
1. Giới thiệu
Trong bài viết này, chúng ta sẽ cùng nhau khám phá cách sử dụng ngôn ngữ lập trình R để trực quan dữ liệu bản đồ Việt Nam một cách rõ ràng và dễ hiểu. Bạn sẽ được tìm hiểu cách thể hiện các thông tin thông qua bản đồ (Ví dụ, biểu đồ chỉ số cấp tỉnh, mật độ dân số, …).
Đặc biệt, bài viết này cũng sẽ cung cấp hình ảnh đầy đủ về Hoàng Sa và Trường Sa - những quần đảo quan trọng của Việt Nam.
Kết quả sau khi thực hiện trong R
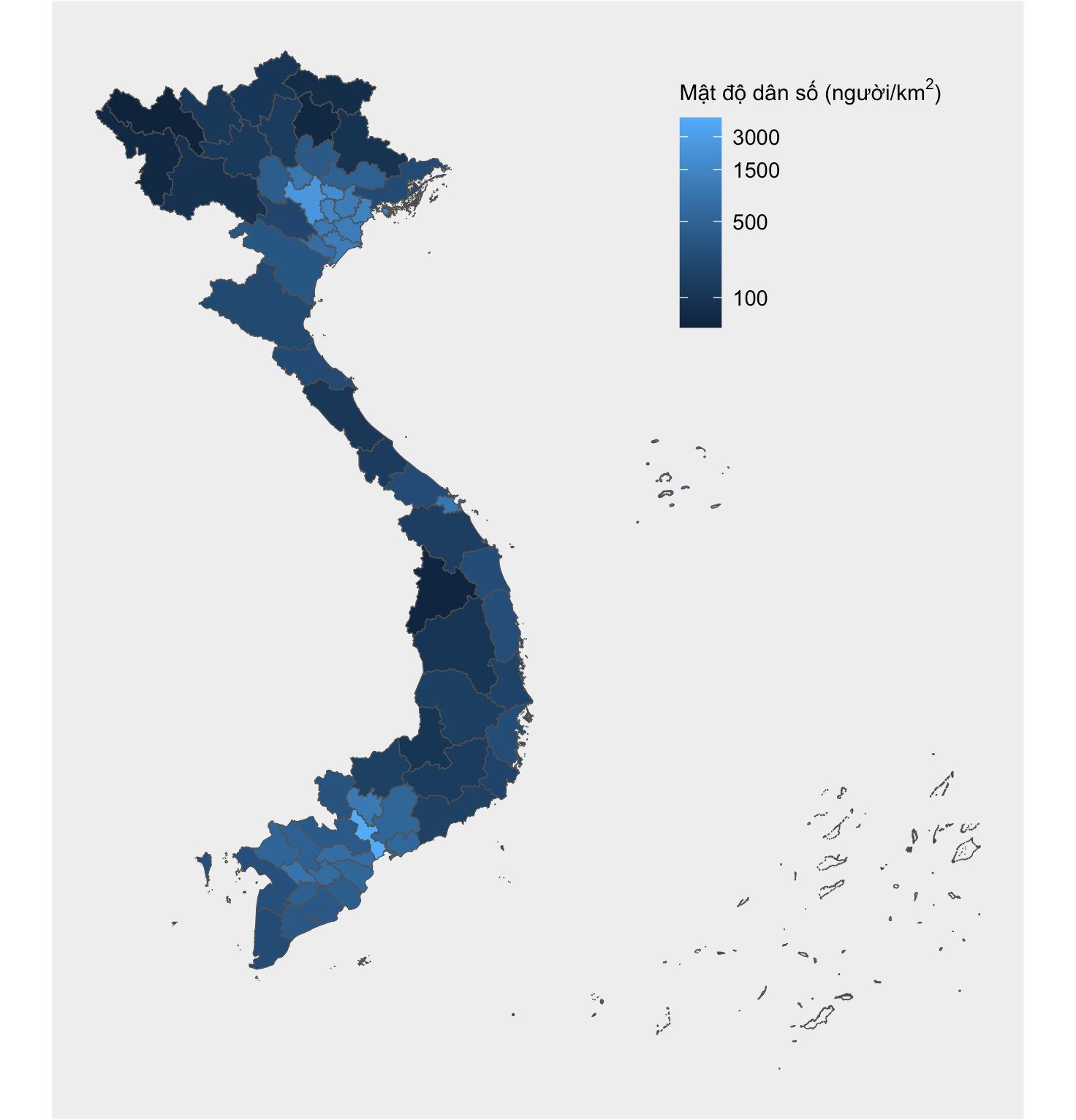
Trực quan hóa dữ liệu bản đồ là một công cụ mạnh mẽ giúp chúng ta hiểu và thể hiện thông tin phức tạp một cách dễ hiểu. Một số công cụ phổ biến như Excel cung cấp tích hợp khả năng trực quan hóa dữ liệu bản đồ. Tuy nhiên, vẫn còn nhiều thách thức cần giải quyết.
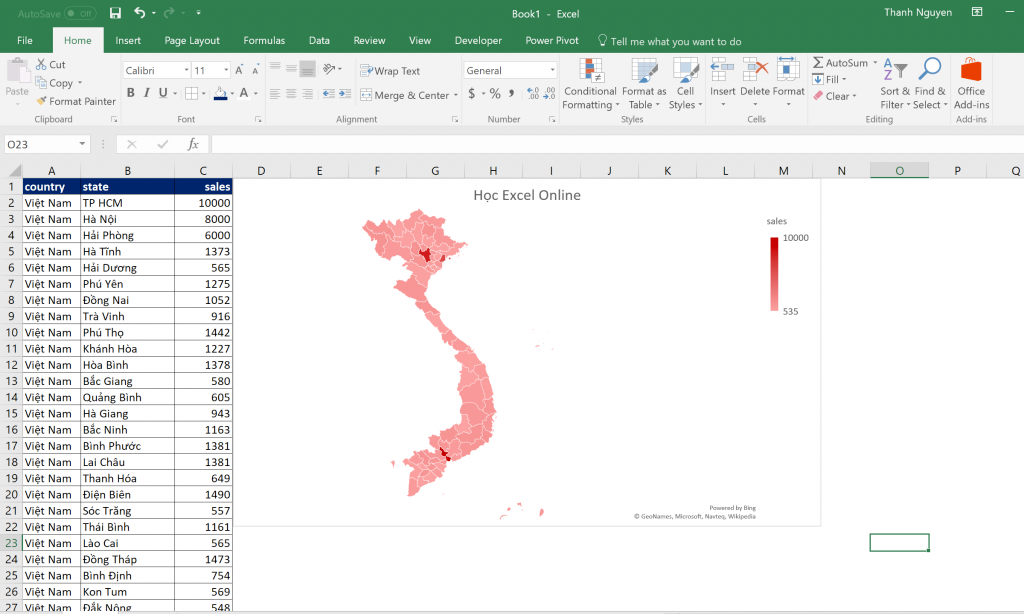
1. Công cụ Trực Quan Dữ liệu Bản đồ:
Công cụ như Excel cung cấp khả năng tạo biểu đồ dạng bản đồ để thể hiện dữ liệu dưới góc độ địa lý. Tuy nhiên, các công cụ này thường hạn chế về tính tùy chỉnh và khả năng trực quan hóa dữ liệu phức tạp. Điều này đặc biệt đúng đối với các dataset lớn và phức tạp.
2. Thiếu Hoàng Sa và Trường Sa:
Một thách thức khác là việc trình bày thông tin liên quan đến các quần đảo quan trọng như Hoàng Sa và Trường Sa. Đây là các địa danh mang ý nghĩa lịch sử và chủ quyền của Việt Nam, nhưng thường bị thiếu hoặc bị biểu đạt không chính xác trong một số nguồn trực quan hóa dữ liệu.
3. Khó tiếp cận với Dataset lớn:
Với sự phát triển của khoa học dữ liệu và công nghệ, các dataset ngày càng trở nên lớn và phức tạp. Điều này tạo ra thách thức trong việc trực quan hóa dữ liệu này thành các biểu đồ và bản đồ dễ hiểu. Việc xử lý và trình bày thông tin từ các dataset lớn cần sự hỗ trợ của các công cụ và phương pháp thích hợp.
2. Dữ liệu bản đồ
Dữ liệu bản đồ được sử dụng được lấy tại data.opendevelopmentmekong.net. Đây là nguồn cung cấp dữ liệu về bản đồ Việt Nam có đầy đủ về Hoàng Sa và Trường Sa
Dạng dữ liệu để lưu thông tin bản đồ được lưu dạng GeoJSON hoặc Shapefile
Trường hợp này tác giả sử dụng dạng GeoJSON
Tác giả sử dụng package sf hỗ trợ đọc file dữ liệu bản đồ
1library(sf)
2URL <- 'https://data.opendevelopmentmekong.net/dataset/55bdad36-c476-4be9-a52d-aa839534200a/resource/b8f60493-7564-4707-aa72-a0172ba795d8/download/vn_iso_province.geojson'
3vietnam <- st_read(URL)
4View(vietnam)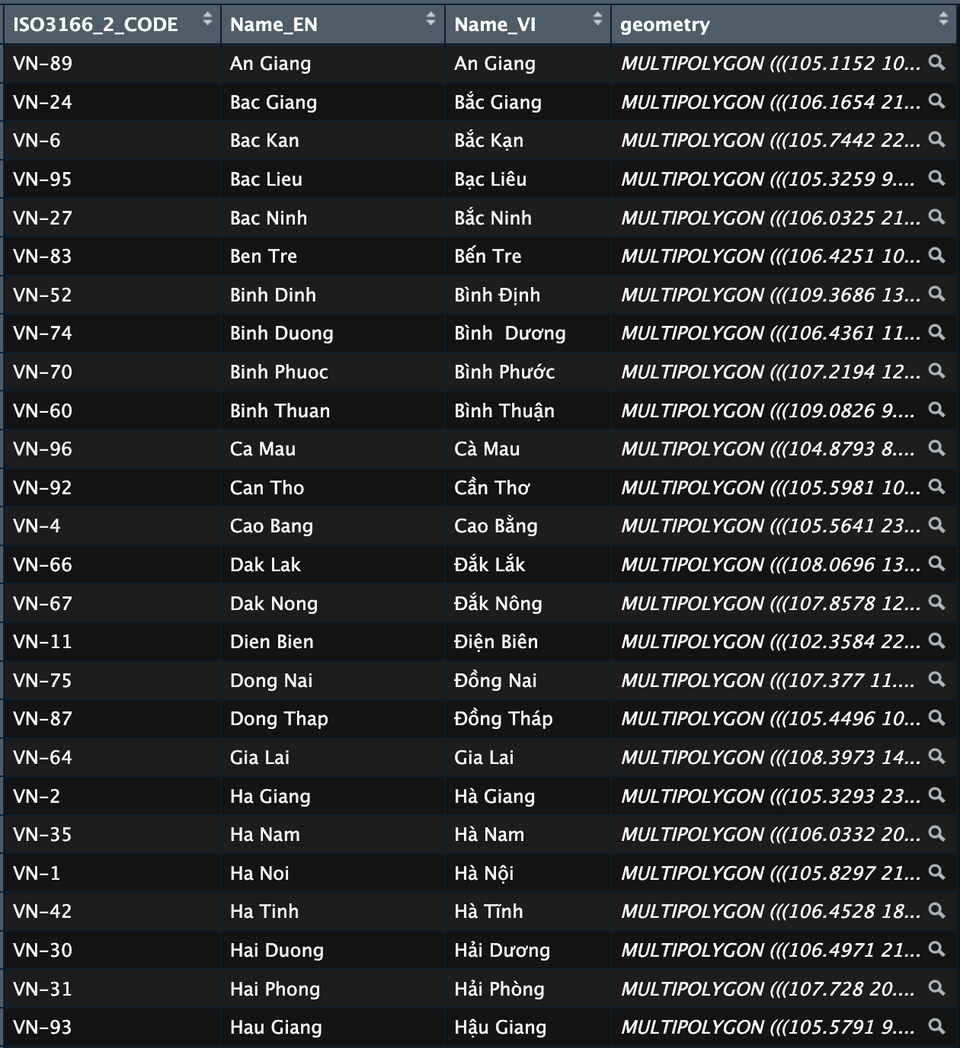
Sử dụng package ggplot2 vẽ bản đồ với hàm geom_sf()
1ggplot(vietnam) +
2 geom_sf()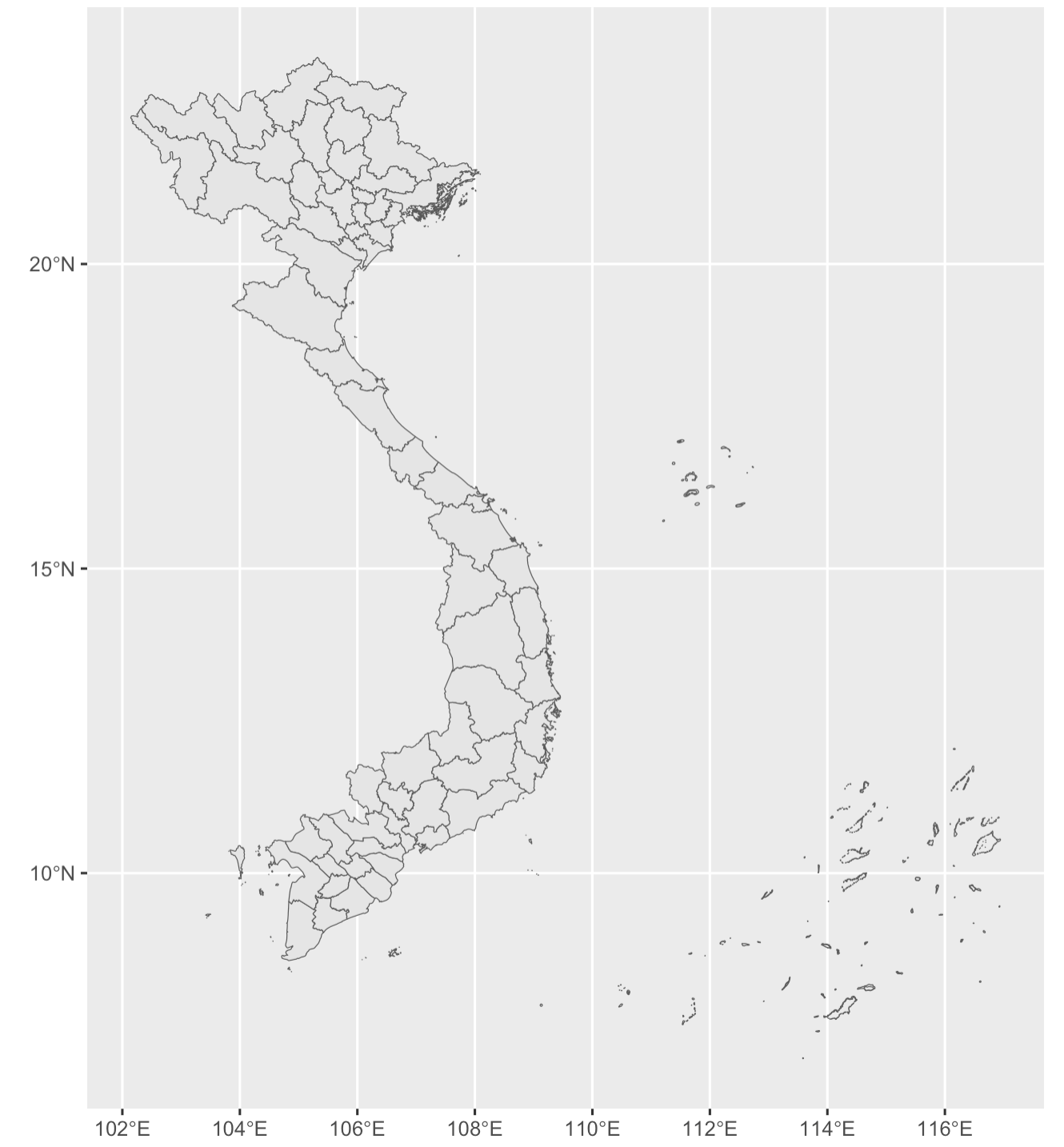
Vẽ màu theo các tỉnh, dùng cột Name_VI có trong dữ liệu bản đồ
1ggplot(vietnam) +
2 geom_sf(aes(fill=Name_VI))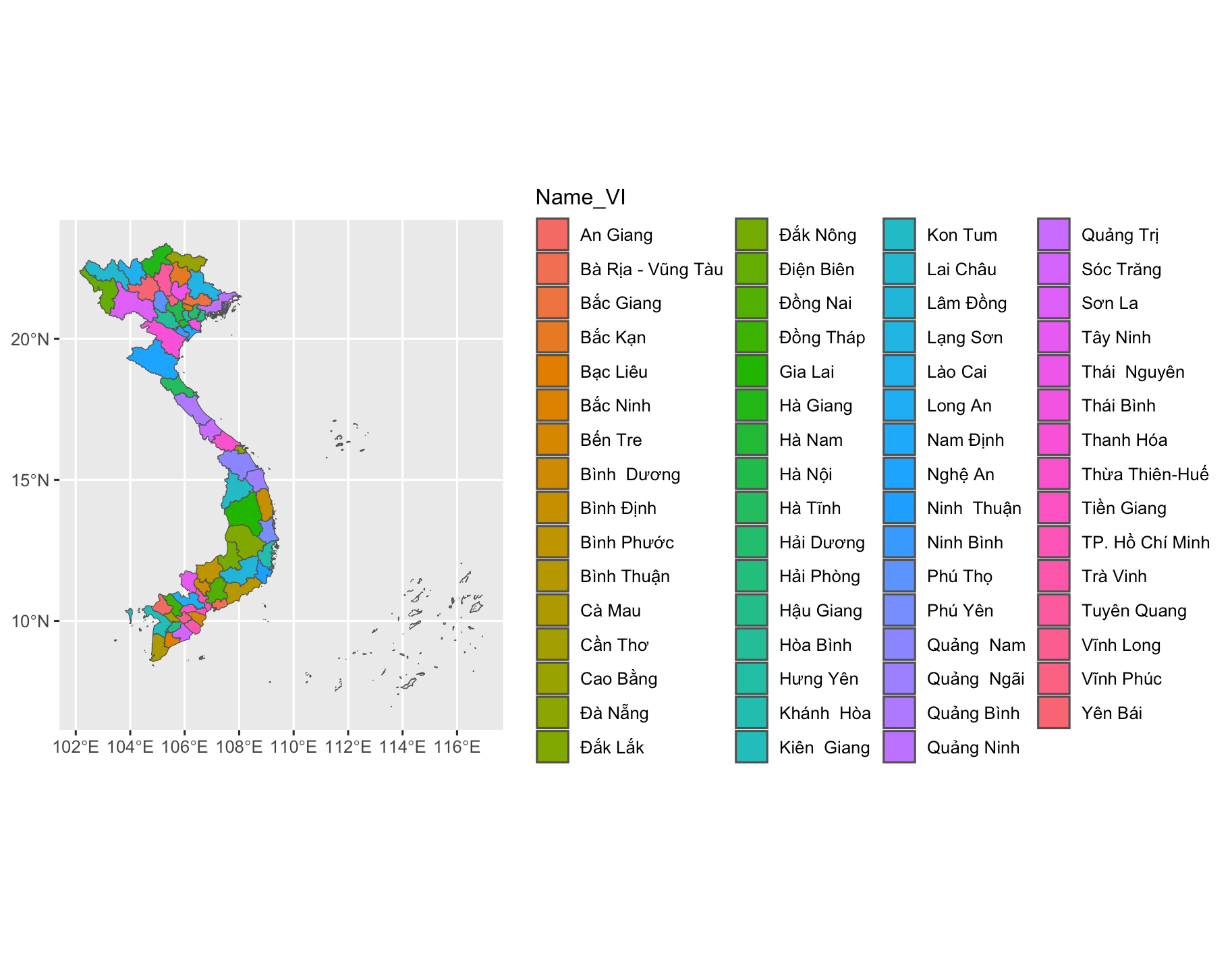
Vì trong dữ liệu bản đồ chưa có thông tin về mật độ dân số, ta sử dụng dữ liệu được lấy tại tổng cục thống kê, truy cập vào dữ liệu tại đây
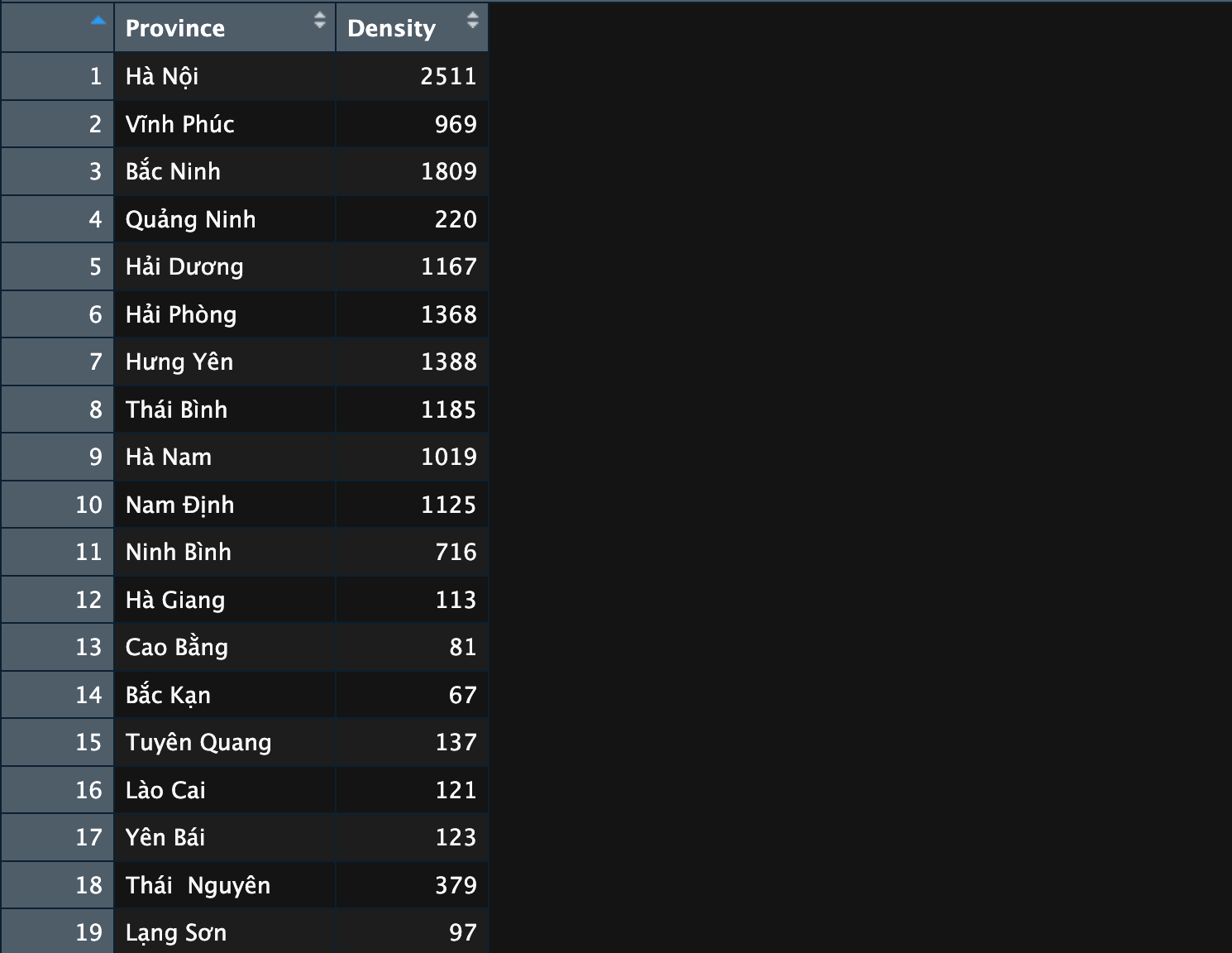
Sử dụng package readxl để đọc dữ liệu từ file excel
1library(readxl)
2vn_density <- read_xlsx('~/Desktop/vn_density.xlsx')Sử dụng hàm left_join() trong package dplyr để merge dữ liệu bản đồ với dữ liệu mật độ dân số với nhau
1library(dplyr)
2vietnam <- vietnam %>%
3 left_join(vn_density, by=c('Name_VI' = 'Province'))Lúc này trong dữ liệu bản đồ đã có thông tin mật độ dân số tại cột
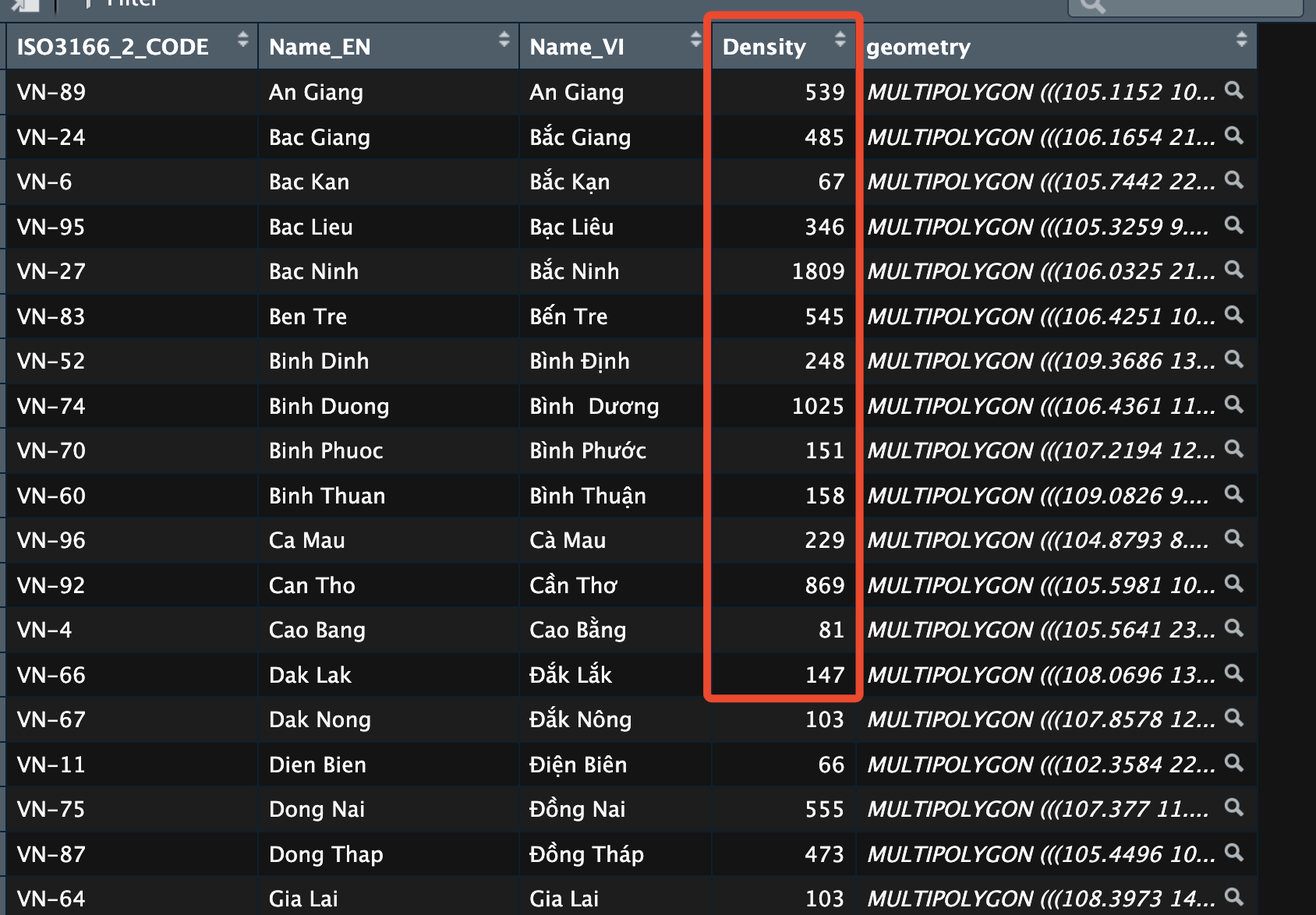
1library(latex2exp) # TeX() function
2ggplot(vietnam) +
3 geom_sf(aes(fill=Density)) +
4 scale_fill_gradient(
5 trans='log',
6 breaks=c(100, 500, 1500, 3000),
7 name=TeX('Mật độ dân số (người/$\\km^{2}$)')
8 )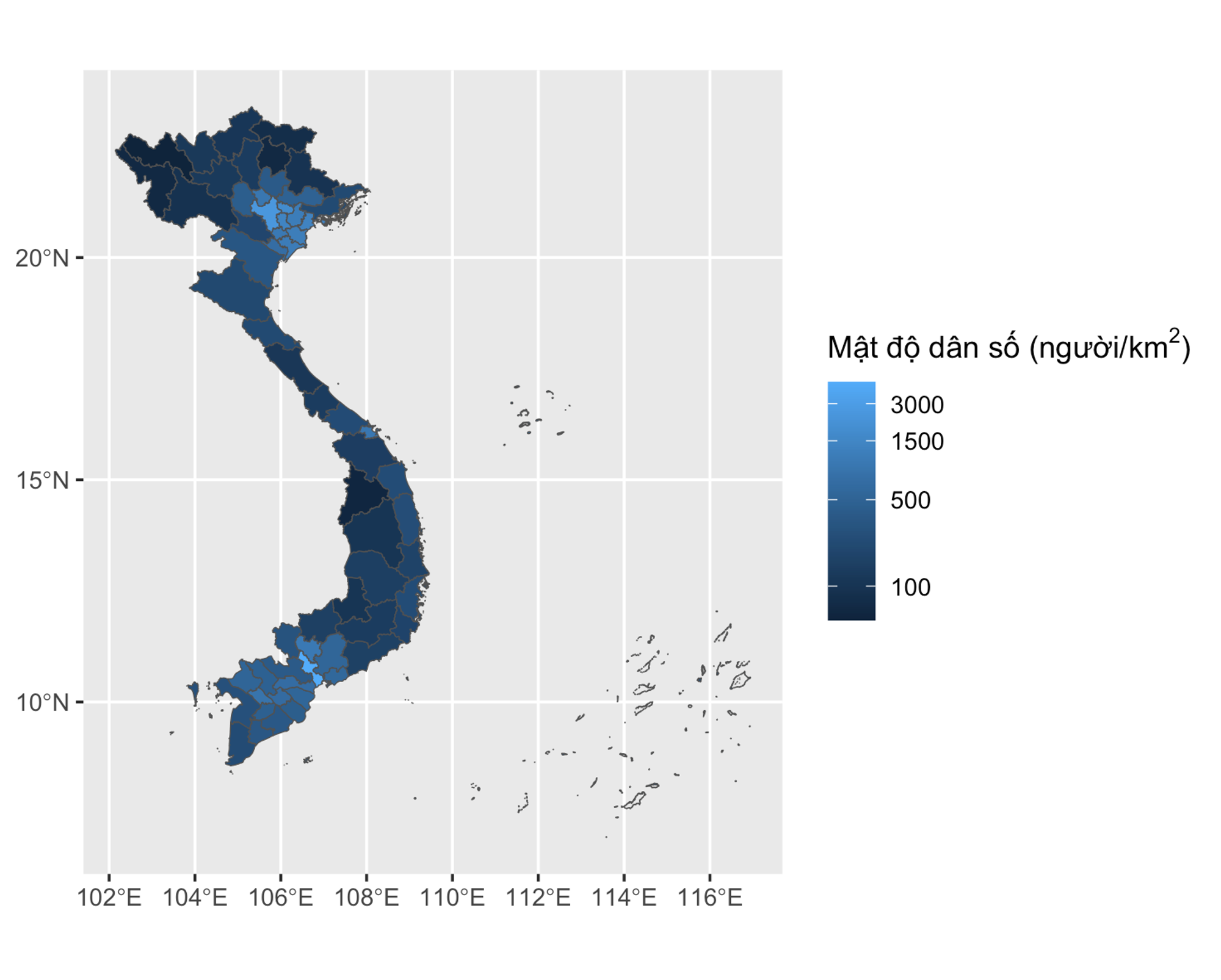
Chỉnh sửa màu sắc và vị trí của chú thích bản đồ, ta có kết quả như sau
1ggplot(vietnam) +
2 geom_sf(aes(fill=Density)) +
3 scale_fill_gradient(
4 trans='log',
5 breaks=c(100, 500, 1500, 3000),
6 name=TeX('Mật độ dân số (người/$\\km^{2}$)')
7 ) +
8 theme_void() +
9 theme(
10 legend.position = c(0.78, 0.82),
11 legend.title = element_text(size=9),
12 plot.background = element_rect(fill='#eeeeee', colour='white')
13 )#VisualizingVietnamMap #HoangSaTruongSa #R

