Trong phân tích thống kê hiện đại, việc xác định các hệ số của mô hình thường chỉ là bước khởi đầu. Điều mà các nhà nghiên cứu thực sự quan tâm là tác động của các biến độc lập lên giá trị kỳ vọng của biến kết quả. Từ phiên bản Stata 14.2, khả năng sử dụng lệnh margins sau khi ước lượng bằng phương pháp moment tổng quát đã mở ra một công cụ mạnh mẽ để phân tích sâu hơn các mô hình phức tạp. Bài viết này sẽ hướng dẫn cách sử dụng margins và marginsplot để ước lượng tác động của các biến cộng biến trong mô hình Probit được thực hiện qua phương pháp GMM.
Lệnh margins hoạt động bằng cách tính toán các số liệu thống kê từ dự báo của một mô hình đã khớp trước đó tại các giá trị cố định của một số biến cộng biến, sau đó lấy trung bình hoặc tích phân trên các biến còn lại. Phương pháp này cực kỳ hữu ích để ước lượng các tham số trung bình của quần thể như trung bình biên, tác động điều trị trung bình hoặc tác động trung bình của một biến lên trung bình có điều kiện.
Mô hình Probit và phương pháp moment tổng quát
Đối với một kết quả nhị phân y và các biến dự báo x, mô hình Probit giả định rằng biến y bằng một khi tổng tích của x với hệ số beta cộng với sai số lớn hơn không, trong đó sai số tuân theo phân phối chuẩn hóa. Hàm trung bình có điều kiện của y khi biết x chính là hàm phân phối tích lũy chuẩn hóa của tích x và beta.
Chúng ta có thể sử dụng phương pháp moment tổng quát để ước lượng hệ số beta với các điều kiện moment mẫu dựa trên hàm mật độ chuẩn và hàm phân phối chuẩn hóa. Ngoài việc ước lượng các thông số của mô hình, chúng ta thường quan tâm đến việc biến y thay đổi thế nào khi một trong các biến x thay đổi. Thay vì tính toán thủ công các thay đổi này từ kết quả ước lượng, việc sử dụng margins sẽ giúp tự động hóa quá trình và quan trọng hơn là điều chỉnh sai số chuẩn một cách chính xác.
Ước lượng tác động của biến cộng biến
Để bắt đầu, chúng ta thực hiện ước lượng hệ số beta bằng lệnh gmm trên dữ liệu mô phỏng. Trong ví dụ này, biến nhị phân y được hồi quy theo biến giả d và các biến liên tục x, z. Mô hình bao gồm cả số hạng bậc hai cho x và các tương tác của x, z với biến d.
1. gmm (cond(y,normalden({y: i.d##(c.x c.x#c.x c.z) i.d _cons})/
2> normal({y:}),-normalden({y:})/normal(-{y:}))),
3> instruments(i.d##(c.x c.x#c.x c.z) i.d) onestep
4Step 1
5Iteration 0: GMM criterion Q(b) = .26129294
6Iteration 1: GMM criterion Q(b) = .01621062
7Iteration 2: GMM criterion Q(b) = .00206357
8Iteration 3: GMM criterion Q(b) = .00033537
9Iteration 4: GMM criterion Q(b) = 4.916e-06
10Iteration 5: GMM criterion Q(b) = 1.539e-08
11Iteration 6: GMM criterion Q(b) = 3.361e-13
12note: model is exactly identified
13GMM estimation
14Number of parameters = 8
15Number of moments = 8
16Initial weight matrix: Unadjusted Number of obs = 5,000
17------------------------------------------------------------------------------
18 | Robust
19 | Coef. Std. Err. z P>|z| [95% Conf. Interval]
20-------------+----------------------------------------------------------------
21 1.d | 1.752056 .0987097 17.75 0.000 1.558588 1.945523
22 x | .2209241 .0311227 7.10 0.000 .1599247 .2819235
23 |
24 c.x#c.x | -.2864622 .0199842 -14.33 0.000 -.3256305 -.2472939
25 |
26 z | -.6813765 .0558371 -12.20 0.000 -.7908152 -.5719379
27 |
28 d#c.x |
29 1 | .311213 .0543018 5.73 0.000 .2047835 .4176426
30 |
31 d#c.x#c.x |
32 1 | -.7297855 .0513903 -14.20 0.000 -.8305086 -.6290624
33 |
34 d#c.z |
35 1 | -.4272026 .0807842 -5.29 0.000 -.5855368 -.2688684
36 |
37 _cons | .1180114 .0520303 2.27 0.023 .0160339 .2199888
38------------------------------------------------------------------------------
39Instruments for equation 1: 0b.d 1.d x c.x#c.x z 0b.d#co.x 1.d#c.x 0b.d#co.x#co.x 1.d#c.x#c.x 0b.d#co.z
40 1.d#c.z _consSau khi đã có các hệ số, chúng ta sử dụng margins để ước lượng tác động trung bình khi thay đổi x lên một đơn vị. Lệnh dưới đây tính toán sự khác biệt giữa biểu thức tại giá trị x cộng một và giá trị x hiện tại, lấy trung bình trên toàn bộ quần thể.
1. margins, at(x=generate(x)) at(x=generate(x+1)) vce(unconditional)
2> expression(normal(xb())) contrast(atcontrast(r) nowald)
3Contrasts of predictive margins
4Expression : normal(xb())
51._at : x = x
62._at : x = x+1
7--------------------------------------------------------------
8 | Unconditional
9 | Contrast Std. Err. [95% Conf. Interval]
10-------------+------------------------------------------------
11 _at |
12 (2 vs 1) | -.0108121 .0040241 -.0186993 -.002925
13--------------------------------------------------------------Đối với các biến rời rạc như biến d, chúng ta có thể sử dụng ký hiệu tương phản trực tiếp trong margins để ước lượng tác động khi chuyển từ d bằng không sang d bằng một. Kết quả cho thấy trung bình trên quần thể, việc thay đổi này làm tăng xác suất thành công thêm khoảng mười bốn phần trăm.
1. margins r.d, expression(normal(xb())) vce(unconditional) contrast(nowald)
2Contrasts of predictive margins
3Expression : normal(xb())
4--------------------------------------------------------------
5 | Unconditional
6 | Contrast Std. Err. [95% Conf. Interval]
7-------------+------------------------------------------------
8 d |
9 (1 vs 0) | .1370625 .0093206 .1187945 .1553305
10--------------------------------------------------------------Trực quan hóa tác động bằng đồ thị
Ngoài việc tính toán các con số trung bình, việc quan sát sự thay đổi của tác động tại các giá trị khác nhau của biến cộng biến là rất quan trọng. Lệnh marginsplot giúp chúng ta trực quan hóa các kết quả từ margins để tìm ra các mô hình hoặc xu hướng tiềm ẩn.
Ví dụ, chúng ta muốn xem tác động của việc thay đổi biến d thay đổi như thế nào tại các mức độ khác nhau của x.
1. margins r.d, at(x = (-1 -.5 0 .5 1 1.5 2))
2> expression(normal(xb())) noatlegend
3> vce(unconditional) contrast(nowald)
4. marginsplot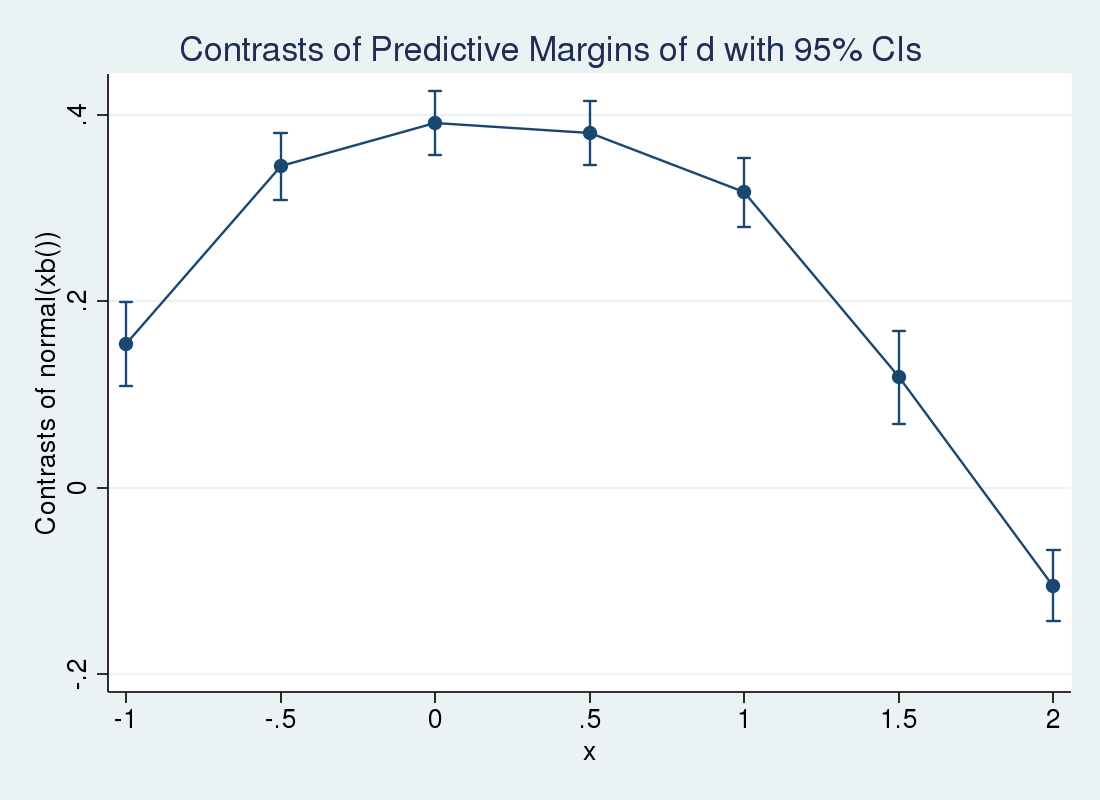
Đồ thị cho thấy tác động tăng lên khi x nhỏ và bắt đầu giảm khi x lớn dần. Để hiểu rõ hơn, chúng ta có thể vẽ các đường trung bình có điều kiện tách biệt cho hai nhóm d bằng không và d bằng một.
1. margins, at(x = (-1 -.5 0 .5 1 1.5 2)) over(d)
2> expression(normal(xb())) noatlegend
3> vce(unconditional)
4. marginsplot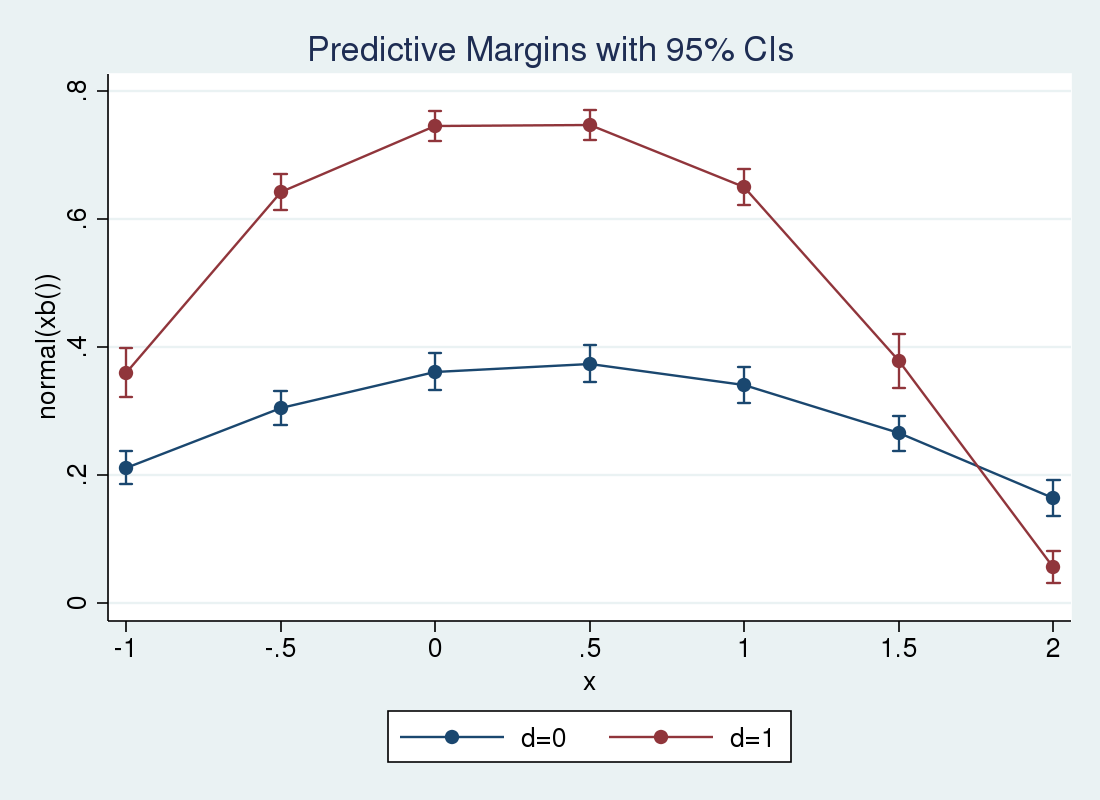
Qua đồ thị thứ hai, chúng ta có thể thấy rõ điểm giao thoa giữa hai đường xác suất, nơi mà tác động của việc chuyển đổi d từ không sang một bắt đầu đổi dấu từ dương sang âm, cụ thể là tại vị trí x xấp xỉ một phẩy bảy mươi lăm.
Ước lượng tác động biên vi phân
Trong nhiều trường hợp, nhà nghiên cứu quan tâm đến tác động biên, tức là đạo hàm của giá trị kỳ vọng theo một biến liên tục. Đây là thay đổi chuẩn hóa của trung bình khi có một thay đổi cực nhỏ ở biến cộng biến. Lệnh margins với tùy chọn dydx sẽ tự động thực hiện việc tính đạo hàm này.
1. margins, expression(normal(xb())) vce(unconditional) dydx(x z)
2Average marginal effects Number of obs = 5,000
3Expression : normal(xb())
4dy/dx w.r.t. : x z
5------------------------------------------------------------------------------
6 | Unconditional
7 | dy/dx Std. Err. z P>|z| [95% Conf. Interval]
8-------------+----------------------------------------------------------------
9 x | .0121859 .0045472 2.68 0.007 .0032736 .0210983
10 z | -.1439682 .0062519 -23.03 0.000 -.1562217 -.1317146
11------------------------------------------------------------------------------Việc kết hợp gmm và margins mang lại sự linh hoạt tối đa. Bạn có thể ước lượng một mô hình với các điều kiện moment tối giản, sau đó thực hiện nhiều loại ước lượng biên khác nhau mà không cần phải thiết lập lại các điều kiện moment phức tạp trong mô hình gốc.
✨ Sử dụng margins sau GMM giúp bạn tách biệt quá trình ước lượng hệ số và quá trình tính toán tác động thực tế, đảm bảo sai số chuẩn luôn được điều chỉnh đúng cho các dự báo phi tuyến tính mà không cần tính toán đạo hàm thủ công phức tạp.
Câu hỏi tư duy: Tại sao khi sử dụng phương pháp GMM, việc tính toán sai số chuẩn cho các tác động biên bằng lệnh margins lại ưu việt hơn so với việc tính toán thủ công dựa trên kết quả của ma trận hiệp biến? Hãy thử áp dụng quy trình này cho một mô hình hồi quy Poisson sử dụng GMM và so sánh kết quả.

