Stata cung cấp một phương thức đơn giản và tinh tế để thực hiện các mô hình hồi quy Bayes bằng cách thêm tiền tố bayes vào trước các lệnh ước lượng. Với hơn 45 lệnh được hỗ trợ, người dùng có thể linh hoạt lựa chọn giữa các phân phối tiền nghiệm mặc định hoặc tự thiết lập theo nhu cầu nghiên cứu. Trong bài viết này, chúng ta sẽ tìm hiểu cách áp dụng hồi quy logistic Bayes và khám phá sức mạnh của phân phối tiền nghiệm Cauchy đối với các hệ số hồi quy.
Một thách thức phổ biến khi làm việc với Bayes là việc lựa chọn phân phối tiền nghiệm. Cách tiếp cận thận trọng thường dùng các tiền nghiệm yếu hoặc không có thông tin để đảm bảo tính khách quan dựa trên dữ liệu. Tuy nhiên, các tiền nghiệm không có thông tin đôi khi không đủ để giải quyết những vấn đề như hiện tượng phân tách hoàn hảo trong hồi quy logistic. Ngược lại, nếu không có kiến thức chuyên gia sâu sắc, việc chọn tiền nghiệm có thông tin cũng không hề dễ dàng. Dựa trên khuyến nghị của Gelman và các cộng sự, việc sử dụng phân phối tiền nghiệm Cauchy thông tin yếu là một giải pháp cân bằng hiệu quả.
Chuẩn bị dữ liệu và chuẩn hóa
Chúng ta sử dụng bộ dữ liệu Iris nổi tiếng để phân loại hoa. Biến phụ thuộc virg phân biệt loài Iris virginica với các loài khác. Các biến độc lập bao gồm chiều dài và chiều rộng của đài hoa và cánh hoa. Theo khuyến nghị của các nhà nghiên cứu, các biến độc lập nên được chuẩn hóa để có trung bình bằng 0 và độ lệch chuẩn bằng 0.5 trước khi áp dụng phân phối tiền nghiệm Cauchy.
1use irisstd
2summarizeĐể đánh giá mô hình, chúng ta sẽ loại bỏ quan sát đầu tiên và cuối cùng khỏi quá trình ước lượng để dùng cho mục đích dự báo sau này.
1generate touse = _n>1 & _n<_NHồi quy logistic truyền thống và vấn đề dữ liệu
Trước tiên, chúng ta chạy mô hình hồi quy logistic tiêu chuẩn để làm cơ sở đối chiếu.
1logit virg slen swid plen pwid if touse, nologLệnh logit đưa ra cảnh báo rằng một số quan sát được xác định hoàn toàn. Điều này xảy ra do các biến độc lập liên tục có nhiều giá trị lặp lại, dẫn đến hiện tượng hội tụ không ổn định trong ước lượng hợp lý cực đại.
Ước lượng bayes với tiền nghiệm mặc định
Bây giờ, chúng ta thêm tiền tố bayes vào trước lệnh logit. Theo mặc định, Stata sử dụng phân phối tiền nghiệm chuẩn với trung bình bằng 0 và độ lệch chuẩn bằng 100 cho các hệ số hồi quy và hằng số chặn.
1set seed 15
2bayes: logit virg slen swid plen pwid if touseKết quả từ lệnh bayes cho thấy các ước lượng có giá trị tuyệt đối lớn hơn nhiều so với ước lượng hợp lý cực đại thông thường. Ví dụ, trung bình hậu nghiệm của biến plen đạt khoảng 60, nghĩa là một đơn vị thay đổi của plen tạo ra sự thay đổi cực lớn trên thang đo logistic. Để hiểu tại sao có sự khác biệt này, chúng ta có thể xem xét biểu đồ phân phối hậu nghiệm.
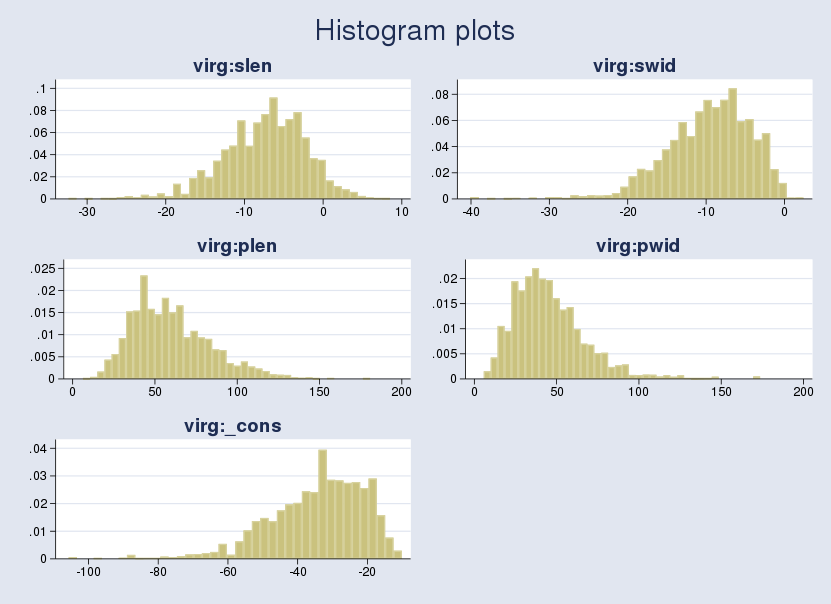
1bayesgraph histogram _all, combine(rows(3))Khi sử dụng tiền nghiệm yếu, các yếu tố hậu nghiệm thường lệch và có giá trị trung bình lớn hơn nhiều so với giá trị yếu tố cực đại. Điều này thúc đẩy chúng ta cần một giải pháp tiền nghiệm tốt hơn.
Sử dụng phân phối tiền nghiệm cauchy
Gelman đề xuất sử dụng phân phối tiền nghiệm Cauchy với quy mô là 2.5 cho các hệ số hồi quy và quy mô là 10 cho hằng số chặn khi dữ liệu đã được chuẩn hóa. Lựa chọn này dựa trên quan sát rằng trên thang đo logistic, một sự thay đổi 5 đơn vị sẽ đẩy xác suất từ mức rất thấp lên rất cao.
1set seed 15
2bayes, prior({virg:_cons}, cauchy(0, 10)) ///
3 prior({virg:slen swid plen pwid}, cauchy(0, 2.5)): ///
4 logit virg slen swid plen pwid if touseCác ước lượng trung bình hậu nghiệm trong mô hình này đã nhỏ hơn khoảng ba lần so với mô hình dùng tiền nghiệm mặc định và gần với kết quả của phương pháp hợp lý cực đại hơn. Log-marginal likelihood của mô hình này là âm 18.7, cao hơn mức âm 20.6 của mô hình trước, cho thấy phân phối tiền nghiệm Cauchy giúp mô hình khớp với dữ liệu tốt hơn.
Dự báo xác suất hậu nghiệm
Sau khi có được mô hình ưng ý, chúng ta có thể thực hiện dự báo cho các quan sát nằm ngoài mẫu ước lượng. Chúng ta kiểm tra quan sát đầu tiên (không thuộc loài virginica) và quan sát cuối cùng (thuộc loài virginica).
1list if !touseSử dụng lệnh bayesstats summary kết hợp với hàm invlogit để tính toán xác suất hậu nghiệm cho các quan sát này.
1bayesstats summary (prob0:invlogit(-.448837*{virg:slen} ///
2 +.5143057*{virg:swid}-.668397*{virg:plen} ///
3 -.6542964*{virg:pwid}+{virg:_cons})), nolegend
4bayesstats summary (prob1:invlogit(.0342163*{virg:slen} ///
5 -.0622702*{virg:swid}+.3801059*{virg:plen} ///
6 +.3939755*{virg:pwid}+{virg:_cons})), nolegendKết quả dự báo cho thấy xác suất hậu nghiệm của quan sát đầu tiên xấp xỉ bằng 0, trong khi quan sát cuối cùng đạt khoảng 0.91. Cả hai kết quả đều khớp hoàn toàn với thực tế quan sát được trong dữ liệu.
✨ Phân phối tiền nghiệm Cauchy hoạt động như một bộ điều chuẩn thông minh, giúp kiểm soát các hệ số hồi quy không bị phóng đại quá mức trong các bài toán phân loại có dữ liệu phân tách, đồng thời mang lại hiệu suất dự báo vượt trội so với các tiền nghiệm mặc định.
Bạn hãy thử thay đổi quy mô của phân phối Cauchy từ 2.5 sang các giá trị khác như 1.5 hoặc 5.0 và quan sát sự thay đổi của log-marginal likelihood. Theo bạn, độ nhạy của mô hình đối với tham số quy mô này phản ánh điều gì về lượng thông tin có trong dữ liệu?

