Trong các phân tích dữ liệu không gian, việc theo dõi sự thay đổi qua thời gian và địa điểm là một kỹ năng quan trọng. Sau khi đã nắm vững cách tải dữ liệu từ kho lưu trữ GitHub, vẽ đồ thị chuỗi thời gian và tạo bản đồ choropleth tĩnh, bước tiếp theo là đưa dữ liệu vào không gian chuyển động. Bài viết này sẽ hướng dẫn bạn cách tạo một bản đồ choropleth động để khám phá sự phân bố của dịch bệnh qua từng ngày.
Cách tạo bản đồ cho từng ngày
Để bắt đầu, chúng ta cần làm sạch và mô tả dữ liệu thô. Dữ liệu này chứa số lượng ca nhiễm tích lũy cho từng quận tại Mỹ bắt đầu từ cuối tháng 1 năm 2020. Các biến số lưu trữ dữ liệu theo ngày được đặt tên theo định dạng từ v12 đến v86.
Quá trình chuẩn bị dữ liệu đòi hỏi chúng ta phải hợp nhất dữ liệu địa lý, dữ liệu ca bệnh và dữ liệu dân số. Chúng ta sử dụng dấu hoa thị như một wildcard trong lệnh gọi biến để giữ lại toàn bộ các cột ngày tháng.
1clear
2copy https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_county_500k.zip cb_2018_us_county_500k.zip
3unzipfile cb_2018_us_county_500k.zip
4spshape2dta cb_2018_us_county_500k.shp, saving(usacounties) replace
5use usacounties.dta, clear
6generate fips = real(GEOID)
7save usacounties.dta, replace
8clear
9import delimited https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_US.csv
10drop if missing(fips)
11save covid19_county, replace
12clear
13import delimited https://www2.census.gov/programs-surveys/popest/datasets/2010-2019/counties/totals/co-est2019-alldata.csv
14generate fips = state*1000 + county
15save census_popn, replace
16clear
17use _ID _CX _CY GEOID fips using usacounties.dta
18merge 1:1 fips using covid19_county, keepusing(province_state combined_key v*)
19keep if _merge == 3
20drop _merge
21merge 1:1 fips using census_popn, keepusing(census2010pop popestimate2019)
22keep if _merge==3
23drop _merge
24drop if inlist(province_state, "Alaska", "Hawaii")
25format %16.0fc popestimate2019 v*
26save covid19_adj, replaceThiết lập vòng lặp và xử lý chuỗi thời gian
Dữ liệu hiện tại bao gồm thông tin địa lý, dân số và số lượng ca nhiễm theo từng ngày. Để tạo một video, chúng ta cần tạo ra các bản đồ riêng biệt cho từng biến số thời gian. Việc này được thực hiện thông qua vòng lặp forvalues.
Trong vòng lặp, chúng ta tính toán số ca nhiễm đã điều chỉnh theo dân số cho mỗi quận. Định dạng ngày tháng trong hệ thống được tính bằng số ngày trôi qua kể từ đầu năm 1960. Do đó, chúng ta dùng các phép tính cơ bản để tịnh tiến mốc thời gian, sau đó dùng hàm string để định dạng lại ngày tháng nhằm hiển thị lên tiêu đề bản đồ.
Đồng thời, mỗi bản đồ cần được xuất ra dưới dạng tệp ảnh với tên gọi được đánh số thứ tự nối tiếp nhau, bắt đầu từ số 1 và có các số 0 ở đầu. Khai báo chuỗi theo định dạng này giúp hệ thống nhận diện đúng trình tự khung hình khi ghép video.
Xuất bản đồ hàng loạt
Mỗi vòng lặp sẽ thực hiện ba nhiệm vụ cốt lõi: tính toán tỷ lệ ca bệnh điều chỉnh theo quy mô dân số của ngày hôm đó, vẽ bản đồ với tiêu đề chứa ngày tháng tương ứng và xuất biểu đồ ra một tệp ảnh có độ phân giải cao.
1spset, modify shpfile(usacounties_shp)
2generate confirmed_adj = .
3forvalues time = 12/86 {
4 local date = 21936 - 12 + `time'
5 local date = string(`date', "%tdMonth_dd,_CCYY")
6 replace confirmed_adj = 100000*(v`time'/popestimate2019)
7 grmap confirmed_adj, clnumber(8) clmethod(custom) clbreaks(0 5 10 15 20 25 50 100 5000) ocolor(gs8) osize(vthin) title("Confirmed Cases of COVID-19 in the United States on `date'") subtitle("cumulative cases per 100,000 population")
8 local filenum = string(`time'-11,"%03.0f")
9 graph export "map_`filenum'.png", as(png) width(3840) height(2160)
10}
11drop confirmed_adjĐoạn mã trên sẽ tạo ra hàng chục bản đồ khác nhau. Các điểm phân chia màu sắc được thiết lập thủ công thay vì sử dụng phương pháp phân vị mặc định, giúp chú giải bản đồ luôn cố định và nhất quán qua tất cả các ngày.
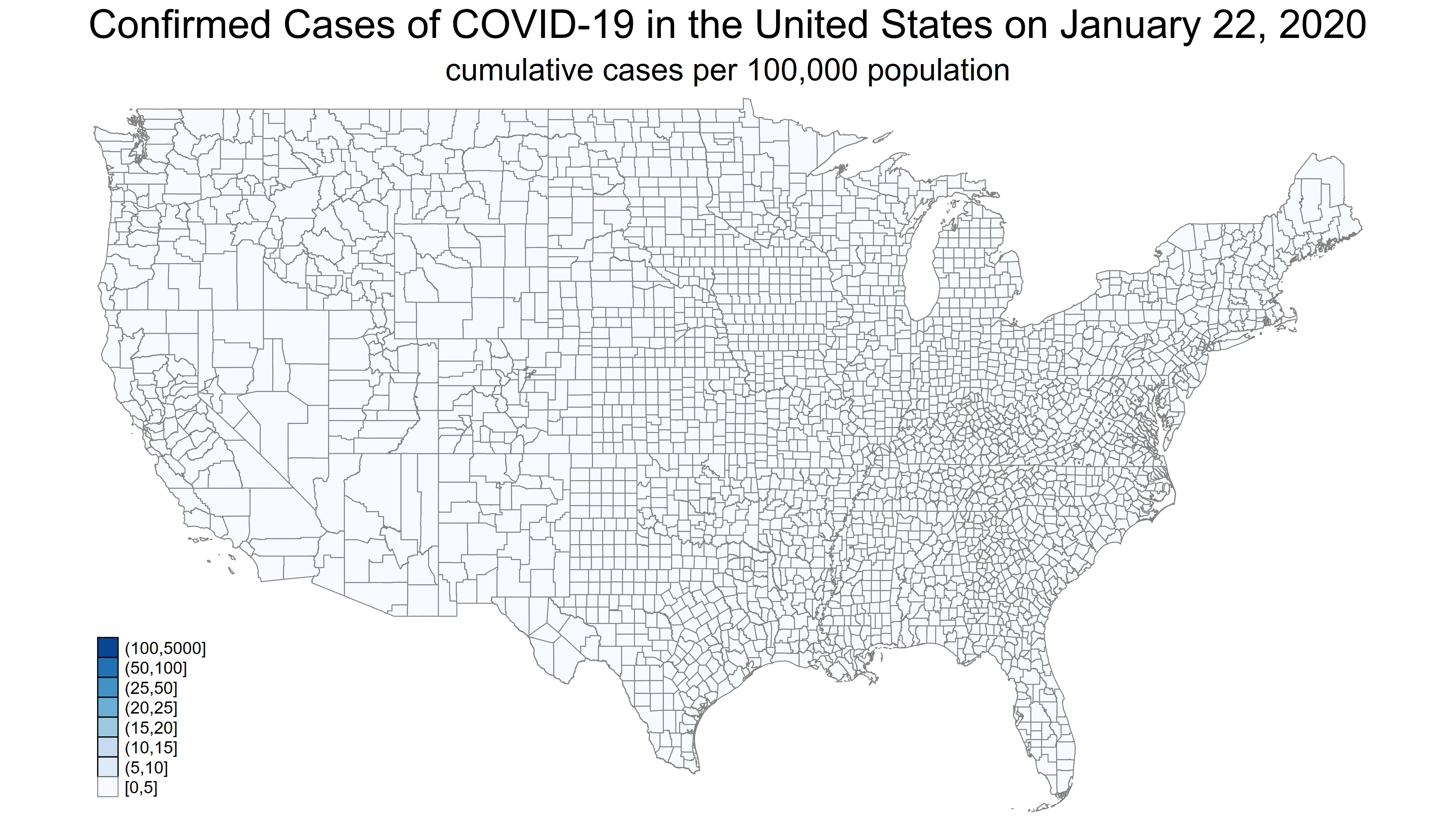
Đây là hình ảnh bản đồ khởi điểm được tạo ra ở đầu chuỗi thời gian.
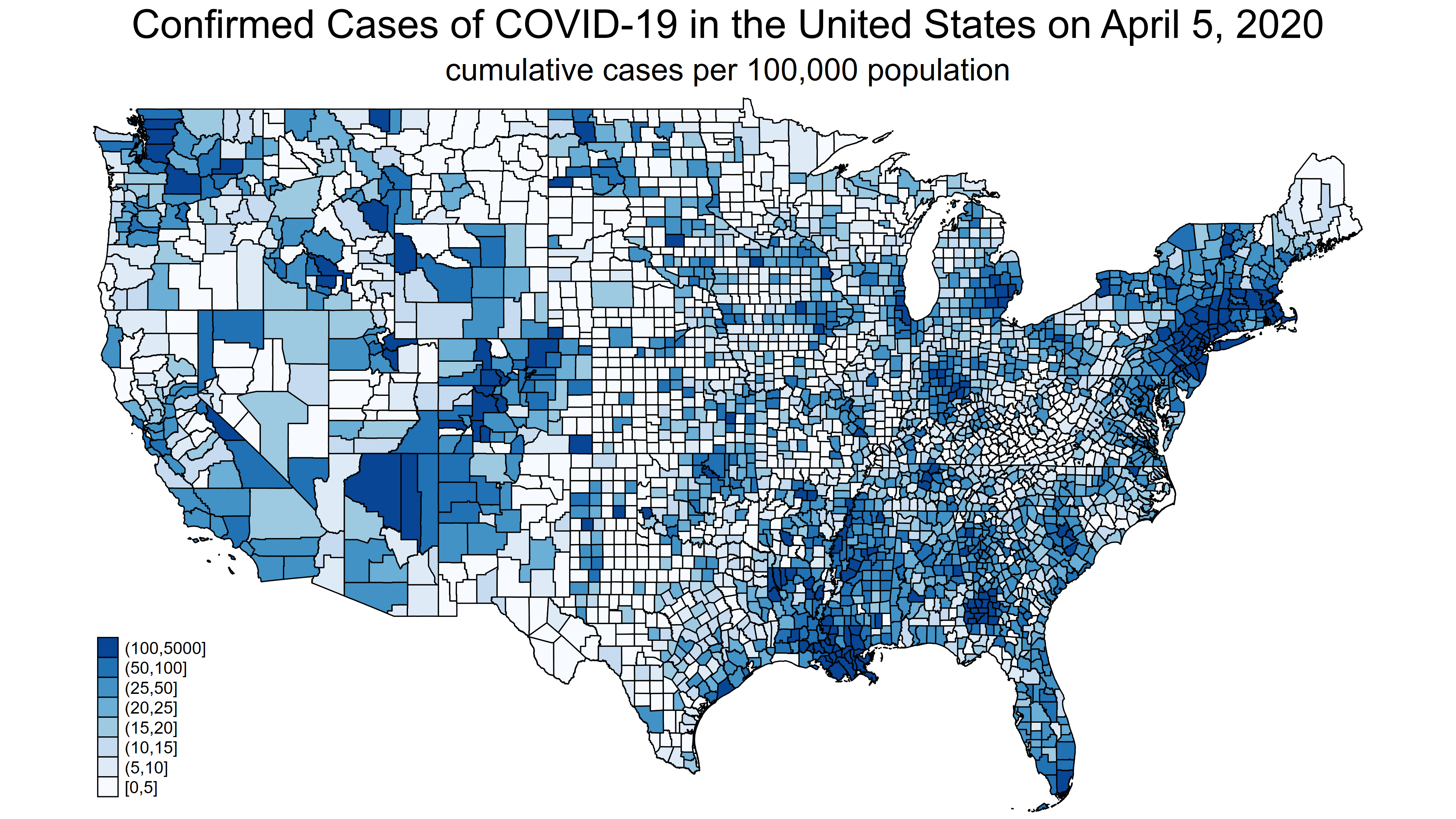
Và đây là hình ảnh bản đồ ở những ngày cuối của tập dữ liệu, cho thấy sự lan rộng rõ rệt của dịch bệnh.
Kết hợp hình ảnh thành video bằng FFmpeg
Sau khi đã có bộ sưu tập hình ảnh lưu trong thư mục, công đoạn cuối cùng là ghép chúng lại. FFmpeg là một phần mềm mã nguồn mở mạnh mẽ chuyên xử lý dữ liệu đa phương tiện. Từ bên trong hệ thống, bạn có thể gọi trực tiếp phần mềm này bằng lệnh shell.
Cú pháp dưới đây sẽ nhận các tệp ảnh được đánh số thứ tự, thiết lập tốc độ khung hình ở mức hai ảnh mỗi giây và nén chúng thành một tệp video hoàn chỉnh.
1shell "C:\Program Files\ffmpeg\bin\ffmpeg.exe" -framerate 1/.5 -i map_%03d.png -c:v libx264 -r 30 -pix_fmt yuv420p covid19.mp4Chỉ mất vài phút để hệ thống xử lý và kết xuất toàn bộ dữ liệu. Kết quả nhận được là một công cụ trực quan hóa không gian và thời gian cực kỳ mạnh mẽ.
✨ Giá trị đắt giá: Việc trực quan hóa dữ liệu không gian theo thời gian thực không chỉ tạo ra các báo cáo sinh động mà còn giúp các nhà nghiên cứu phát hiện ra các cụm lây nhiễm và hướng di chuyển của dữ liệu. Khả năng kết hợp mã lệnh phân tích truyền thống với các công cụ đa phương tiện như FFmpeg mở ra một hướng đi mới cho việc truyền đạt kết quả khoa học dữ liệu một cách trực quan và đại chúng hơn.
Bạn sẽ làm thế nào để thay đổi đoạn mã trên nếu tập dữ liệu được cập nhật thêm một tháng nữa? Hãy thử xác định các tham số cần điều chỉnh trong vòng lặp và tự tay kết xuất một đoạn video với tốc độ khung hình nhanh gấp đôi.