
Thị trường tiền mã hóa vừa chứng kiến một cột mốc lịch sử khi giá Bitcoin chạm ngưỡng 125.664 đô la vào ngày 5 tháng 10. Sự bùng nổ này được thúc đẩy bởi dòng vốn ròng kỷ lục trị giá 3,24 tỷ đô la đổ vào các quỹ ETF Bitcoin giao ngay cùng nhu cầu ngày càng tăng từ công chúng. Trong bối cảnh đó, việc phân tích và dự báo xu hướng của các quỹ hoán đổi danh mục liên quan đến công nghệ blockchain trở nên quan trọng hơn bao giờ hết đối với các nhà đầu tư. Bài viết này sẽ hướng dẫn cách thực hiện dự báo lồng nhau cho hai quỹ ETF blockchain tiêu biểu bằng cách tận dụng sức mạnh tính toán song song của backend Spark.
Thiết lập môi trường và thu thập dữ liệu
Để bắt đầu, chúng ta cần thiết lập kết nối với Spark và chuẩn bị các thư viện cần thiết trong hệ sinh thái tidymodels và modeltime. Việc sử dụng Spark giúp tăng tốc quá trình huấn luyện mô hình khi xử lý nhiều chuỗi thời gian cùng lúc. Hai quỹ được lựa chọn để phân tích bao gồm Invesco CoinShares Global Blockchain và iShares Blockchain and Tech.
1library(modeltime)
2library(timetk)
3library(tidymodels)
4library(dplyr)
5library(tidyquant)
6library(sparklyr)
7sc <- spark_connect(master = "local")
8parallel_start(sc, .method = "spark")
9df_bchn <-
10 tq_get("BCHN.L") %>%
11 select(date, 'Invesco CoinShares Global Blockchain' = close)
12df_iblc <-
13 tq_get("IBLC") %>%
14 select(date, 'iShares Blockchain and Tech' = close)
15df_survey <-
16 df_bchn %>%
17 left_join(df_iblc) %>%
18 pivot_longer(-date,
19 names_to = "id",
20 values_to = "value") %>%
21 filter(date >= last(date) - months(6)) %>%
22 drop_na()Cấu trúc dữ liệu lồng nhau
Một trong những thách thức khi làm việc với dự báo lồng nhau là việc xử lý các giá trị khuyết thiếu. Trong phân tích này, các đặc trưng về độ trễ và làm mượt không được đưa vào công thức xử lý vì chúng có thể tạo ra các giá trị rỗng gây lỗi cho cấu trúc dữ liệu lồng nhau. Chúng ta sẽ tiến hành mở rộng chuỗi thời gian thêm 15 ngày cho mục đích dự báo tương lai.
1nested_data_tbl <-
2 df_survey %>%
3 dplyr::select(id,
4 date = date,
5 value = value) %>%
6 extend_timeseries(
7 .id_var = id,
8 .date_var = date,
9 .length_future = 15
10 ) %>%
11 nest_timeseries(
12 .id_var = id,
13 .length_future = 15
14 ) %>%
15 split_nested_timeseries(
16 .length_test = 15
17 )Xây dựng và huấn luyện mô hình
Chúng ta sẽ sử dụng hai thuật toán phổ biến là XGBoost và Prophet để so sánh hiệu suất. Mỗi mô hình sẽ được đóng gói trong một quy trình làm việc riêng biệt với các bước tiền xử lý dữ liệu tương ứng như tạo đặc trưng từ ngày tháng, xử lý biến giả và xử lý đa cộng tuyến.
Triển khai XGBoost và Prophet
Mô hình XGBoost tập trung vào việc học từ các đặc trưng trích xuất từ chữ ký thời gian, trong khi Prophet tối ưu hóa việc xử lý các yếu tố mùa vụ theo tuần và theo ngày.
1rec_xgb <-
2 recipe(value ~ ., extract_nested_train_split(nested_data_tbl)) %>%
3 step_timeseries_signature(date) %>%
4 step_rm(date) %>%
5 step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
6 step_zv(all_predictors()) %>%
7 step_impute_linear(all_numeric_predictors())
8wflw_xgb <-
9 workflow() %>%
10 add_model(boost_tree("regression") %>%
11 set_engine("xgboost")) %>%
12 add_recipe(rec_xgb)
13rec_prophet <-
14 recipe(value ~ date, extract_nested_train_split(nested_data_tbl)) %>%
15 step_date(date, features = c("dow", "month", "year", "doy")) %>%
16 step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
17 step_zv(all_predictors()) %>%
18 step_impute_linear(all_numeric_predictors())
19wflw_prophet <-
20 workflow() %>%
21 add_model(
22 prophet_reg("regression") %>%
23 set_engine("prophet",
24 seasonality_yearly = FALSE,
25 seasonality_weekly = TRUE,
26 seasonality_daily = TRUE)) %>%
27 add_recipe(rec_prophet)Kết quả dự báo và đánh giá
Sau khi huấn luyện, chúng ta tiến hành chọn lọc mô hình tốt nhất dựa trên sai số phần trăm tuyệt đối trung bình. Việc tính toán song song thông qua Spark giúp quá trình khớp mô hình diễn ra nhanh chóng ngay cả khi số lượng chuỗi thời gian tăng lên.
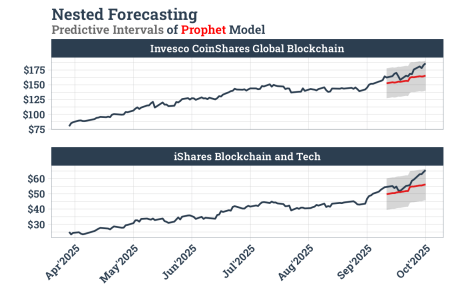
1nested_modeltime_tbl <-
2 nested_data_tbl %>%
3 modeltime_nested_fit(
4 wflw_xgb,
5 wflw_prophet,
6 control = control_nested_fit(allow_par = TRUE, verbose = TRUE)
7 )
8best_nested_modeltime_tbl <-
9 nested_modeltime_tbl %>%
10 modeltime_nested_select_best(
11 metric = "mape",
12 minimize = TRUE,
13 filter_test_forecasts = TRUE
14 )
15best_nested_modeltime_tbl %>%
16 extract_nested_test_forecast() %>%
17 group_by(id) %>%
18 plot_modeltime_forecast(
19 .facet_ncol = 1,
20 .interactive = FALSE,
21 .line_size = 1
22 )Kết quả từ biểu đồ cho thấy khả năng bám sát xu hướng thực tế của các mô hình, giúp nhà đầu tư có cái nhìn định lượng về biến động ngắn hạn của các quỹ ETF blockchain trong giai đoạn thị trường hưng phấn.
✨ Tận dụng backend Spark trong dự báo chuỗi thời gian lồng nhau không chỉ giúp tối ưu hóa hiệu suất tính toán mà còn cho phép mở rộng quy mô phân tích hàng nghìn mã cổ phiếu cùng lúc với độ chính xác cao.
Hãy thử thay đổi tham số trong mô hình Prophet hoặc bổ sung thêm các quỹ ETF công nghệ khác vào bộ dữ liệu để kiểm tra xem liệu độ chính xác của dự báo có thay đổi đáng kể hay không?

