Các phương pháp học máy, điển hình là các cây quyết định kết hợp, đang được sử dụng rộng rãi để dự báo kết quả dựa trên dữ liệu. Tuy nhiên, các phương pháp này thường tập trung vào việc đưa ra các dự báo điểm, điều này làm hạn chế khả năng định lượng độ không chắc chắn của dự báo. Trong nhiều lĩnh vực như y tế và tài chính, mục tiêu không chỉ là dự báo chính xác mà còn là đánh giá độ tin cậy của các dự báo đó. Khoảng dự báo, cung cấp các ngưỡng trên và ngưỡng dưới sao cho giá trị thực tế nằm trong đó với xác suất cao, là một công cụ đáng tin cậy để định lượng độ chính xác của dự báo. Một khoảng dự báo lý tưởng cần đáp ứng các tiêu chí: cung cấp độ bao phủ hợp lệ mà không phụ thuộc vào các giả định phân phối mạnh, có tính cung cấp thông tin bằng cách càng hẹp càng tốt cho mỗi quan sát, và có tính thích ứng, tức là cung cấp khoảng rộng hơn cho các quan sát khó dự báo và hẹp hơn cho các quan sát dễ dự báo.
Bài viết này sẽ hướng dẫn cách sử dụng bộ lệnh h2oml trong Stata để xây dựng các khoảng dự báo bằng cách tiếp cận hồi quy phân vị phù hợp.
Khái niệm về dự báo phù hợp
Dự báo phù hợp là một phương pháp tổng quát được thiết kế để bổ trợ cho bất kỳ dự báo học máy nào bằng cách cung cấp các khoảng dự báo có đảm bảo về độ bao phủ thống kê mà không cần giả định phân phối. Về mặt lý thuyết, dự báo phù hợp bắt đầu với một mô hình học máy đã được huấn luyện trước trên dữ liệu độc lập và được phân phối định danh. Sau đó, nó sử dụng dữ liệu kiểm chứng được giữ lại từ cùng một phân phối tạo dữ liệu, gọi là dữ liệu hiệu chuẩn, để xác định một hàm số điểm S. Hàm số này gán điểm số lớn hơn khi sự khác biệt giữa giá trị dự báo và giá trị phản hồi thực tế lớn hơn. Những điểm số này sau đó được sử dụng để xây dựng khoảng dự báo cho các quan sát mới.
Phương pháp này đảm bảo rằng xác suất giá trị thực tế nằm trong khoảng dự báo lớn hơn hoặc bằng một trừ cho mức sai số alpha do người dùng xác định. Đặc tính này được gọi là độ bao phủ biên, vì xác suất được tính trung bình trên tính ngẫu nhiên của dữ liệu hiệu chuẩn và dữ liệu kiểm tra.
Hồi quy phân vị phù hợp
Mặc dù phương pháp dự báo phù hợp đảm bảo độ bao phủ hợp lệ với các giả định phân phối tối thiểu cho bất kỳ phương pháp học máy nào, chúng ta sẽ tập trung vào hồi quy phân vị phù hợp, gọi tắt là CQR. Đây là một trong những phương pháp được sử dụng rộng rãi và khuyến nghị nhất để xây dựng khoảng dự báo.
Quy trình CQR có thể được tóm tắt qua bốn bước. Bước một là chia dữ liệu thành ba phần gồm tập huấn luyện, tập hiệu chuẩn và tập kiểm tra. Bước hai sử dụng tập huấn luyện để huấn luyện bất kỳ phương pháp hồi quy phân vị nào nhằm ước lượng hai hàm phân vị điều kiện cho mức alpha chia hai và một trừ alpha chia hai. Ví dụ, khi mức sai số alpha là 0.1, chúng ta sẽ thu được phân vị 0.05 và 0.95.
Bước ba sử dụng dữ liệu hiệu chuẩn để tính toán các điểm số phù hợp cho mỗi quan sát, nhằm định lượng sai số tạo ra bởi khoảng cách giữa các phân vị đã ước lượng. Điểm số này được tính bằng giá trị lớn nhất giữa hiệu của phân vị dưới với giá trị thực tế và hiệu của giá trị thực tế với phân vị trên. Bước bốn, với dữ liệu mới, chúng ta xây dựng khoảng dự báo bằng cách điều chỉnh các phân vị đã dự báo với một giá trị dựa trên phân vị thực nghiệm của các điểm số phù hợp từ tập hiệu chuẩn.
Ý nghĩa đằng sau điểm số phù hợp là nếu giá trị thực tế nằm ngoài khoảng phân vị, điểm số sẽ đại diện cho mức độ sai số. Ngược lại, nếu giá trị thực tế nằm trong khoảng, điểm số sẽ luôn không dương. Bằng cách này, điểm số phù hợp tính đến cả trường hợp bao phủ thiếu và bao phủ thừa.
Triển khai thực tế trên Stata
Chúng ta sẽ sử dụng bộ dữ liệu nhà ở Ames để xây dựng khoảng dự báo bằng mô hình hồi quy phân vị gradient boosting phù hợp. Trước tiên, chúng ta thực hiện một số thao tác xử lý dữ liệu trong Stata như lấy logarit của giá trị bán nhà và tính toán tuổi thọ của căn nhà.
1. webuse ameshouses
2. generate logsaleprice = log(saleprice)
3. generate houseage = yrsold - yearbuilt
4. drop saleprice yrsold yearbuiltTiếp theo, chúng ta khởi tạo cụm dữ liệu và đưa dữ liệu vào h2o frame, sau đó chia dữ liệu thành các tập huấn luyện, hiệu chuẩn và kiểm tra theo tỷ lệ 50, 40 và 10 phần trăm.
1. h2o init
2. _h2oframe put, into(house)
3. _h2oframe split house, into(train calib test) split(0.5 0.4 0.1) rseed(1)
4. _h2oframe change trainMục tiêu là xây dựng khoảng dự báo với độ bao phủ 90 phần trăm. Chúng ta xác định mức sai số alpha là 0.1 và các ngưỡng phân vị dưới, trên lần lượt là 0.05 và 0.95. Sau đó, chúng ta huấn luyện mô hình gradient boosting cho phân vị dưới bằng lệnh h2oml gbregress.
1. local alpha = 0.1
2. local lower = 0.05
3. local upper = 0.95
4. global predictors overallqual grlivarea exterqual houseage garagecars totalbsmtsf stflrsf garagearea kitchenqual bsmtqual
5. h2oml gbregress logsaleprice $predictors, h2orseed(19) cv(3, modulo) loss(quantile, alpha(`lower')) ntrees(20(20)80) maxdepth(6(2)12) tune(grid(cartesian))
6. h2omlest store q_lower
7. h2omlpredict q_lower, frame(calib)Mô hình tốt nhất được chọn có 40 cây và độ sâu tối đa là 8. Chúng ta sử dụng mô hình này để lấy các phân vị dưới dự báo trên tập dữ liệu hiệu chuẩn. Tương tự, chúng ta thực hiện cho phân vị trên.
1. h2oml gbregress logsaleprice $predictors, h2orseed(19) cv(3, modulo) loss(quantile, alpha(`upper')) ntrees(40) maxdepth(8)
2. h2omlest store q_upper
3. h2omlpredict q_upper, frame(calib)Sau khi có các giá trị dự báo, chúng ta đưa dữ liệu từ h2o frame trở lại Stata để tính toán các điểm số phù hợp.
1. _h2oframe get logsaleprice q_lower q_upper using calib, clear
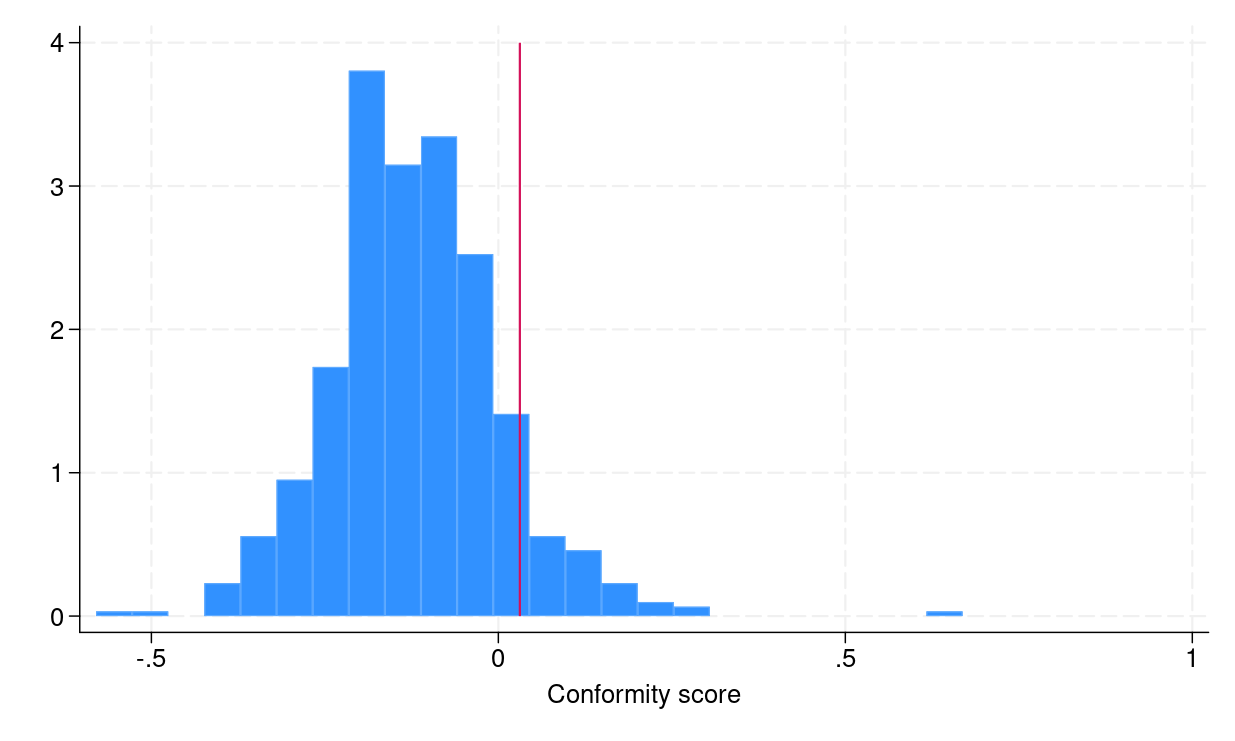
2. generate double conf_scores = max(q_lower - logsaleprice, logsaleprice - q_upper)Để xây dựng khoảng dự báo phù hợp, chúng ta cần tính toán phân vị thực nghiệm của các điểm số này bằng lệnh _pctile. Trong ví dụ này, giá trị phân vị thực nghiệm thu được là 0.031.
1. local emp_quantile = ceil((1 - 0.1) * (_N + 1))/ _N * 100
2. _pctile conf_score, percentiles(`emp_quantile')
3. local q = r(r1)Cuối cùng, chúng ta khôi phục các mô hình và thực hiện dự báo trên tập kiểm tra, sau đó tạo ra các ngưỡng biên dưới và biên trên cho khoảng dự báo.
1. h2omlest restore q_lower
2. h2omlpredict q_lower, frame(test)
3. h2omlest restore q_upper
4. h2omlpredict q_upper, frame(test)
5. _h2oframe get logsaleprice houseage q_lower q_upper using test, clear
6. generate double conf_lower = q_lower - `q'
7. generate double conf_upper = q_upper + `q'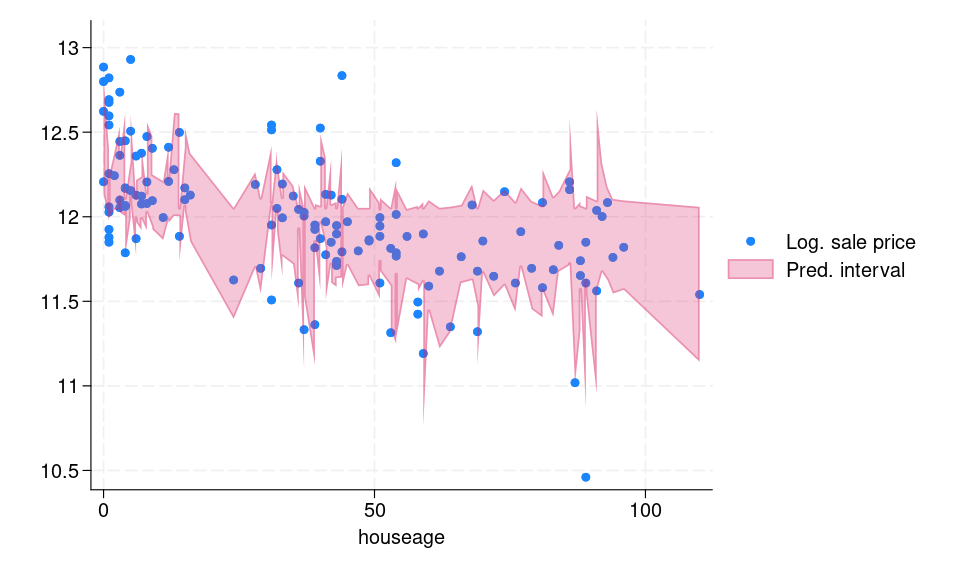
Kết quả cho thấy các khoảng dự báo có tính thích ứng, nghĩa là đối với các quan sát khó dự báo hoặc các điểm ngoại lệ, khoảng dự báo sẽ rộng hơn và ngược lại. Chúng ta có thể kiểm tra độ bao phủ thực tế trên tập kiểm tra bằng cách tạo biến chỉ báo xem giá trị thực tế có nằm trong khoảng dự báo hay không.
1. generate byte in_interval = 0
2. replace in_interval = 1 if inrange(logsaleprice, conf_lower, conf_upper)
3. summarize in_interval, meanonly
4. local avg_coverage = r(mean)
5. display `avg_coverage' * 100Kết quả cho thấy độ bao phủ trung bình thực tế đạt 90.5 phần trăm, rất gần với mục tiêu 90 phần trăm ban đầu. Điều này minh chứng cho sức mạnh của phương pháp CQR trong việc cung cấp các dự báo đi kèm với độ tin cậy cụ thể.
✨ Việc hiểu rõ độ không chắc chắn của mô hình thông qua khoảng dự báo giúp các nhà khoa học dữ liệu đưa ra những khuyến nghị an toàn và đáng tin cậy hơn trong các bài toán thực tế.
Hãy thử áp dụng quy trình CQR này trên một bộ dữ liệu khác và thay đổi mức sai số alpha từ 0.1 sang 0.05. Bạn nhận thấy khoảng dự báo thay đổi như thế nào về độ rộng và độ bao phủ thực tế?

