
Trong bài viết này, bạn sẽ tìm hiểu kiểm định t là gì và cách thực hiện phương pháp này trong ngôn ngữ lập trình r. Đầu tiên, chúng ta sẽ làm quen với một hàm đơn giản giúp thực hiện kiểm định chỉ với một dòng mã nguồn. Sau đó, chúng ta sẽ cùng khám phá bản chất của kiểm định thông qua việc xây dựng từng bước với dữ liệu thực tế về hành khách tàu Titanic.
Kiểm định t là gì
Kiểm định t là một quy trình thống kê được sử dụng để kiểm tra xem sự khác biệt giữa hai nhóm có ý nghĩa hay chỉ là do ngẫu nhiên. Trong bài viết này, chúng ta sẽ xem xét dữ liệu từ các hành khách trên tàu Titanic, chia họ thành hai nhóm nam và nữ. Giả sử chúng ta muốn kiểm tra giả thuyết rằng nam giới và nữ giới có độ tuổi trung bình như nhau. Nếu dữ liệu cho thấy phụ nữ trẻ hơn nam giới trung bình 2 tuổi, chúng ta cần đặt câu hỏi: liệu đây là một sự khác biệt thực sự hay chỉ là sự trùng hợp ngẫu nhiên? Kiểm định t sẽ giúp chúng ta trả lời câu hỏi đó.
Tại sao kiểm định t lại quan trọng
Kiểm định t rất quan trọng khi chúng ta muốn đưa ra kết luận về một quần thể dựa trên một mẫu dữ liệu nhỏ. Ví dụ, hãy tưởng tượng chúng ta đang nghiên cứu nhân khẩu học của hành khách đi tàu vào đầu thế kỷ 20 và muốn sử dụng mẫu hành khách tàu Titanic để tổng quát hóa kết quả cho toàn bộ hành khách thời kỳ đó.
Tất nhiên, những suy luận như vậy có thể bị sai lệch vì hành khách tàu Titanic có thể không đại diện hoàn hảo cho tất cả hành khách đi tàu thời bấy giờ. Tuy nhiên, mẫu dữ liệu này vẫn có thể cung cấp những thông tin giá trị nếu bối cảnh của cả mẫu và quần thể được xem xét kỹ lưỡng và giải thích rõ ràng.
Khám phá dữ liệu hành khách tàu Titanic
Chúng ta sẽ sử dụng thư viện titanic trong r để truy cập dữ liệu. Cụ thể, chúng ta sẽ làm việc với một tập hợp con nằm trong data frame có tên titanic_train. Dưới đây là đoạn mã để tải dữ liệu, tính toán số trung bình, độ lệch chuẩn của độ tuổi và thống kê số lượng hành khách theo giới tính.
1library(titanic)
2library(dplyr)
3data('titanic_train')
4df <- titanic_train %>%
5 select(Sex, Age) %>%
6 na.omit()
7df %>% group_by(Sex) %>%
8 summarize(mean(Age), sd(Age), n())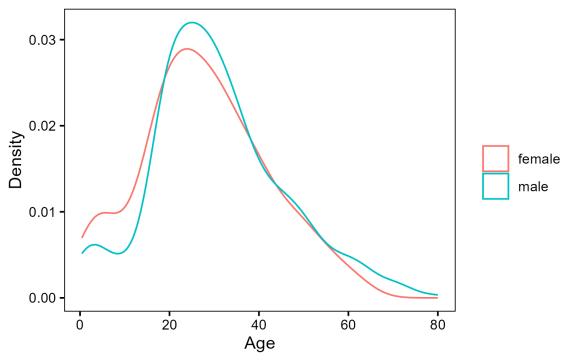
Kết quả cho thấy có sự chênh lệch khoảng 2.8 tuổi giữa độ tuổi trung bình của nam và nữ trên tàu Titanic. Để trực quan hơn, chúng ta có thể kiểm tra biểu đồ phân phối độ tuổi ngay dưới đây.
1library(ggplot2)
2ggplot()+
3 geom_density(aes(x=df$Age, color = df$Sex), size = 0.7)+
4 scale_color_discrete("")+
5 xlab("Age")+
6 ylab("Density")Có vẻ như các phân phối này rất giống nhau. Trong trường hợp này, lựa chọn tốt nhất là thực hiện một kiểm định t để xác định xem chúng thực sự giống nhau hay có sự khác biệt đáng kể.
Cách thực hiện kiểm định t trong r
Việc thực hiện kiểm định t trong r rất dễ dàng nhờ hàm t.test. Tham số đầu tiên của hàm là một công thức mô tả mối quan hệ giữa các biến. Trong trường hợp này, chúng ta muốn biết độ tuổi thay đổi như thế nào giữa các giới tính khác nhau. Công thức bao gồm biến phụ thuộc Age ở bên trái, theo sau là dấu ngã và biến độc lập Sex ở bên phải. Tham số thứ hai là data frame chứa dữ liệu. Kiểm định này giả định rằng hai mẫu là độc lập và độ tuổi tuân theo phân phối chuẩn, điều mà chúng ta đã xác nhận qua biểu đồ mật độ ở trên.
1t.test(Age ~ Sex, data = df)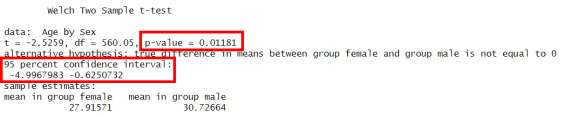
Làm thế nào để diễn giải kết quả này?
Giá trị p-value bằng 0.0118 có nghĩa là nếu thực sự không có sự khác biệt về độ tuổi trung bình giữa hành khách nam và nữ, thì chỉ có 1.18 phần trăm cơ hội quan sát thấy sự chênh lệch lớn như mức chúng ta đã tìm thấy. Vì p-value này nhỏ hơn 0.05, chúng ta bác bỏ giả thuyết không ở mức tin cậy 95 phần trăm, cho thấy có một sự khác biệt thực sự tồn tại. Tuy nhiên, nếu chọn mức tin cậy 99 phần trăm, chúng ta sẽ không bác bỏ giả thuyết không vì p-value lớn hơn 0.01.
Khoảng tin cậy cho biết nếu chúng ta lấy nhiều mẫu tương tự, trong 95 phần trăm số lần, sự chênh lệch giữa các giá trị trung bình sẽ nằm trong khoảng từ âm 0.62 đến âm 5. Khoảng tin cậy này không chứa giá trị 0, do đó chúng ta có đủ bằng chứng để kết luận rằng có sự khác biệt giữa độ tuổi trung bình của nam và nữ.
Kiểm định t kết hợp phương pháp bootstrap
Kiểm định t với bootstrap là một cách tốt để hiểu các khái niệm cần thiết khi diễn giải kết quả. Mọi thứ dựa trên định lý giới hạn trung tâm, theo đó nếu lấy nhiều mẫu từ một quần thể và tính trung bình của mỗi mẫu, thì phân phối của các giá trị trung bình đó sẽ tuân theo phân phối chuẩn, giá trị trung bình của các trung bình mẫu sẽ xấp xỉ giá trị trung bình của quần thể và độ lệch chuẩn của phân phối này được gọi là sai số chuẩn.
Bootstrap là kỹ thuật tạo ra nhiều mẫu ảo từ mẫu duy nhất mà chúng ta có bằng cách lấy mẫu lặp lại. Chúng ta sẽ tạo một hàm để lấy mẫu lại từ data frame ban đầu và tính toán sự chênh lệch giữa trung bình tuổi của nam và nữ.
1diff_means <- function(data) {
2 sample_df <- data %>% slice_sample(n = nrow(data), replace = TRUE)
3 means <- sample_df %>%
4 group_by(Sex) %>%
5 summarize(mean_age = mean(Age, na.rm = TRUE))
6 male_mean <- means %>% filter(Sex == "male") %>% pull(mean_age)
7 female_mean <- means %>% filter(Sex == "female") %>% pull(mean_age)
8 return(male_mean - female_mean)
9}Tiếp theo, chúng ta sử dụng hàm replicate để thực thi quy trình này 1000 lần. Trước đó, để tính p-value, chúng ta cần điều chỉnh sao cho giả thuyết không là đúng bằng cách trừ đi độ chênh lệch quan sát được là 2.81 khỏi độ tuổi của tất cả nam giới, làm cho sự khác biệt trung bình trở về 0.
1df_null <- df %>%
2 mutate(Age = ifelse(Sex=="male", Age-2.81, Age))
3set.seed(1308)
4diffs <- replicate(1000, diff_means(df_null))
5ggplot()+
6 geom_histogram(aes(x = diffs), color = "white", fill = "#2E3031")+
7 geom_vline(xintercept = -2.8, color = "#A33F3F")+
8 geom_vline(xintercept = 2.8, color = "#A33F3F")+
9 xlab("Age Differences (Null Hypothesis)")+
10 ylab("Number of Individuals")+
11 theme_bw()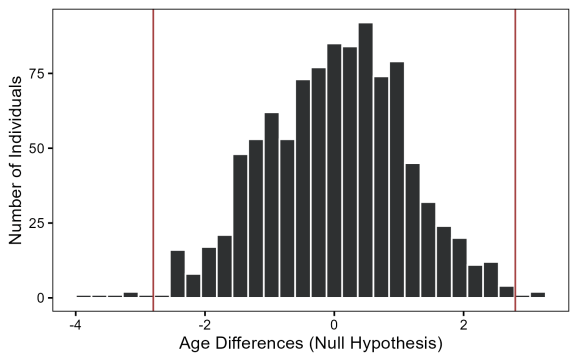
Biểu đồ histogram cho thấy các chênh lệch mẫu sẽ trông như thế nào nếu giả thuyết không là đúng. Các đường màu đỏ hiển thị sự khác biệt thực tế mà chúng ta quan sát được. Để tính p-value thủ công, chúng ta đếm số lượng mẫu có độ chênh lệch cực đoan hơn mức 2.8.
1sum(diffs>=2.81)/1000
2sum(diffs<=-2.81)/1000Kết quả thu được khoảng 0.9 phần trăm, rất gần với p-value từ hàm t.test. Điều này một lần nữa cho phép bác bỏ giả thuyết không. Ngoài việc giúp hiểu rõ bản chất kiểm định, phương pháp bootstrap còn có ưu điểm là không yêu cầu phân phối độ tuổi phải tuân theo phân phối chuẩn.
✨ Giá trị đắt giá: Ưu điểm lớn nhất của phương pháp bootstrap là tính linh hoạt, giúp bạn thực hiện kiểm định thống kê ngay cả khi dữ liệu không thỏa mãn các giả định khắt khe về phân phối chuẩn của các kiểm định truyền thống.
Câu hỏi tư duy: Nếu kích thước mẫu của chúng ta giảm đi mười lần nhưng sự chênh lệch trung bình vẫn giữ nguyên là 2.8 tuổi, bạn dự đoán giá trị p-value sẽ thay đổi như thế nào và tại sao?

