1. Biểu đồ hộp là gì?
Biểu đồ hộp là một công cụ rất phổ biến trong trực quan hóa dữ liệu. Biểu đồ hộp được sử dụng rộng rãi để tổng hợp và hiển thị các đặc điểm quan trọng của dữ liệu
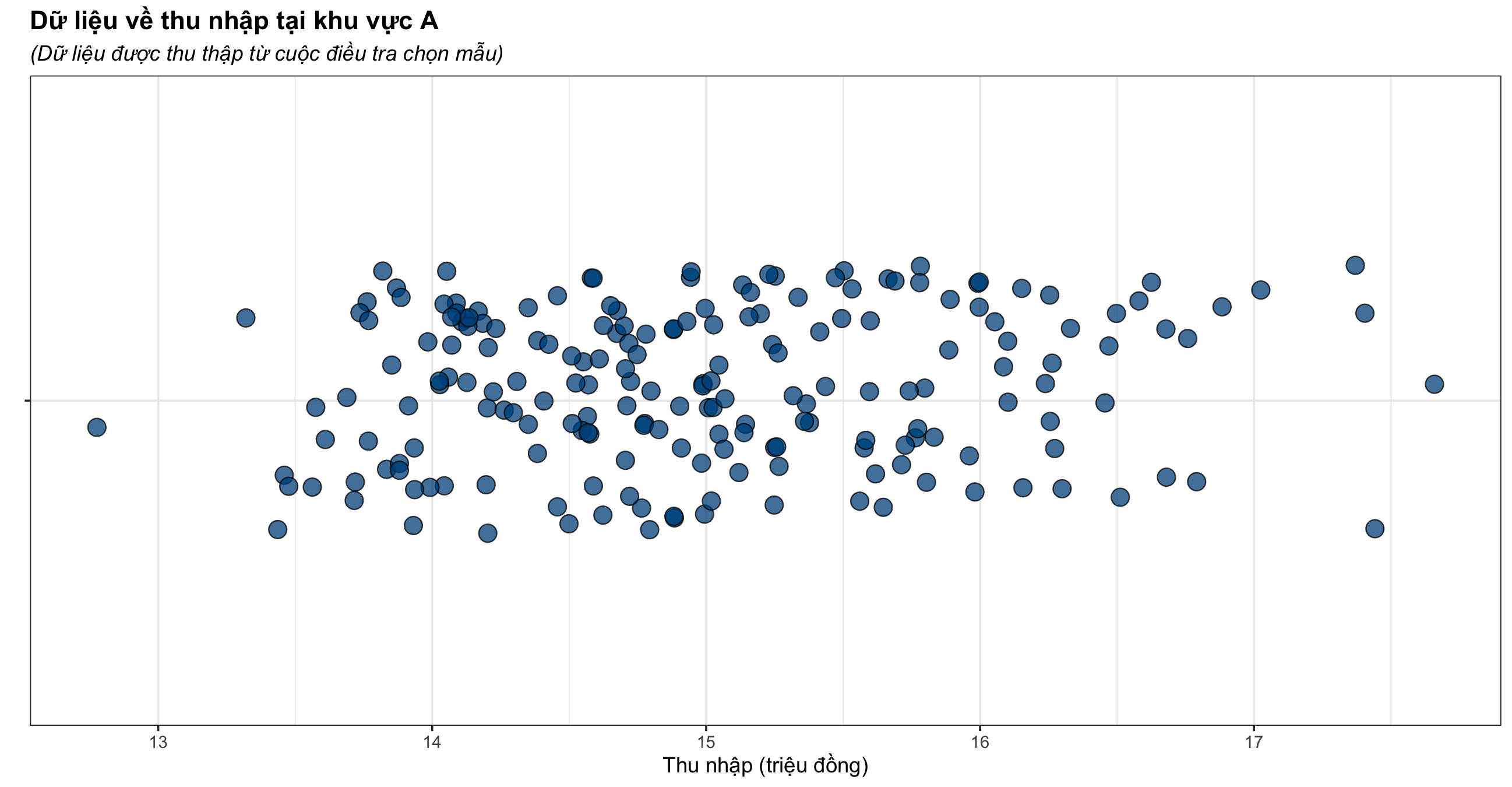
Để hiểu rõ về biểu đồ hộp, bạn hãy xem qua ví dụ sau. Giả sử bạn đang phân tích dữ liệu về thu nhập của nhóm đối tượng bạn đang khảo sát.
Bạn có thể quan tâm
- Thu nhập cao nhất và thấp nhất là bao nhiêu,
- 25% mức thu nhập nhỏ nhất
- 50% mức thu nhập trung bình
- 25% mức thu nhập cao nhất
- Các thu nhập đột xuất (bất thường)
Để biết được các thông tin trên, về cơ bản ta có thể sử dụng biểu đồ hộp.
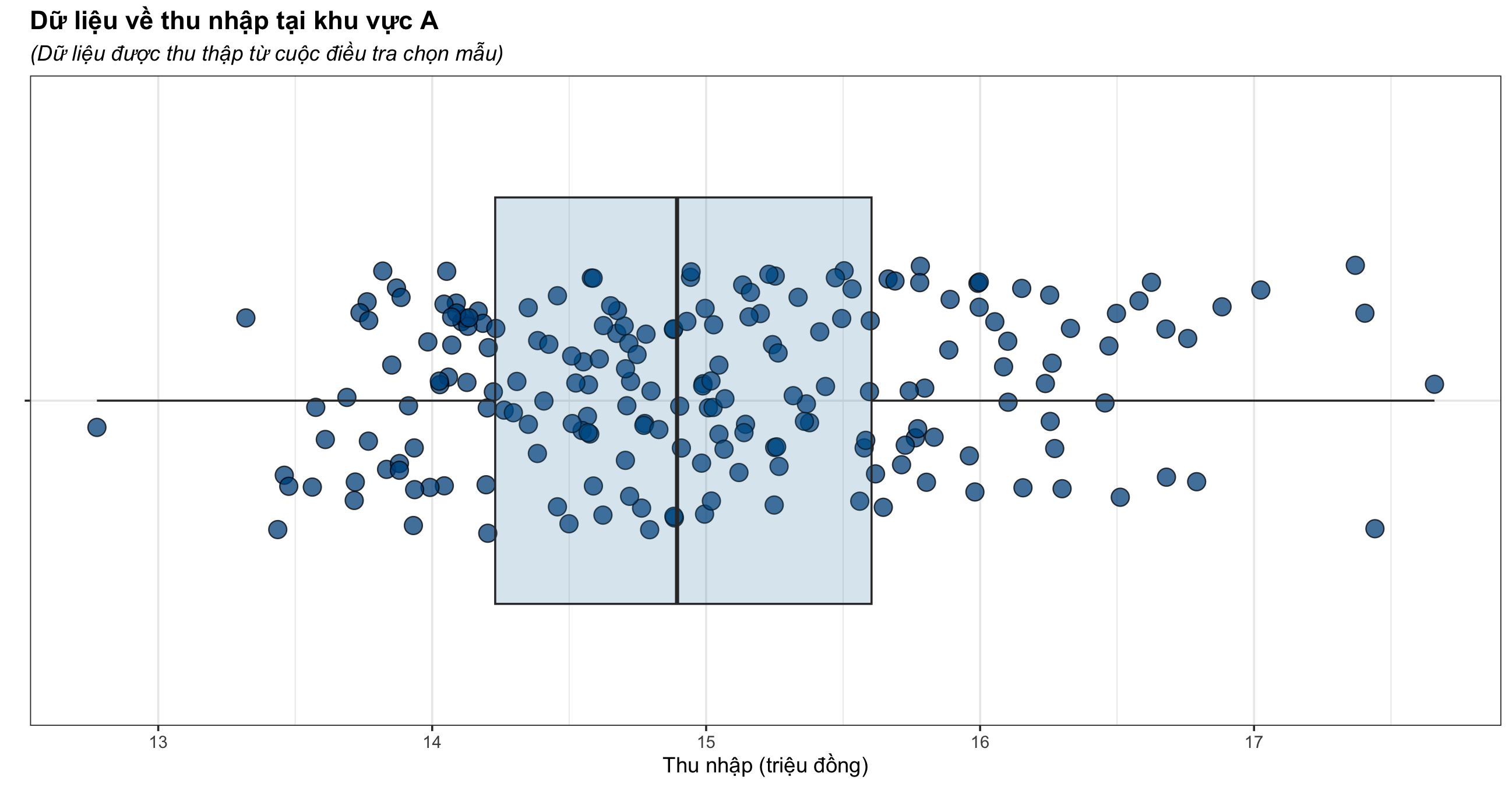
Cụ thể với nhìn trên biểu đồ hộp, ta thấy được:
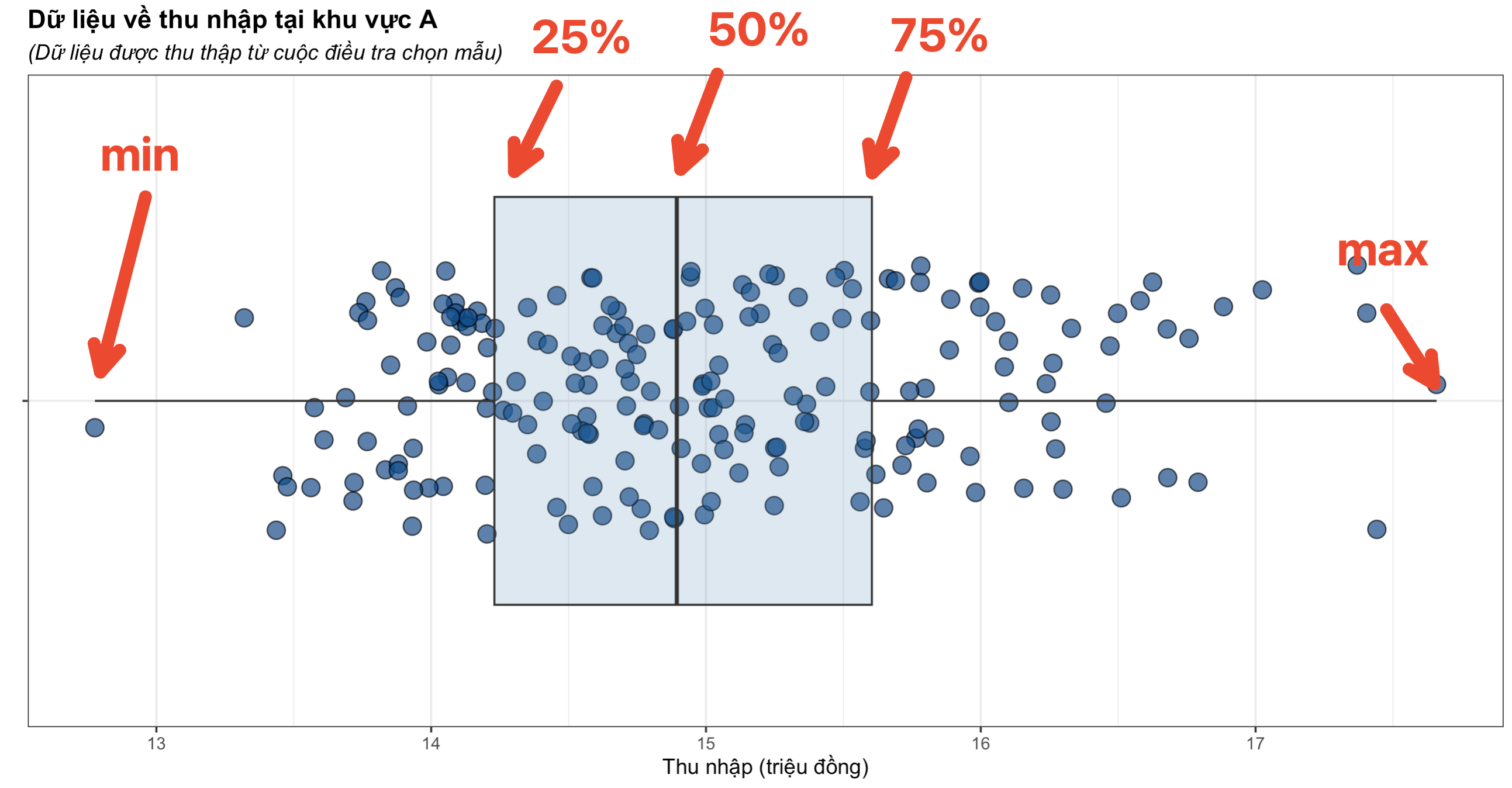
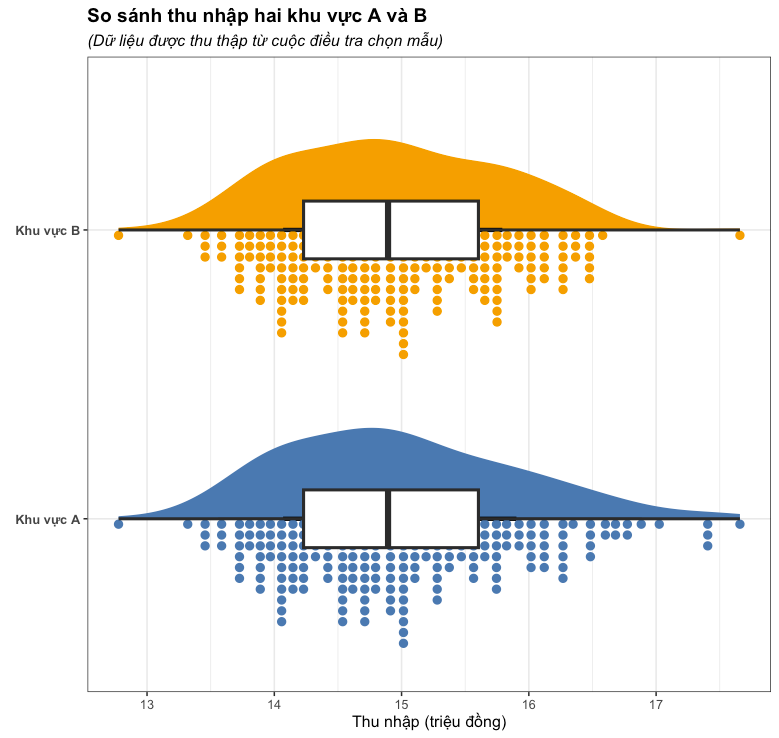
Tại hai đầu của trái phải của râu hộp (Whisker) biểu thị giá trị thấp nhất và cao nhất, trường hợp này là thu nhập thấp nhất (12.7 triệu đồng) và thu nhập cao nhất (17.6 triệu đồng).
Tại 2 đầu trái phải hộp, là mức phân vị 25 và phân vị 75 của dữ liệu, trong đó:
- Phân vị 25 (14.2 triệu đồng): là 25% mức thu nhập nhỏ nhất, hay có nghĩa là khoảng 25% người được khảo sát có mức thu nhập nhỏ hơn hoặc bằng 14.2 triệu đồng.
- Phân vị 75 (15.6 triệu đồng): ngược lại là 25% mức thu nhập lớn nhất, hay có nghĩa là khoảng 75% người được khảo sát có mức thu nhập nhỏ hơn hoặc bằng 15.6 triệu đồng, hoặc ta cũng có thể hiểu ngược lại rằng có khoảng 25% người được khảo sát có mức thu nhập lớn hơn hoặc bằng mức thu nhập này.
Tại đường thẳng ở chính giữa hộp, đây là mức phân vị 50 hay còn gọi là Trung vị (14.8 triệu đồng). Ta có thể hiểu rằng có khoảng 50% người được khảo sát có mức thu nhập nhỏ hơn hoặc bằng 14.8 triệu đồng
Ta thấy rằng biểu đồ hộp là biểu đồ rất đơn giản nhưng vẫn có thể đem lại rất nhiều thông tin quan trọng về dữ liệu. Tuy nhiên vì sự tiện dụng mà có rất nhiều phân tích đã lạm dụng biểu đồ này trong phân tích. Dưới đây là lý do tại sao bạn không bên lạm dụng biểu đồ hộp trong phân tích của mình.
2. Tại sao bạn không nên lạm dụng biểu đồ hộp?
Bạn hãy thử nghĩ về cách để vẽ được biểu đồ hộp. Thực chất việc vẽ biểu đồ này rất đơn giản:
- Đầu tiên bạn cần sắp xếp tất cả dữ liệu mà bạn có theo thứ tự tăng dần.
- Giả sử bạn có khoảng 100 điểm dữ liệu, tất cả những gì cần để vẽ biểu đồ hộp là điểm nhỏ nhất, điểm phân vị thứ 25, 50 và 75 và điểm lớn nhất.
Vị trí hay mật độ của các điểm dữ liệu khác ở giữa 5 điểm trên không quan trọng đối với biểu đồ hình hộp. Biểu đồ hộp vẫn không thay đổi miễn là các điểm dữ liệu có thể thay đổi vị trí tùy thích miễn là nó vẫn nằm trong phạm vi của hai điểm chính mà chúng nằm ở giữa.
Ví dụ ta có điểm A là điểm nằm giữa phân vị 25 và trung vị. Như vậy dù điểm A có tăng hay giảm đi miễn là vẫn nằm giữa phân vị 25 và trung vụ thì biểu đồ hộp vẫn không đổi
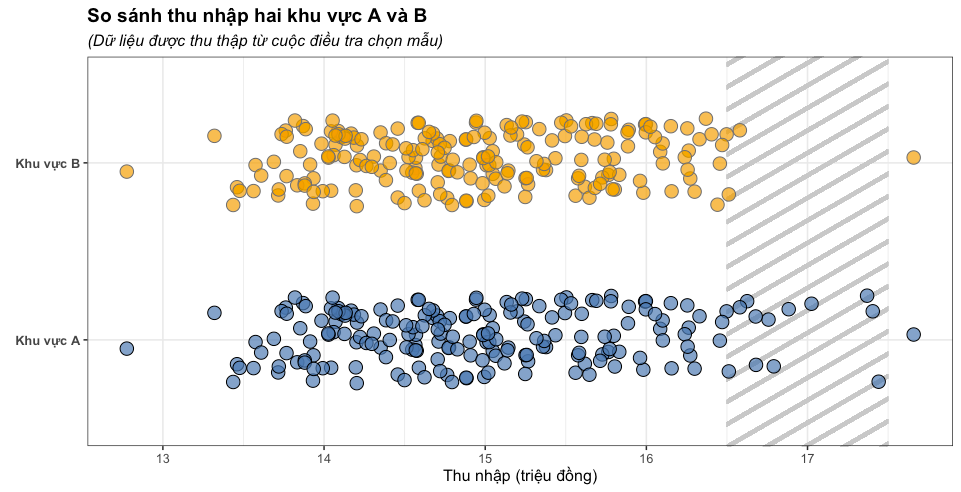
Theo ví dụ trên giả sử ta thu thập dữ liệu của khu vực A và B, nếu ta chỉ dùng box plot thì có thể thấy thu nhập ở hai thu vực này tương đồng với nhau.
Nhưng khi quan sát kỹ hơn, ta thấy được thực thế thu nhập ở khu vực A nhỉnh hơn so với khu vực B, do đó nếu chỉ sử dụng boxplot ta khó để có thể thấy sự khác biệt này.
Để rõ hơn ta xem hình minh hoạ sau, nguồn: Albert Rapp (2024)
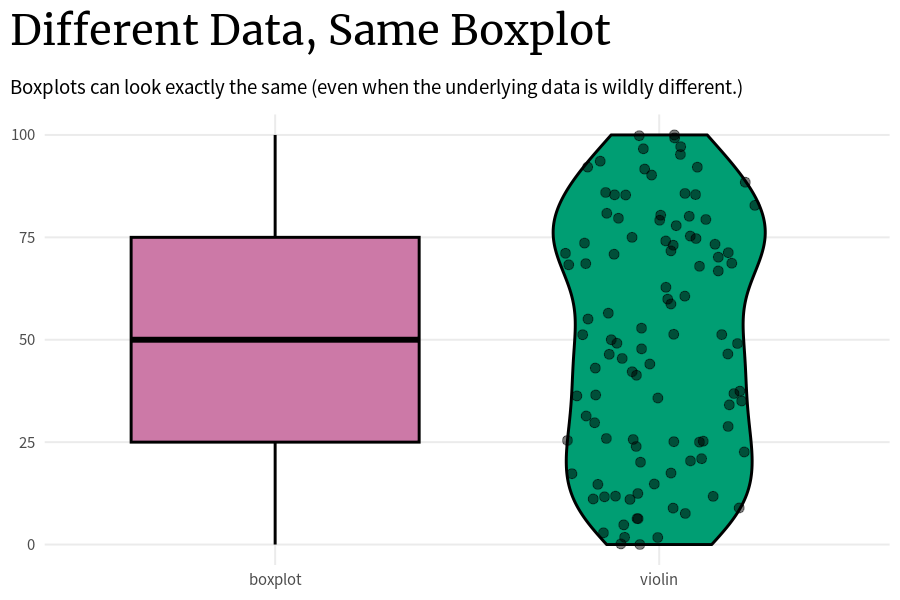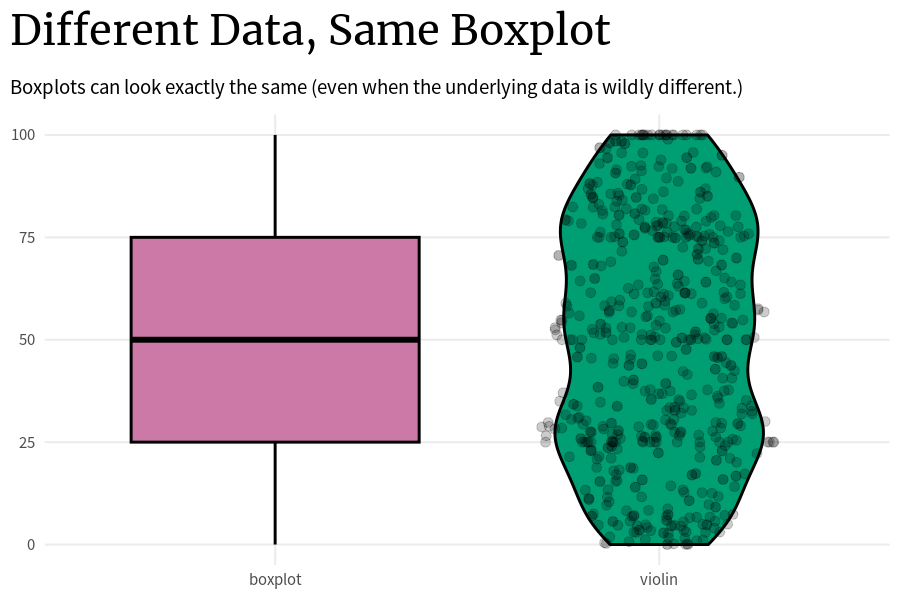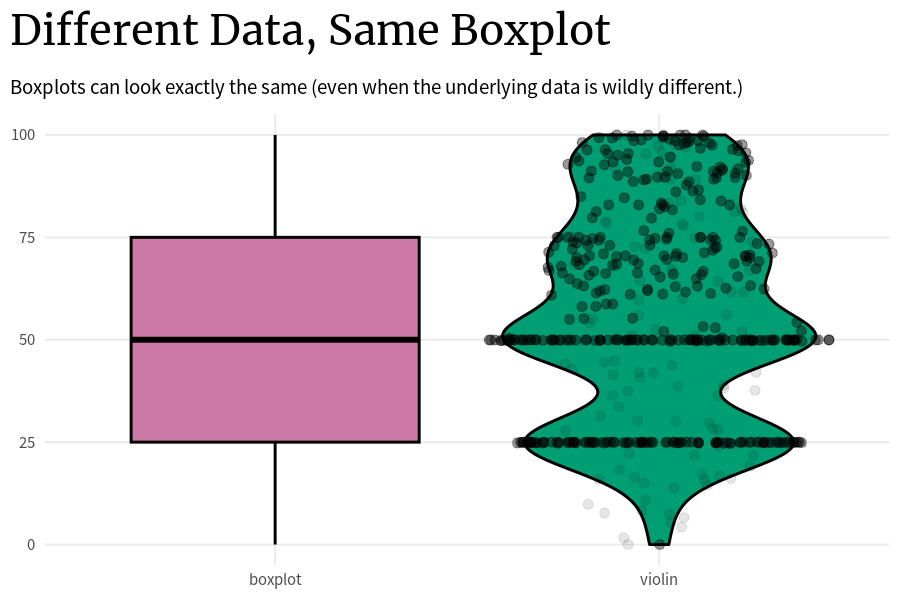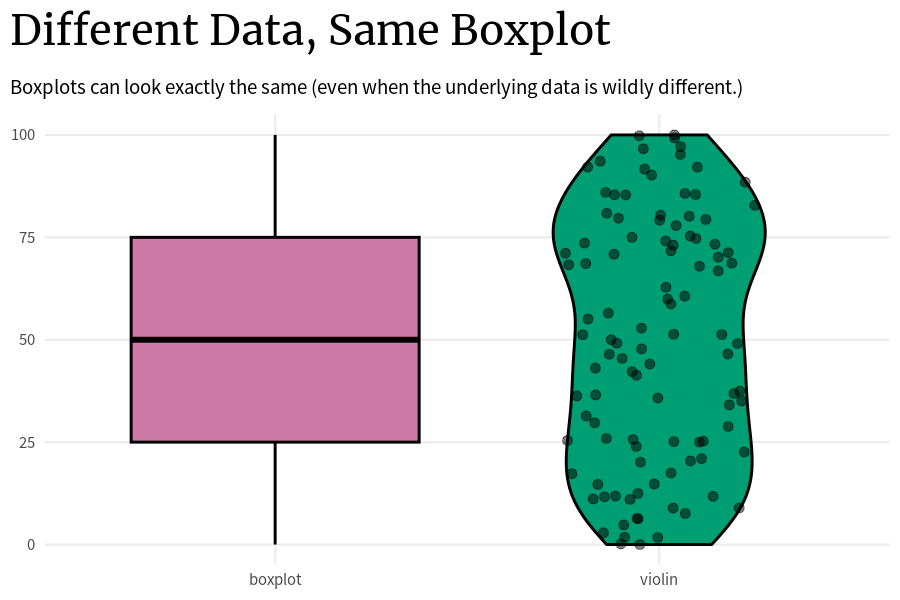
Different Data, Same Boxplot (Albert Rapp, 2024)
Vì vậy, đó là lý do tại sao việc chỉ dựa vào biểu đồ hộp thường không tốt. Thay vào đó, ta có thể kết hợp thêm vào biểu đồ hộp như biểu đồ đàn violin để hiển thị chi tiết hơn sự phân bổ thay vì chỉ dựa các đại lượng chính như phân vị hay lớn nhất nhỏ nhất.
Bạn có thể tìm hiểu cách sử dụng hàm geom_violin để vẽ biểu đồ này.
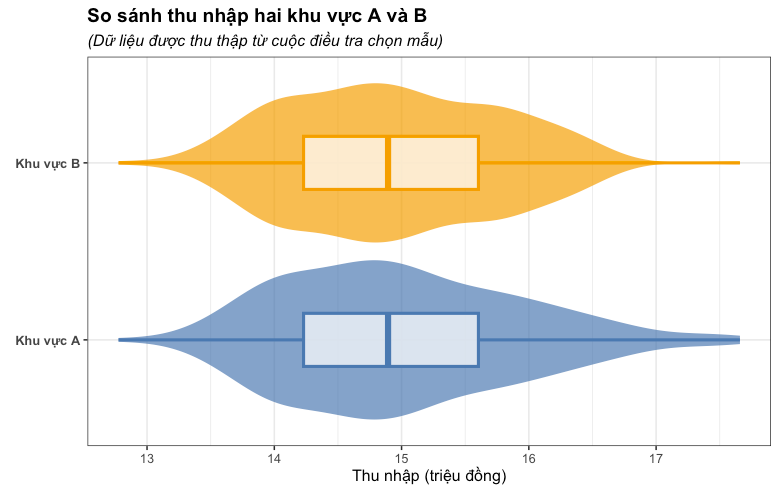
Hoặc thậm chí xa hơn là kết hợp biểu đồ mưa (raincloud plot) vào biểu đồ hình hộp để hiển thị dữ liệu rõ ràng hơn.
Bạn có thể tìm hiểu hàm stat_halfeye và stat_dots trong thư việt ggdist để vẽ biểu đồ này.