Trí tuệ nhân tạo đang trở thành một chủ đề thu hút sự chú ý lớn và ChatGPT hiện là công cụ phổ biến nhất trong lĩnh vực này. Việc kết hợp khả năng phân tích thống kê chuyên sâu của Stata với sự linh hoạt của trí tuệ nhân tạo có thể giúp quy trình làm việc của nhà nghiên cứu trở nên hiệu quả hơn. Bài viết này sẽ hướng dẫn bạn cách xây dựng một lệnh tùy chỉnh trong Stata để gọi trực tiếp ChatGPT thông qua việc tích hợp môi trường Python.
Tích hợp Stata và Python
Để bắt đầu, chúng ta cần tận dụng khả năng chạy mã Python ngay bên trong Stata. Nếu bạn chưa quen với việc sử dụng kết hợp hai ngôn ngữ này, hãy đảm bảo rằng Stata đã được thiết lập để nhận diện phiên bản Python trên máy tính của bạn. Việc tích hợp này cho phép chúng ta sử dụng các thư viện mạnh mẽ của Python để xử lý các tác vụ mà Stata thuần túy chưa hỗ trợ, ví dụ như giao tiếp với giao diện lập trình ứng dụng.
Sử dụng Python để tương tác với ChatGPT
Chúng ta sẽ sử dụng API của OpenAI để giao tiếp với ChatGPT. Để thực hiện, bạn cần có một tài khoản OpenAI và mã API key cá nhân. Ngoài ra, bạn phải cài đặt thư viện openai cho Python. Bạn có thể cài đặt thư viện này bằng cách nhập lệnh shell pip install openai vào cửa sổ lệnh của Stata.
Viết hàm Python đầu tiên
Bước đầu tiên là viết một đoạn mã Python để nhập thư viện, định nghĩa một hàm và gửi mã API key đến máy chủ OpenAI. Trong đoạn mã dưới đây, chúng ta sẽ định nghĩa một hàm có tên chatgpt và thiết lập chuỗi nhập liệu ban đầu là một yêu cầu viết thơ haiku về Stata.
1python:
2import openai
3def chatgpt():
4 openai.api_key = "DÁN MÃ API CỦA BẠN VÀO ĐÂY"
5 inputtext = "Write a haiku about Stata"
6 outputtext = openai.ChatCompletion.create(
7 model="gpt-3.5-turbo",
8 messages=[{"role": "user", "content": inputtext}]
9 )
10 print(outputtext.choices[0].message.content)python: chatgpt()
end
Sau khi chạy hàm này, bạn sẽ nhận được câu trả lời từ ChatGPT ngay trong cửa sổ kết quả của Stata.
Tạo lệnh Stata tùy chỉnh
Việc gọi trực tiếp hàm Python như trên khá bất tiện nếu bạn muốn sử dụng thường xuyên. Giải pháp tốt hơn là tạo ra một chương trình Stata riêng biệt. Chúng ta sẽ lưu đoạn mã vào một tệp tin có đuôi .ado để có thể gọi lệnh bất cứ lúc nào.
Để lệnh này trở nên linh hoạt, chúng ta cần cho phép người dùng nhập câu hỏi trực tiếp từ dòng lệnh Stata thay vì cố định trong mã nguồn. Chúng ta sẽ sử dụng đối số InputText để lưu trữ nội dung câu hỏi và giao diện chức năng Stata để truyền dữ liệu này sang môi trường Python.
Truyền tham số và nhận kết quả
Sử dụng thư viện sfi của Stata, chúng ta có thể dễ dàng lấy giá trị từ các biến cục bộ macro và chuyển chúng thành biến trong Python. Đồng thời, kết quả trả về từ ChatGPT cũng sẽ được lưu ngược lại vào một biến cục bộ trong Stata để người dùng có thể sử dụng cho các bước tiếp theo.
1program chatgpt, rclass
2 version 18
3 args InputText
4 python: chatgpt_run()
5 return local OutputText = `"`OutputText'"'python:
import openai
from sfi import Macro
def chatgpt_run():
openai.api_key = "DÁN MÃ API CỦA BẠN VÀO ĐÂY"
inputtext = Macro.getLocal('InputText')
outputtext = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": inputtext}]
)
result = outputtext.choices[0].message.content
print(result)
Macro.setLocal("OutputText", result)
end
end
Bây giờ, bạn có thể thực hiện lệnh mới này với bất kỳ câu hỏi nào bằng cú pháp đơn giản: chatgpt "Viết một bài thơ về hồi quy tuyến tính".
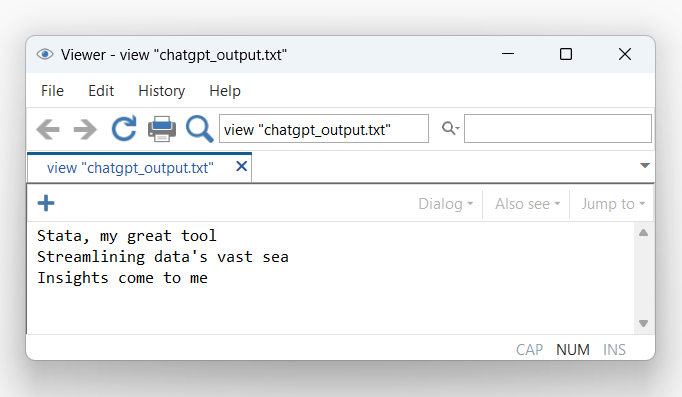
Lưu phản hồi vào tệp văn bản
Một vấn đề thường gặp là khi kết quả trả về quá dài, các ký tự xuống dòng có thể bị mất định dạng khi hiển thị trong cửa sổ kết quả. Để giải quyết điều này, chúng ta có thể bổ sung thêm vài dòng mã Python để ghi toàn bộ nội dung phản hồi vào một tệp tin txt.
1python:
2 f = open("chatgpt_output.txt", "w")
3 f.write(result)
4 f.close()Cách tiếp cận này đảm bảo bạn luôn có một bản sao hoàn chỉnh và đúng định dạng của câu trả lời để phục vụ cho việc báo cáo hoặc lưu trữ.
✨ Khả năng kết nối Stata với các mô hình ngôn ngữ lớn không chỉ dừng lại ở việc đặt câu hỏi vui vẻ, mà còn mở ra tiềm năng tự động hóa việc giải thích các bảng kết quả thống kê phức tạp hoặc viết mã lệnh mô phỏng dữ liệu một cách nhanh chóng.
Hãy thử ứng dụng lệnh vừa tạo để yêu cầu ChatGPT giải thích ý nghĩa của hệ số hồi quy trong một mô hình mà bạn đang thực hiện. Theo bạn, làm thế nào để tối ưu hóa câu lệnh trên để ChatGPT có thể đọc trực tiếp các thông số từ bảng kết quả return list của Stata?

