf) step(40) replaceKết quả ước lượng sẽ hiển thị các tham số của ma trận ràng buộc dài hạn, trong đó hệ số biểu thị tác động dài hạn của cú sốc cầu lên tăng trưởng GNP được áp đặt cứng bằng không. Chúng ta cũng đã tạo và lưu kết quả phân tích hàm phản ứng đẩy vào một tệp dữ liệu trung gian.
Bây giờ, chúng ta có thể vẽ biểu đồ các hàm phản ứng đẩy cấu trúc để trực quan hóa các tác động này.
1irf graph sirf, yline(0,lcolor(black)) xlabel(0(4)40) byopts(yrescale)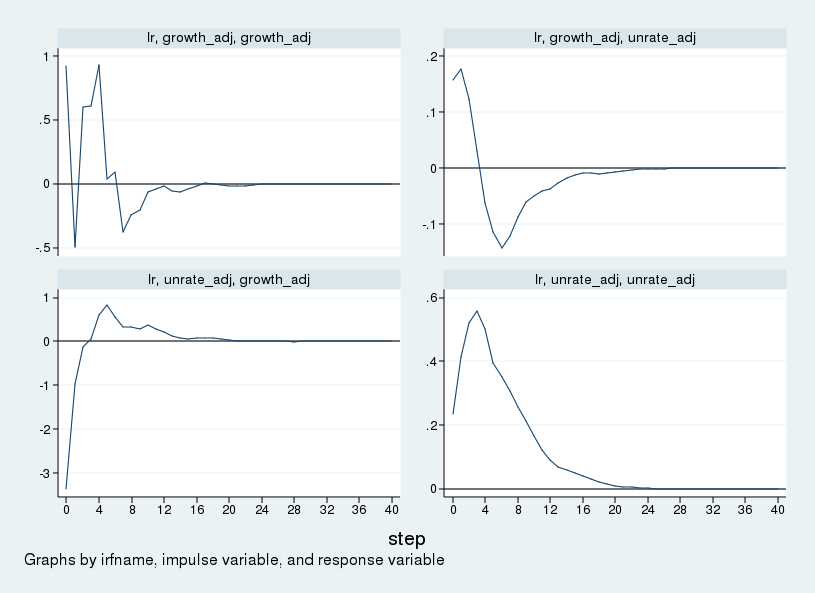
Biểu đồ hiển thị phản ứng đẩy của từng biến đối với mỗi cú sốc trong khoảng thời gian bốn mươi quý, tương đương mười năm. Do tăng trưởng GNP được xếp trước, xung lực tăng trưởng chính là cú sốc cung, còn xung lực thất nghiệp chính là cú sốc cầu.
Hàng đầu tiên của biểu đồ biểu diễn phản ứng của tăng trưởng GNP và tỷ lệ thất nghiệp đối với cú sốc cung. Tăng trưởng GNP tăng lên, trong khi tỷ lệ thất nghiệp tăng nhẹ khi mới xảy ra cú sốc, sau đó giảm dần và chạm đáy sau khoảng hai năm trước khi quay lại mức cân bằng dài hạn. Hàng dưới biểu diễn phản ứng đối với cú sốc cầu. Khi có cú sốc cầu, tăng trưởng sản lượng giảm ban đầu trước khi phục hồi sau một năm, còn thất nghiệp tăng lên và đạt đỉnh sau một năm rồi mới dần trở lại trạng thái ban đầu.
Hiệu Chỉnh Biểu Đồ Hàm Phản Ứng Đẩy
Các hàm phản ứng đẩy mặc định được tính theo tốc độ tăng trưởng của GNP chứ không phải mức GNP tuyệt đối. Để biểu diễn trực quan hơn giả định nhận diện, chúng ta cần tính lũy kế các phản ứng của tăng trưởng GNP để thấy được tác động lên mức GNP, trong khi giữ nguyên phản ứng của tỷ lệ thất nghiệp.
Tệp lưu trữ kết quả hàm phản ứng đẩy của Stata thực chất là một bộ dữ liệu có cấu trúc bảng đặc biệt. Chúng ta hoàn toàn có thể mở tệp này và xử lý các biến số bên trong như một bảng dữ liệu thông thường.
Đoạn mã dưới đây tạo ra một biến mới chứa phản ứng lũy kế của tăng trưởng GNP đối với từng cú sốc, đồng thời giữ nguyên phản ứng của thất nghiệp.
1use lrirf.irf, clear
2sort irfname impulse response step
3gen csirf = sirf
4by irfname impulse: replace csirf = sum(sirf) if response=="growth_adj"
5order irfname impulse response step sirf csirf
6save lrirf2.irf, replaceĐoạn mã trên tải dữ liệu hàm phản ứng đẩy, sắp xếp theo đúng thứ tự bước thời gian và biến tác động, sau đó cộng dồn các giá trị phản ứng đối với riêng biến tăng trưởng GNP. Kết quả được ghi đè vào một tệp lưu trữ mới.
Chúng ta tiến hành vẽ biểu đồ từ tệp dữ liệu đã được xử lý lũy kế này.
1irf set lrirf2.irf
2irf graph csirf, yline(0,lcolor(black)) noci xlabel(0(4)40) byopts(yrescale)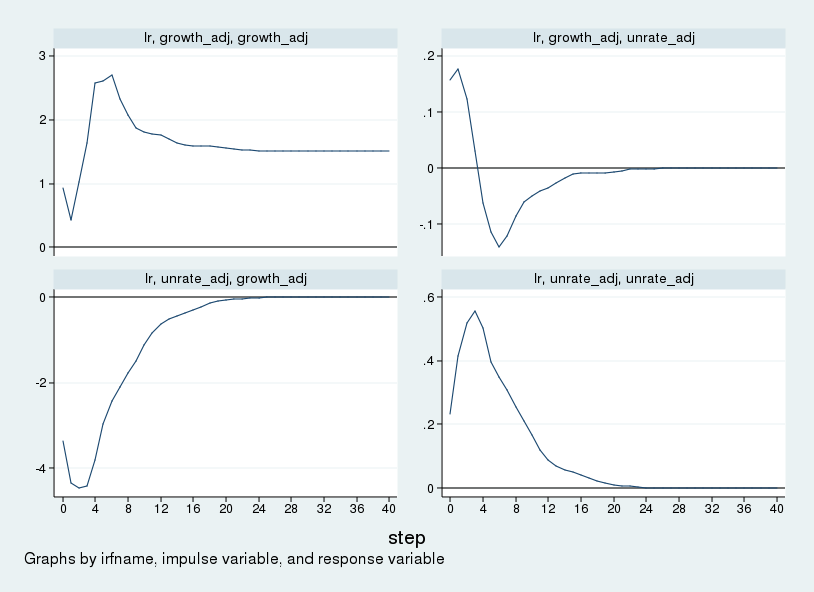
Kết quả biểu đồ tích lũy này tương thích hoàn toàn với hình vẽ trong bài báo gốc của Blanchard và Quah. Điểm khác biệt duy nhất về mặt quy mô là do Stata sử dụng độ lệch chuẩn làm quy mô cú sốc ban đầu, trong khi bài báo gốc sử dụng cú sốc có quy mô bằng một đơn vị.
Quan sát góc dưới bên trái của biểu đồ lũy kế, chúng ta thấy mức GNP ban đầu giảm do cú sốc cầu nhưng dần dần quay trở về mức không trong dài hạn. Đây chính là minh chứng trực quan rõ ràng nhất cho ràng buộc nhận diện dài hạn mà chúng ta đã áp đặt vào mô hình.
Kết Luận
Phương pháp nhận diện bằng ràng buộc dài hạn mang lại một cách tiếp cận linh hoạt và dựa nhiều hơn vào các lý thuyết kinh tế dài hạn để giải thích các biến động vĩ mô. Việc kết hợp công cụ ước lượng SVAR mạnh mẽ của Stata cùng khả năng can thiệp trực tiếp vào dữ liệu hàm phản ứng đẩy giúp các nhà nghiên cứu dễ dàng tùy biến các báo cáo phân tích theo nhu cầu thực tế.
✨ Việc hiểu rõ cấu trúc lưu trữ nội bộ của tệp kết quả phản ứng đẩy trong Stata cho phép bạn thực hiện các phép toán tùy chỉnh như tính tích lũy, chuyển đổi đơn vị hoặc kết hợp các chuỗi phản ứng mà các lệnh đồ họa mặc định không hỗ trợ trực tiếp.
Câu hỏi tư duy
Tại sao việc áp đặt ràng buộc dài hạn lên mức GNP lại đòi hỏi chúng ta phải lấy tổng tích lũy của hàm phản ứng đẩy đối với biến tốc độ tăng trưởng GNP trong mô hình VAR? Hãy giải thích mối quan hệ toán học giữa hai đại lượng này.

