Trong phiên bản Stata 17, hệ thống tạo bảng biểu đã được nâng cấp toàn diện, mang lại khả năng tùy biến mạnh mẽ và linh hoạt. Không chỉ dừng lại ở việc mở rộng chức năng của lệnh table, Stata còn giới thiệu một hệ thống hoàn toàn mới cho phép thu thập kết quả từ bất kỳ lệnh nào, thiết kế bố cục theo ý muốn và xuất bản trực tiếp sang các định dạng tài liệu phổ biến. Bài viết này sẽ hướng dẫn bạn những bước đầu tiên để làm quen với lệnh table cải tiến.
Những Ví Dụ Điển Hình Về Bảng Biểu Tùy Chỉnh
Trước khi đi sâu vào cú pháp, hãy cùng điểm qua một số mẫu bảng biểu mà bạn có thể dễ dàng tạo ra bằng hệ thống mới này.
Bảng Thống Kê Mô Tả Cơ Bản
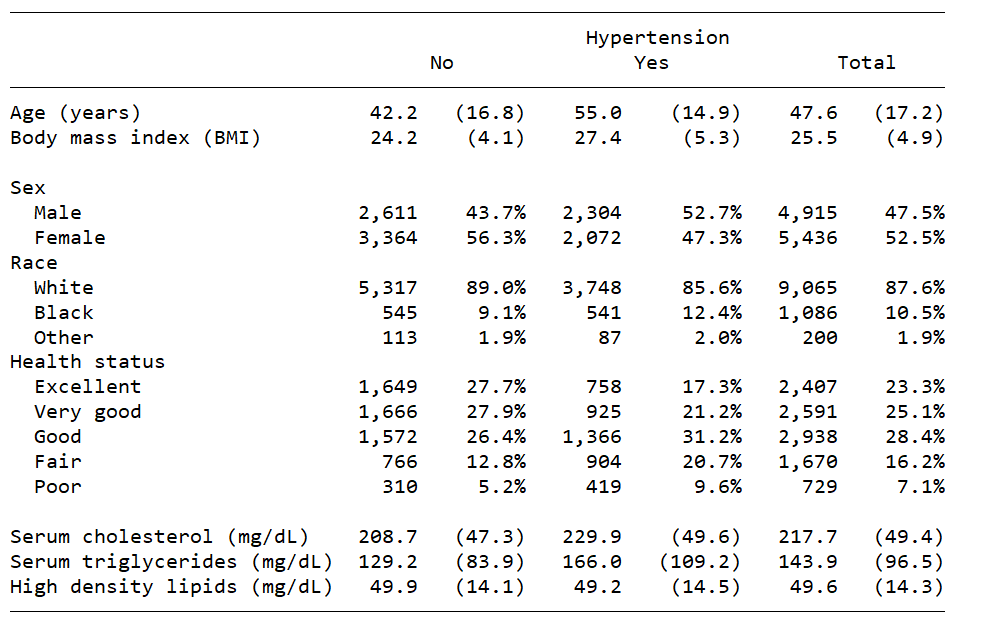
Đây là dạng bảng phổ biến nhất trong các báo cáo nghiên cứu, thường dùng để mô tả đặc điểm mẫu và phân tách theo một biến phân loại. Bảng này báo cáo giá trị trung bình và độ lệch chuẩn cho các biến liên tục, đồng thời hiển thị tần suất và tỷ lệ phần trăm cho các biến phân loại.
Bảng Kết Quả Kiểm Định Thống Kê
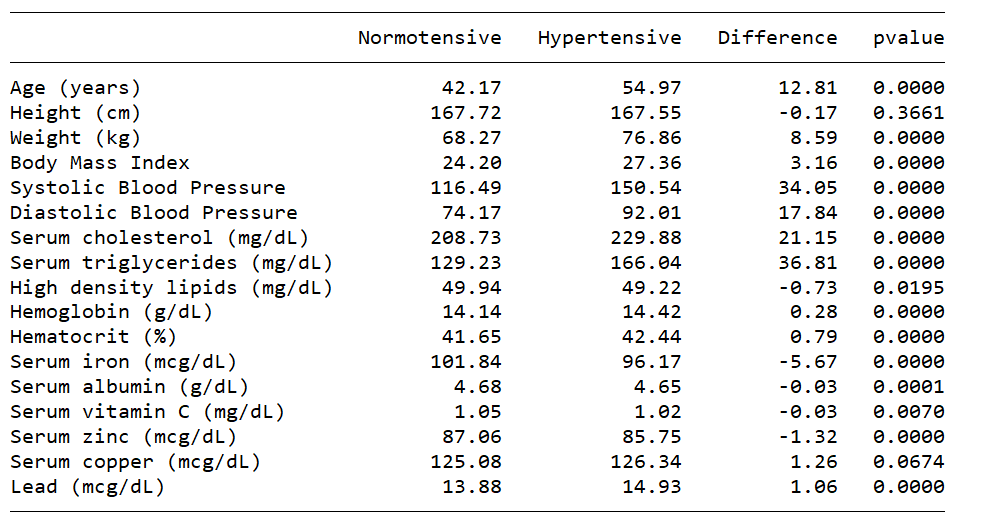
Trong nhiều trường hợp, chúng ta cần báo cáo kết quả kiểm định giả thuyết cho một nhóm biến. Hệ thống mới cho phép trình bày giá trị trung bình của các nhóm, sự khác biệt giữa chúng và giá trị p-value của các kiểm định t-test một cách chuyên nghiệp.
Bảng So Sánh Các Mô Hình Hồi Quy
Khi thực hiện phân tích, việc so sánh kết quả từ nhiều mô hình hồi quy khác nhau là rất quan trọng. Bạn có thể tạo bảng hiển thị tỷ số chênh và sai số chuẩn của các biến độc lập trong nhiều mô hình hồi quy logistic, đi kèm với các chỉ số đánh giá như AIC và BIC để so sánh.
Bảng Chi Tiết Cho Một Mô Hình Hồi Quy
Đối với mô hình hồi quy cuối cùng, bạn có thể cần một bảng chi tiết bao gồm tỷ số chênh, sai số chuẩn, giá trị z, p-value và khoảng tin cậy 95 phần trăm cho từng biến số.
Chuẩn Bị Dữ Liệu Phân Tích
Chúng ta sẽ sử dụng bộ dữ liệu từ Khảo sát Kiểm tra Sức khỏe và Dinh dưỡng Quốc gia để thực hành. Đầu tiên, hãy mở dữ liệu và xem qua các biến số chính.
1webuse nhanes2l
2describe age sex race height weight bmi highbp bpsystol bpdiast tcresult tgresult hdresultBộ dữ liệu này bao gồm các số liệu về nhân trắc học và sinh học của những người tham gia khảo sát tại Hoa Kỳ. Để đơn giản hóa trong bài hướng dẫn này, chúng ta sẽ tạm thời bỏ qua trọng số khảo sát và tập trung vào cú pháp tạo bảng.
Làm Quen Với Cú Pháp Lệnh Table
Cú pháp cơ bản của lệnh table là table (Biến hàng) (Biến cột). Nếu bạn chỉ muốn tạo bảng cho một biến hàng duy nhất như biến cao huyết áp, bạn có thể viết như sau:
1table (highbp) ()Theo mặc định, bảng sẽ hiển thị tần suất cho từng danh mục của biến và tổng số. Cặp ngoặc đơn thứ hai để trống vì chúng ta không có biến cột. Nếu bạn muốn đặt biến này ở cột, hãy chuyển nó sang cặp ngoặc đơn thứ hai:
1table () (highbp)Để tạo bảng chéo giữa biến giới tính và cao huyết áp, chúng ta điền biến vào cả hai vị trí. Tổng hàng và tổng cột sẽ được tự động thêm vào.
1table (sex) (highbp)Nếu không muốn hiển thị các dòng tổng cộng, bạn chỉ cần thêm tùy chọn nototals vào sau lệnh.
Cấu Trúc Bảng Lồng Nhau
Stata cho phép lồng ghép nhiều biến số vào hàng hoặc cột. Thứ tự của các biến trong ngoặc đơn sẽ quyết định cấu trúc phân cấp của bảng. Ví dụ, để xem tần suất của giới tính lồng trong các nhóm cao huyết áp, chúng ta sử dụng:
1table (highbp sex) (), nototalsNgược lại, nếu muốn nhóm cao huyết áp lồng trong giới tính, bạn chỉ cần đổi thứ tự biến. Khả năng này cũng áp dụng tương tự cho các biến cột, giúp bạn tạo ra những bảng biểu đa chiều phức tạp một cách dễ dàng.
Tùy Chỉnh Thống Kê Và Định Dạng Số Liệu
Mặc dù tần suất là giá trị mặc định, bạn có thể yêu cầu bất kỳ chỉ số thống kê nào thông qua tùy chọn statistic.

1table (sex) (highbp), statistic(frequency) statistic(percent) nototalsBạn cũng có thể thêm giá trị trung bình hoặc độ lệch chuẩn của biến tuổi vào bảng. Để các con số trông chuyên nghiệp hơn, tùy chọn nformat sẽ giúp định dạng chữ số thập phân, trong khi sformat có thể thêm các ký hiệu như dấu phần trăm hoặc dấu ngoặc đơn xung quanh số liệu.
1table (sex) (highbp), statistic(frequency) statistic(percent) statistic(mean age) statistic(sd age) nototals nformat(%9.0fc frequency) nformat(%6.2f mean sd) sformat("%s%%" percent) sformat("(%s)" sd)Áp Dụng Phong Cách Trình Bày Chuyên Nghiệp
Cuối cùng, Stata cung cấp các kiểu dáng có sẵn để bạn áp dụng nhanh chóng. Tùy chọn style cho phép thay đổi diện mạo của bảng ngay lập tức, ví dụ như kiểu trình bày chuẩn cho các bài báo khoa học.

1table (sex) (highbp), statistic(frequency) statistic(percent) statistic(mean age) statistic(sd age) nototals nformat(%9.0fc frequency) nformat(%6.2f mean sd) sformat("%s%%" percent) sformat("(%s)" sd) style(table-1)Lệnh table mới trong Stata 17 đã thực sự thay đổi cách chúng ta làm việc với dữ liệu. Từ việc tạo bảng chéo đơn giản đến những bảng thống kê phức tạp, mọi thứ đều có thể được thực hiện một cách nhất quán và thẩm mỹ.
✨ Khả năng tùy biến bảng biểu trong Stata 17 không chỉ giúp tiết kiệm thời gian trình bày mà còn đảm bảo tính chính xác và đồng nhất cho các báo cáo nghiên cứu khoa học.
Bài tập ứng dụng
Dựa trên bộ dữ liệu nhanes2l đã mở, bạn hãy viết lệnh tạo một bảng biểu hiển thị giá trị trung bình của biến chỉ số khối cơ thể (bmi) và biến nồng độ cholesterol (tcresult) theo từng nhóm chủng tộc (race). Yêu cầu bảng không hiển thị dòng tổng cộng và các giá trị số được định dạng lấy hai chữ số thập phân.

