1. Các thành phần của chuỗi thời gian
Một chuỗi thời gian bất kỳ có thể chứa các thành phần sau:
Thành phần xu hướng - trend: Một xu hướng tồn tại khi dữ liệu tăng hoặc giảm trong dài hạn. Điều này có thể phát hiện thông qua độ dốc của dữ liệu trên biểu đồ.
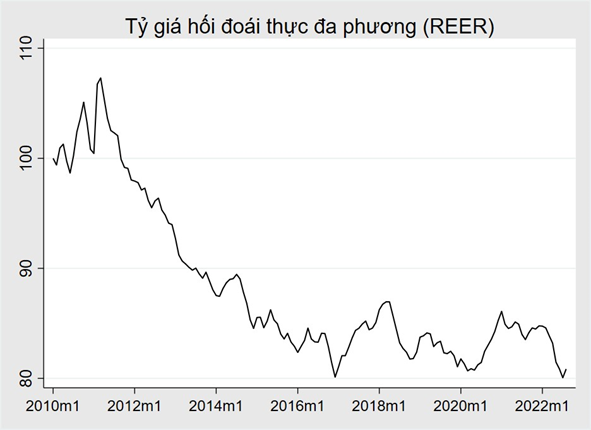
Ví dụ: Tỷ giá hối đoái thực đa phương của Việt Nam có xu hướng giảm.
Thành phần thời vụ - seasonality: Thành phần này xảy ra khi một chuỗi thời gian bị ảnh hưởng bởi các yếu tố mùa vụ, ví dụ như các ngày trong tuần, các tháng, quý trong năm. Tính thời vụ luôn xảy ra trong một thời gian cố định và mang tính chất tuần hoàn.
Thành phần chu kỳ - cycle: Thành phần này xảy ra khi dữ liệu tăng và giảm không theo một tần suất cố định. Những biến động này thường do điều kiện kinh tế và thường liên quan đến “chu kỳ kinh doanh”. Một chu kỳ thường lặp lại ít nhất sau khoảng 2 năm.
Nhiều người hay nhầm lẫn giữa tính chu kỳ và tính mùa vụ, nhưng chúng thực sự khác nhau. Nếu các biến động này không có thời gian cố định thì có tính chu kỳ; nếu sự biến động này lặp lại tuần hoàn theo khía cạnh mùa vụ thì gọi là tính thời vụ. Nhìn chung, thời đoạn lặp lại của chu kỳ dài hơn tính mùa vụ và cường độ thay đổi của các chu kỳ cũng mạnh hơn nhiều so với tính thời vụ.
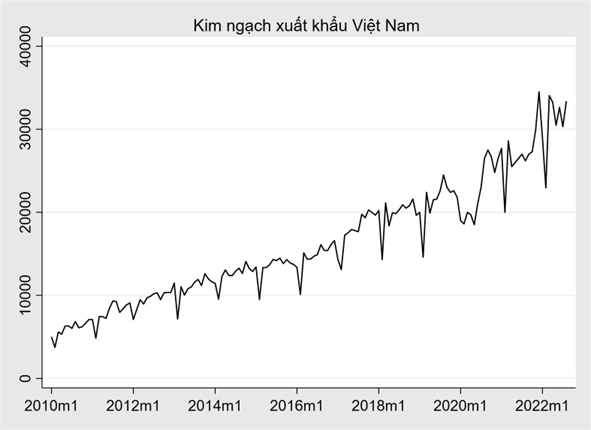
Ví dụ: Kim ngạch xuất khẩu của Việt Nam có xu hướng tăng mạnh với tính thời vụ rõ rệt.
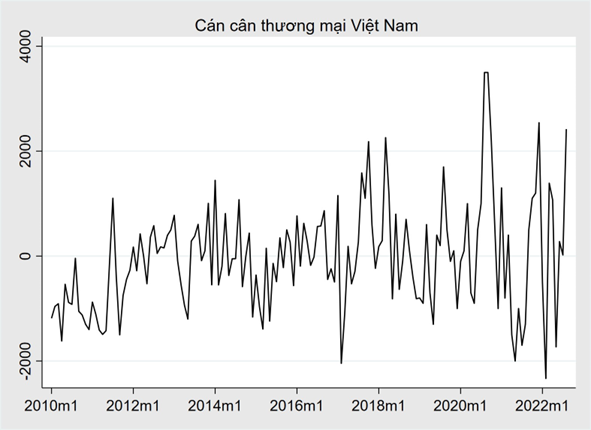
Ví dụ: Cán cân thương mại của Việt Nam cho thấy tính thời vụ mạnh mẽ trong mỗi năm, cũng như một số hành vi chu kỳ mạnh mẽ với khoảng thời gian khoảng 6–10 năm. Không có xu hướng rõ ràng trong dữ liệu trong giai đoạn này.
Tính bất thường - Irregular remainder: hay còn gọi là nhiễu trắng (white noise) thành phần nhiễu còn lại sau khi trích xuất hết các thành phần ở trên, nó chỉ ra sự bất thường của các điểm dữ liệu. Nhiều chuỗi thời gian bao gồm cả tính xu hướng, tính thời vụ và chu kì.
2. Mô hình biểu diễn các thành phần của chuỗi thời gian
2.1. Mô hình dạng tổng
Trong đó:
- là giá trị của thành phần xu hướng tại thời điểm t
- là giá trị của thành phần chu kì tại thời điểm t
- là giá trị của thành phần thời vụ tại thời điểm t
- là giá trị của thành phần ngẫu nhiên, các sai số nhiễu tại thời điểm t
Mô hình dạng tổng hiệu quả trong trường hợp chuỗi dữ liệu đang được phân tích có xu hướng xấp xỉ nhau tính theo chuỗi thời gian.
2.2. Mô hình dạng tích
Mô hình dạng tích hiệu quả trong trường hợp chuỗi dữ liệu được phân tích có sự biến thiên nhanh chóng theo thời gian.
Mô hình dạng tích phù hợp hơn với dữ liệu biến động nhiều theo thời gian.
Từ mô hình dạng tích, để sự thay đổi của dữ liệu ổn định chúng ta có thể chuyển dạng hàm của mô hình bằng cách lấy logarit 2 vế như sau:
3. Phân rã chuỗi thời gian - Hiệu chỉnh mùa vụ
- Khi dữ liệu có yếu tố mùa vụ, trước tiên tách yếu tố mùa vụ ra khỏi dữ liệu
- Sau đó, sử dụng chuỗi dữ liệu được điều chỉnh yếu tố mùa để thực hiện dự báo xu thế.
- Có nhiều phương pháp để tách yếu tố mùa ra khỏi sữ liệu gốc theo nhiều phương pháp. Phương pháp đơn giản nhất là phương pháp Trung bình Trượt Trọng tâm- CMA (Centered Moving average method).
- Mô hình dạng tích, sử dụng tỷ lệ trung bình trượt trọng tâm (Ratio to Moving Average).
- Mô hình dạng tổng, sử dụng chênh lệch so với trung bình trượt trọng tâm (Difference from Moving average).
- Phân rã thành phần xu hướng và chu kỳ
- Phương pháp 1: Hồi quy loại bỏ xu hướng (detrended)
- Phương pháp 2: Phương pháp lọc HP (Hodrick-Prescott Filter)
3.1. Dạng tích
Bước 1: Tính giá trị trung bình trượt trọng tâm (CMA - centered moving average)
Số liệu theo tháng:
Số liệu theo quý:
bao gồm yếu tố xu thế và chu kỳ kết hợp lại:
Bước 2: Tính toán tỷ lệ:
tức là:
Bước 3: Tính các chỉ số mùa vụ:
- Chuỗi dữ liệu theo tháng: chỉ số mùa vụ của tháng bằng trung bình của các ở các tháng trong chuỗi số.
- Chuỗi dữ liệu theo quý: chỉ số mùa vụ của quý bằng trung bình của các ở các quý trong chuỗi số.
Bước 4: Quy chuẩn các chỉ số mùa vụ cho tích của chúng bằng 1, thông qua các nhân tố mùa (The seasonal factors). Các chỉ số mùa vụ quy chuẩn:
Chuỗi dữ liệu theo tháng:
Chuỗi dữ liệu theo quý:
Bước 5: Chuỗi dữ liệu sau khi đã điều chỉnh yếu tố mùa vụ:
3.2. Dạng tổng
Bước 1: Tính giá trị trung bình trượt trọng tâm của như ở phương pháp hiệu chỉnh dạng tích
bao gồm yếu tố xu thế và chu kỳ kết hợp lại:
Bước 2: Tính hiệu số
tức là :
Bước 3: Tính các chỉ số mùa vụ:
- Chuỗi dữ liệu theo tháng: chỉ số mùa vụ của tháng bằng trung bình của các ở các tháng trong chuỗi số.
- Chuỗi dữ liệu theo quý: chỉ số mùa vụ của quý bằng trung bình của các ở các quý trong chuỗi số.
Bước 4: Quy chuẩn các chỉ số mùa vụ cho tổng của chúng bằng 0. Chỉ số mùa vụ quy chuẩn:
Chuỗi dữ liệu theo tháng:
Chuỗi dữ liệu theo quý:
Bước 5: Chuỗi số liệu sau khi điều chỉnh yếu tố mùa vụ:
3.3. Thực hành Stata - Kiểm định tính mùa vụ
Kiểm định sự bằng nhau giữa các trung vị của các nhóm (thể hiện tính mùa) bằng kiểm định Kruskal-Wallis:
Ho: Không có yếu tố mùa vụ
H1: Có yếu tố mùa vụ
Tạo các biến trung bình trượt
Dữ liệu theo quý:
1genr CMAq = (0.5*Y[_n-2] + Y*[_n-1] + Y + Y*[_n+1] + 0.5*Y[_n+2])/4Dữ liệu theo tháng:
1gen CMAm=(0.5*Y[_n-6]+ Y*[_n-5] +Y*[_n-3] +Y*[_n-5] +Y*[_n-2] +Y*[_n-1] + Y + Y*[_n+1]+ Y*[_n+2]+ Y*[_n+3]+ Y*[_n+4]+ Y*[_n+5] + 0.5*Y[_n+6])/12 Tạo các biến kiểm tra bằng nhau giữa các mùa
- Dạng tổng:
gen d = Y - CMA - Dạng tích:
gen t = Y/CMA
Tạo biến phân nhóm từ biến time ban đầu các biến kiểm tra:
1bysort time: gen qua = _n
2bysort time: gen mon = _nKiểm định Kruskal-Wallis
1kwallis d/t, by(qua/mon)Kết luận về tính mùa vụ với mức ý nghĩa 1%, 5% và 10%
Nếu tồn tại tính mùa vụ, hiệu chỉnh tính mùa vụ
Theo dõi Science for Economics để cập nhật thêm những bài viết tiếp theo nhé!