Hôm nay đội ngũ SciEco xin gửi tới các bạn Blog002 về Data Wrangling (Sắp xếp dữ liệu) bằng dplyr
Lưu ý: Để sử dụng dplyr, trước mỗi phiên làm việc cần phải đọc gói bằng lệnh library() để sử dụng
1library(dplyr)Lấy cột cụ thể trong dataset bằng hàm select()
Đầu tiên, sử dụng hàm glimpse() để xem tổng quan về dữ liệu
1glimpse(starwars)
glimpse() giúp xem nhanh về cấu trúc dữ liệu. Với dataset này bao gồm 87 dòng và 14 cột trong dataset. Ngoài ra ta còn có thể xem nhanh về data type (kiểu dữ liệu) của từng cột và một số dữ liệu đầu tiên trong data
Ta có thể thấy, 3 cột cuối cùng (films, vehicles và starships) có kiểu dữ liệu đặc biệt là kiểu list (xem chi tiết tại đây). Như đã biết, kiểu list trong R giúp ta có thể lưu trữ liệu loại dữ liệu cùng 1 lúc (từng phần tử trong 1 list có thể là số, text, hoặc thậm chí data frame hay list con).
Như vậy cột list này giúp có thể lưu trữ được dạng dữ liệu lồng nhau (nested data) xem chi tiết tại (link). Tuy nhiên trường hợp này ta không cần đến nên có thể dùng hàm select() để chỉ lấy những cột cần dùng.
1starwars %>%
2 select(name, height, mass, hair_color, skin_color,
3 eye_color, birth_year, sex, gender, homeworld, species)
Sau khi sử dụng hàm select, kết quả trả về là 1 data frame với những cột được chọn để sử dụng, những cột không dùng sẽ bị loại bỏ.
Lưu ý rằng, hàm select() không thay đổi dữ liệu gốc mà chỉ trả về 1 data frame mới theo yêu cầu. Do đó, muốn chỉnh sửa data frame gốc cần phải gán ghi đè lại vào biến gốc
1starwars <- starwars %>%
2 select(name, height, mass, hair_color, skin_color,
3 eye_color, birth_year, sex, gender, homeworld, species)Ngoài chọn cột để dùng, ta có thể dùng dấu - để bỏ đi những cột không cần thiết:
1starwars %>% select(-films, -vehicles, -starships)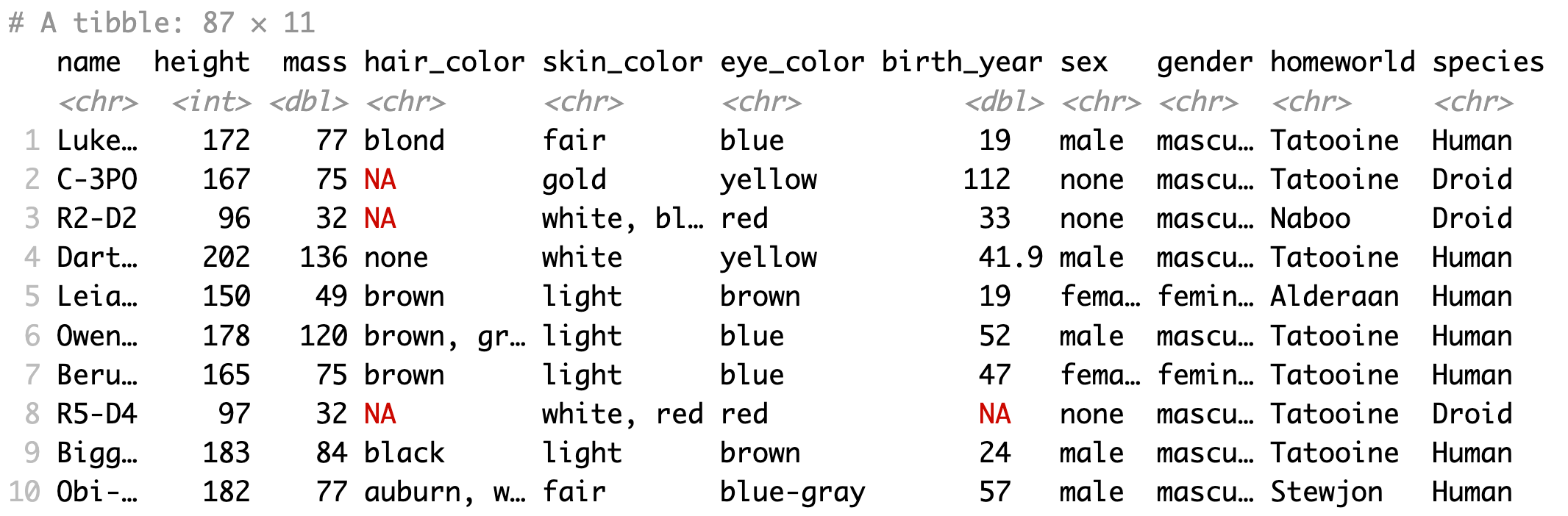
Cuối cùng, ta có thể sử dụng : để lấy từ cột này đến cột kia, ví dụ name:species, ta lấy những cột từ cột name đến cột species
1starwars %>% select(name:species)
Đổi tên cột bằng hàm rename()
Ta có thể đổi tên cột bằng cú pháp sau:
1starwars %>%
2 rename(new_name = old_name)new_namelà tên mớiold_namelà tên cũ
Ví dụ muốn để tên cột từ height thành height_cm:
1starwars %>%
2 select(name:species) %>%
3 rename(height_cm=height)
Sắp xếp (sort) dữ liệu bằng hàm arrange()
1starwars %>%
2 select(name:mass) %>%
3 arrange(height)
Ta thấy dữ liệu đã được sắp xếp sao cột cột height theo thứ tự tăng dần
Ta có thể dùng kết hợp hàm desc() để sắp xếp quan sát theo thứ tự giảm dần của cột height
1starwars %>%
2 select(name:mass) %>%
3 arrange(desc(height))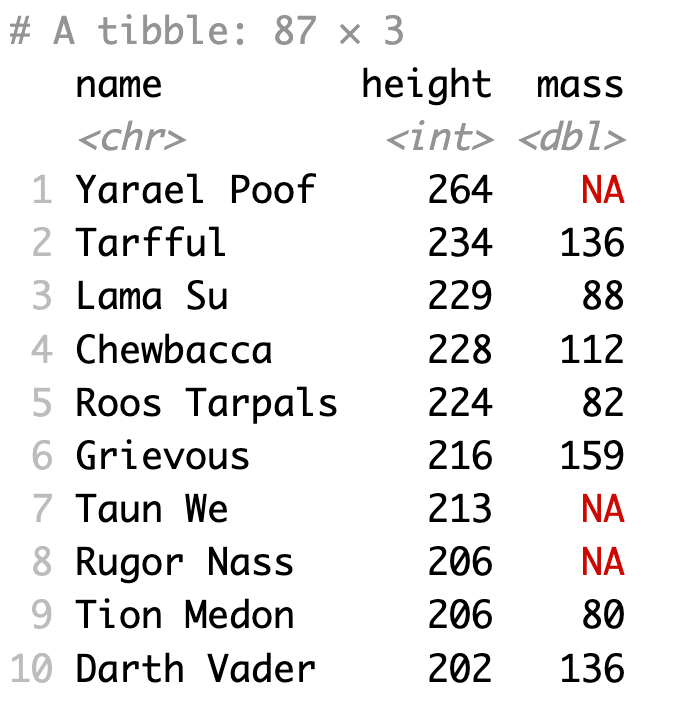
Ta cũng có thể sort cùng lúc nhiều cột cùng lúc như ví dụ sau, cột homeworld được sắp xếp trước theo thứ tự từ A-Z sau đó cột height được sắp xếp theo thứ tự giảm dần.
1starwars %>%
2 select(name, homeworld, height) %>%
3 arrange(homeworld, desc(height))
Chọn dòng bất kì bằng slice()
Ví dụ bên dưới, dùng hàm slice() để chỉ lấy 3 dòng đầu tiên
1starwars %>%
2 slice(1:3) %>%
3 select(height, mass)
Lọc dữ liệu bằng filter()
Ví dụ dưới: ta lọc các dòng với species là Human và homeworld là Tatooine
1starwars %>%
2 select(name, species, homeworld, height, mass, birth_year) %>%
3 filter(species=="Human" & homeworld=="Tatooine")
Tạo cột mới bằng mutate()
Giả sử cần tạo cột mới là BMI theo công thức BMI = mass / (height/100)^2
1starwars %>%
2 select(name:mass) %>%
3 mutate(BMI = mass/((height/100)^2))
4 # mutate(new_column = something)
Ta có thể tạo cùng lúc nhiều cột bằng cách viết cách nhau bởi dấu phẩy:
1starwars %>%
2 select(name:mass) %>%
3 mutate(
4 height_ft = height * 0.0328084, # convert height from cm into feet
5 weight_pounds = mass * 2.20462 # convert weight from kg into pounds
6 )
Có thể kết hợp mutate với hàm case_when() để tạo cột mới dựa vào điều kiện của cột khác
1starwars %>%
2 select(name:mass) %>%
3 mutate(
4 height_ft = height * 0.0328084,
5 height_group = case_when(
6 is.na(height) ~ "Missing",
7 height_ft<5 ~ "Under 5ft",
8 height_ft>6 ~ "Over 6ft",
9 TRUE ~ "Between 5-6ft"
10 )
11 )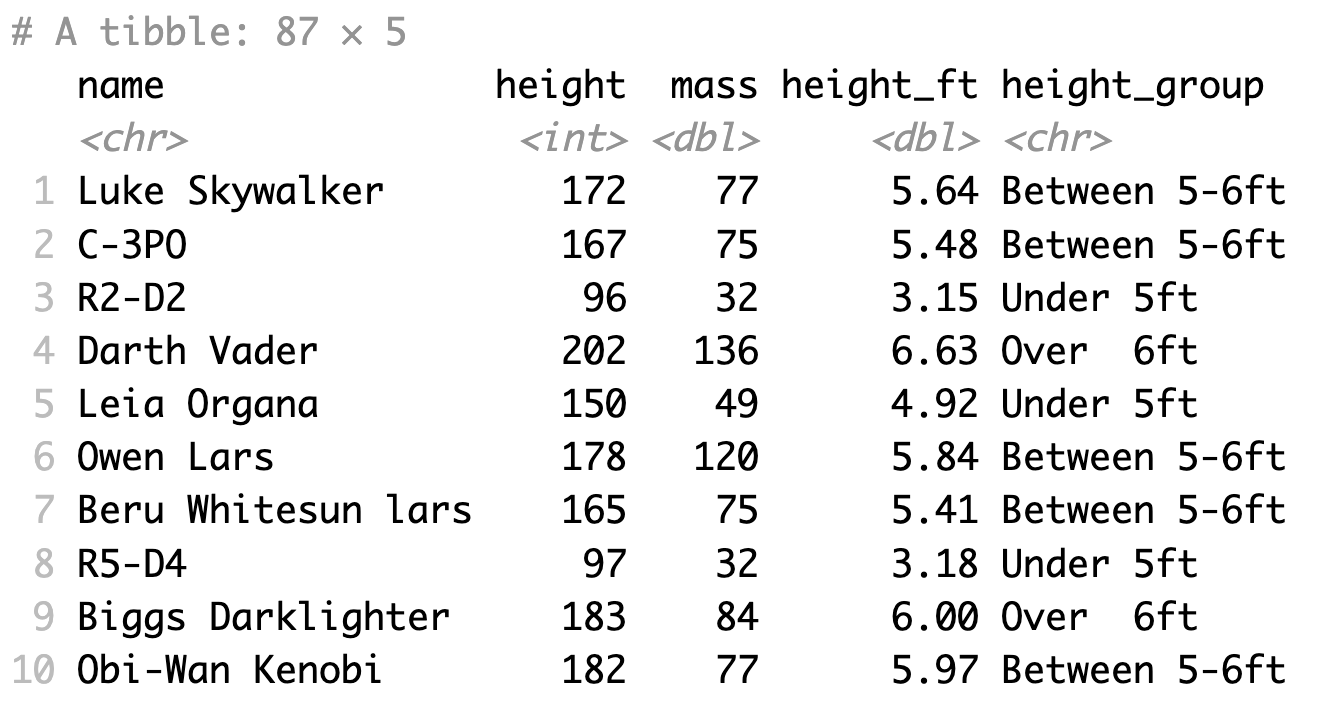
TRUE ~ trong hàm case_when() sẽ nhận những trường hợp còn lại, không thoả các điều kiện bên trên.
Ví dụ bên dưới nếu không sử dụng TRUE ~ sẽ gặp giá trị NA vì không thoả các điều kiện có trong hàm case_when()
1starwars %>%
2 select(name:mass) %>%
3 mutate(
4 height_ft = height * 0.0328084,
5 height_group = case_when(
6 is.na(height) ~ "Missing",
7 height_ft<5 ~ "Under 5ft",
8 height_ft>6 ~ "Over 6ft"
9 )
10 )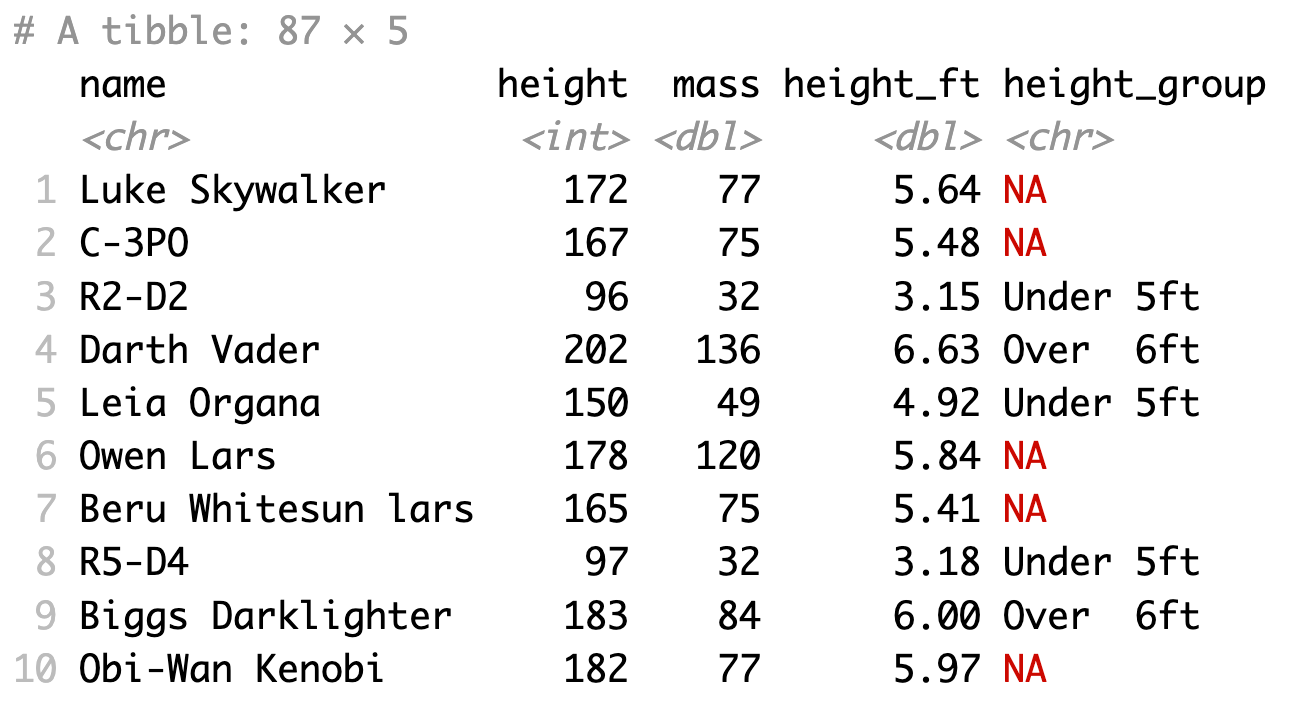
Tổng hợp (aggregate) dữ liệu bằng summarise()
Ta có thể tạo bảng tổng hợp dữ liệu bằng hàm summarise có sử dụng kết hợp với các hàm tổng hợp có sẵn, ví dụ tính trung bình mean:
1starwars %>%
2 summarise(avg_height=mean(height, na.rm=T))
Lưu ý cần phải thêm na.rm=TRUE vì trong dữ liệu bị khuyết (missing data)
Ta có thể tính cùng lúc nhiều thống kê trong 1 bảng, như ví dụ bên dưới:
1starwars %>%
2 summarise(
3 num_records=n(), # Number of records in the table
4 distinct_species=n_distinct(species), # Number of unique values of "species"
5 avg_mass=mean(mass, na.rm=T), # Average mass excluding any missing values
6 median_mass=median(mass, na.rm=T), # Median mass excluding any missing values
7 IQR_mass=IQR(mass, na.rm=T), # The interquartile range for mass excluding any missing values
8 shortest=min(height, na.rm=T), # Min value of height excluding any missing values
9 tallest=max(height, na.rm=T) # Max value of height excluding any missing values
10 ) 
Tổng hợp theo từng nhóm (Aggregate by groups) bằng group_by()
Tương tự như SQL, ta có thể tổng hợp theo nhóm bằng hàm group_by, ví dụ:
1starwars %>%
2 group_by(species, gender)
Kết quả trả về là 1 data frame, tuy nhiên điểm khác tại dòng thứ hai:
Tức là dữ liệu này đã được nhóm theo 2 cột là species và gender
1Groups: species, gender [42]Có thể dùng ungroup() để huỷ việc tạo nhóm
1starwars %>%
2 group_by(species, gender) %>%
3 ungroup()
Có thể dùng hàm group_vars() để kiểm tra xem dữ liệu đã được nhóm hay chưa, nếu có, kết quả trả về là các cột mà dữ liệu đã được nhóm theo
1starwars %>%
2 group_by(species, gender) %>%
3 group_vars()1[1] "species" "gender"Sau khi group_by ta sử dụng hàm summarise để tính toán tổng hợp, ví dụ ta cần tính chiều cao trung bình của từng nhóm
1starwars %>%
2 group_by(species) %>%
3 summarise(avg_height = mean(height, na.rm=T))1# A tibble: 38 x 2
2 species avg_height
3
4 1 Aleena 79
5 2 Besalisk 198
6 3 Cerean 198
7 4 Chagrian 196
8 5 Clawdite 168
9 6 Droid 131.
10 7 Dug 112
11 8 Ewok 88
12 9 Geonosian 183
1310 Gungan 209.
14# ... with 28 more rowsTa cũng có thể kết hợp group_by với mutate để tạo cột mới được tổng hợp theo nhóm. Ví dụ ta tạo cột mới avg_species_height là chiều cao trung bình của từng nhóm. Từ nhiều cao trung bình tính toán được, ta phân từng quan sát vào từng nhóm bằng cách tạo biến mới height_group trong đó:
height_group = shortkhiavg_species_height <= 0.8height_group = tallkhiavg_species_height >= 1.2height_group = averagevới những trường hợp còn lại
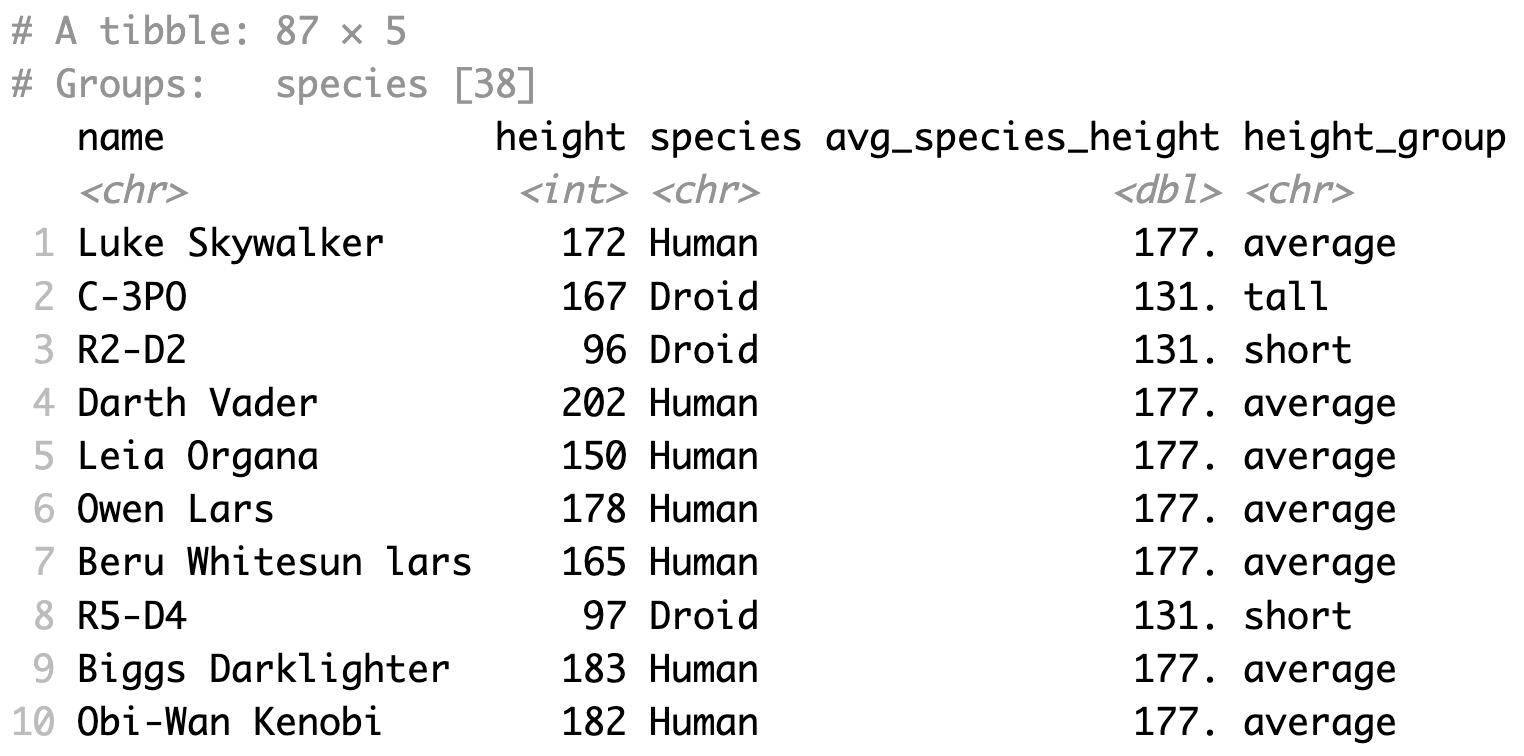
1starwars %>%
2 select(name, height, species) %>%
3 group_by(species) %>%
4 mutate(
5 avg_species_height=mean(height, na.rm=T),
6 height_group=case_when(
7 height/avg_species_height<=.8 ~ "short",
8 height/avg_species_height>=1.2 ~ "tall",
9 TRUE ~ "average")
10 )