Trong cách tiếp cận tần suất học đối với thống kê, các bộ ước lượng là những biến ngẫu nhiên vì chúng là các hàm số của dữ liệu ngẫu nhiên. Phân phối mẫu hữu hạn của hầu hết các bộ ước lượng được sử dụng trong công việc ứng dụng thường không được biết trước, bởi lẽ chúng là những hàm phi tuyến tính phức tạp của dữ liệu ngẫu nhiên. Thay vào đó, chúng ta thường sử dụng các thuộc tính hội tụ trong mẫu lớn của các bộ ước lượng này để xấp xỉ hành vi của chúng trong các mẫu hữu hạn.
Hai thuộc tính hội tụ quan trọng nhất là tính nhất quán và tính chuẩn tiệm cận. Một bộ ước lượng nhất quán sẽ tiến gần một cách tùy ý đến giá trị thực về mặt xác suất. Trong khi đó, phân phối của một bộ ước lượng chuẩn tiệm cận sẽ ngày càng giống với phân phối chuẩn khi cỡ mẫu tăng lên. Chúng ta sử dụng một phiên bản đã được định tâm và thu phóng lại của phân phối chuẩn này để xấp xỉ phân phối mẫu hữu hạn của các bộ ước lượng.
Bài viết này sẽ minh họa ý nghĩa của tính nhất quán và tính chuẩn tiệm cận thông qua phương pháp mô phỏng Monte Carlo bằng phần mềm Stata.
Tính nhất quán của bộ ước lượng
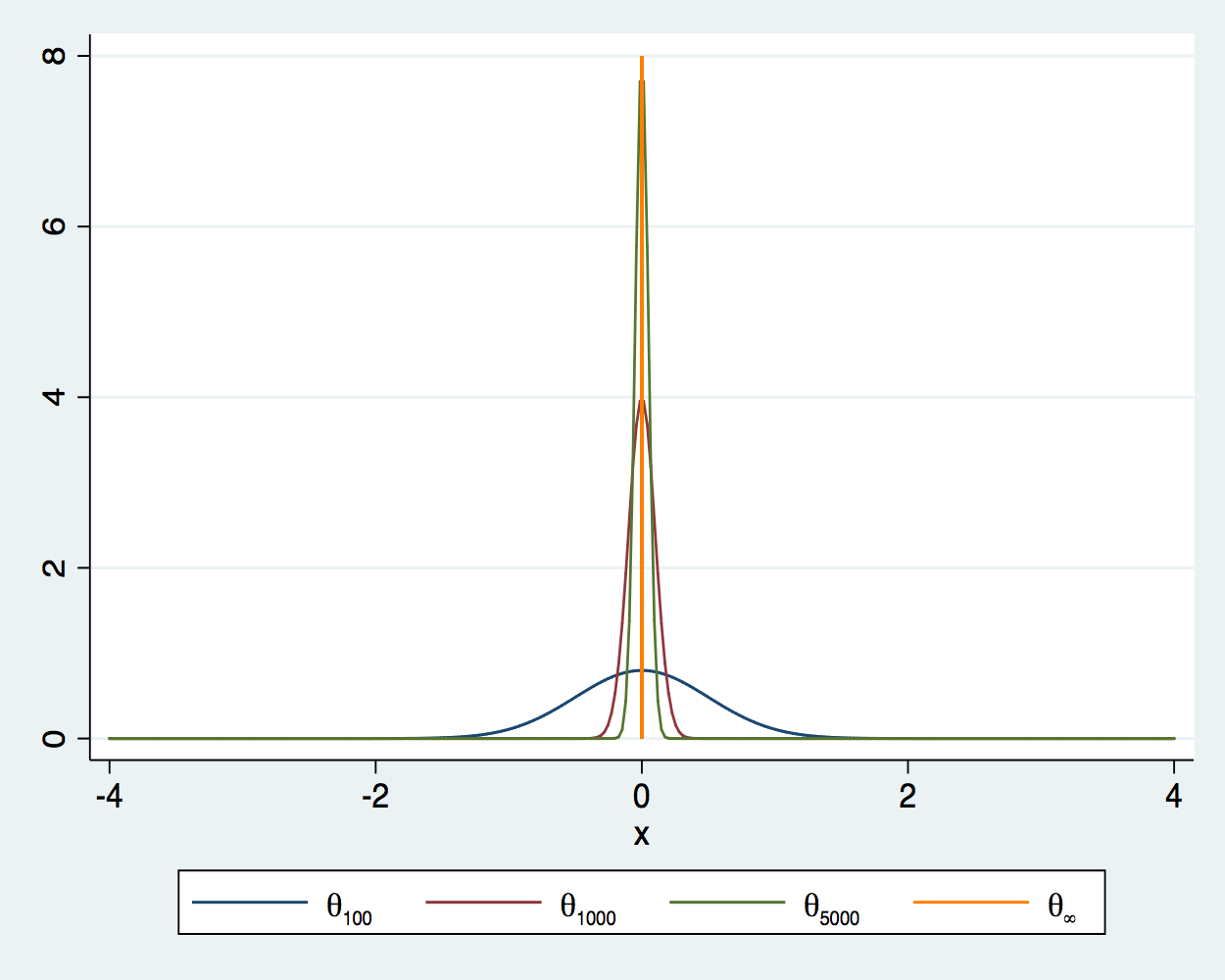
Một bộ ước lượng nhất quán sẽ tiến sát đến giá trị thực khi bạn tăng cỡ mẫu. Nói cách khác, xác suất để một bộ ước lượng nhất quán nằm ngoài vùng lân cận của giá trị thực sẽ tiến về không khi cỡ mẫu tăng lên. Quá trình hội tụ của một bộ ước lượng theta tại các cỡ mẫu 100, 1000 và 5000 khi giá trị thực bằng không được minh họa rất rõ nét qua biểu đồ bên dưới. Khi cỡ mẫu tăng, mật độ phân phối tập trung chặt chẽ hơn xung quanh giá trị thực. Khi cỡ mẫu tiến tới vô cực, đường cong mật độ thu hẹp lại thành một đỉnh nhọn tại chính xác giá trị thực.
Để làm rõ hơn, chúng ta sẽ xem xét trung bình mẫu như một bộ ước lượng nhất quán cho giá trị trung bình của một biến ngẫu nhiên độc lập và phân phối đồng nhất có giá trị trung bình và phương sai hữu hạn. Trong ví dụ này, dữ liệu được rút ngẫu nhiên từ phân phối chi bình phương với một bậc tự do. Giá trị thực ở đây bằng một, vì trung bình của phân phối chi bình phương với một bậc tự do là một.
Đoạn mã dưới đây thực hiện mô phỏng Monte Carlo đối với trung bình mẫu từ các mẫu có kích thước 1000.
1clear all
2set seed 12345
3postfile sim m1000 using sim1000, replace
4forvalues i = 1/1000 {
5 quietly capture drop y
6 quietly set obs 1000
7 quietly generate y = rchi2(1)
8 quietly summarize y
9 quietly post sim (r(mean))
10}
11postclose sim
12use sim1000, clear
13summarize m1000Kết quả tóm tắt từ đoạn mã trên sẽ cho thấy giá trị trung bình của 1000 ước lượng rất gần với một. Độ lệch chuẩn của 1000 ước lượng này xấp xỉ 0.0442, đo lường mức độ phân tán của bộ ước lượng xung quanh giá trị thực là một.
Bây giờ, chúng ta sẽ thực hiện một mô phỏng tương tự nhưng với cỡ mẫu lớn hơn rất nhiều là 100000.
1clear all
2postfile sim m100000 using sim100000, replace
3forvalues i = 1/1000 {
4 quietly capture drop y
5 quietly set obs 100000
6 quietly generate y = rchi2(1)
7 quietly summarize y
8 quietly post sim (r(mean))
9}
10postclose sim
11use sim100000, clear
12summarize m100000Với cỡ mẫu 100000, độ lệch chuẩn giảm xuống chỉ còn khoảng 0.0043. Điều này cho thấy phân phối của bộ ước lượng với cỡ mẫu 100000 bám sát giá trị thực chặt chẽ hơn rất nhiều so với cỡ mẫu 1000. Chúng ta có thể kết hợp hai tập dữ liệu và vẽ biểu đồ mật độ để so sánh trực quan.
1merge 1:1 _n using sim1000
2kdensity m1000, n(500) generate(x_1000 f_1000) kernel(gaussian) nograph
3label variable f_1000 "N=1000"
4kdensity m100000, n(500) generate(x_100000 f_100000) kernel(gaussian) nograph
5label variable f_100000 "N=100000"
6graph twoway (line f_1000 x_1000) (line f_100000 x_100000)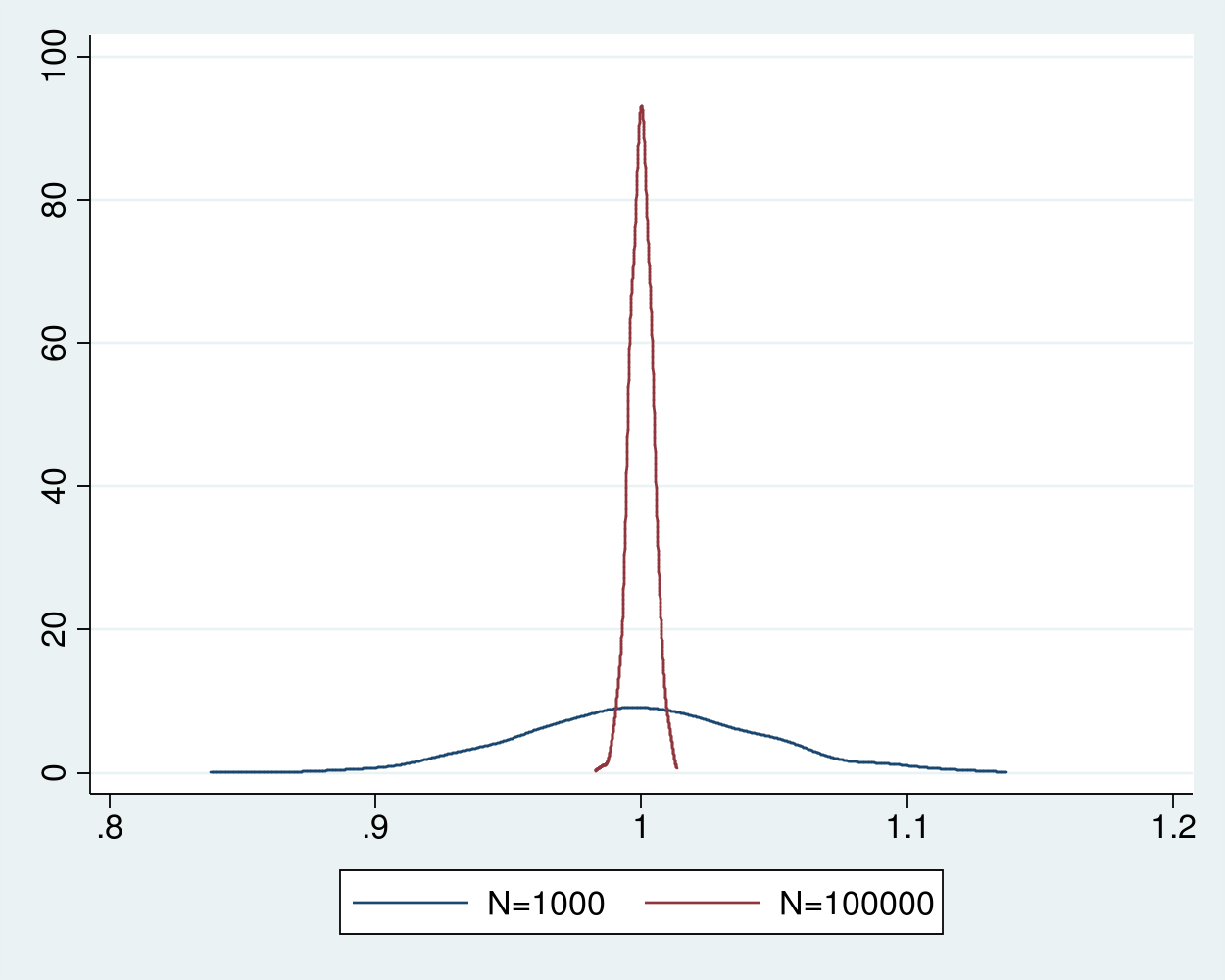
Trung bình mẫu là một bộ ước lượng nhất quán cho trung bình của một biến ngẫu nhiên chi bình phương với một bậc tự do nhờ vào luật số lớn yếu. Định lý này chỉ ra rằng trung bình mẫu hội tụ theo xác suất về trung bình thực nếu dữ liệu độc lập và phân phối đồng nhất, đồng thời trung bình và phương sai là hữu hạn.
Tính chuẩn tiệm cận
Mặc dù việc phân phối của một bộ ước lượng nhất quán hội tụ sát về giá trị thực là một tin tốt, nhưng thách thức nằm ở chỗ phân phối của bộ ước lượng thay đổi tùy theo cỡ mẫu.
Nếu chúng ta biết chính xác phân phối của bộ ước lượng ở mọi cỡ mẫu, chúng ta có thể sử dụng nó để thực hiện suy diễn thống kê bằng phân phối mẫu hữu hạn, hay còn gọi là phân phối chính xác. Tuy nhiên, trong nghiên cứu ứng dụng, phân phối mẫu hữu hạn của hầu hết các bộ ước lượng đều không được biết đến. Thật may mắn, phân phối của một phiên bản đã được định tâm và thu phóng lại của các bộ ước lượng này sẽ tiến gần tới phân phối chuẩn khi cỡ mẫu tăng lên. Những bộ ước lượng có tính chất này được gọi là chuẩn tiệm cận. Chúng ta dùng phân phối mẫu lớn này để xấp xỉ phân phối mẫu hữu hạn.
Thay vì nhìn vào phân phối của bộ ước lượng theta cho cỡ mẫu N, chúng ta sẽ xem xét phân phối của biểu thức căn bậc hai của N nhân với hiệu số giữa ước lượng và giá trị thực tế. Dưới đây là cách chúng ta tạo ra các bộ ước lượng được định tâm và thu phóng lại trong Stata.
1generate double m1000n = sqrt(1000)*(m1000 - 1)
2generate double m100000n = sqrt(100000)*(m100000 - 1)
3kdensity m1000n, n(500) generate(x_1000n f_1000n) kernel(gaussian) nograph
4label variable f_1000n "N=1000"
5kdensity m100000n, n(500) generate(x_100000n f_100000n) kernel(gaussian) nograph
6label variable f_100000n "N=100000"
7graph twoway (line f_1000n x_1000n) (line f_100000n x_100000n)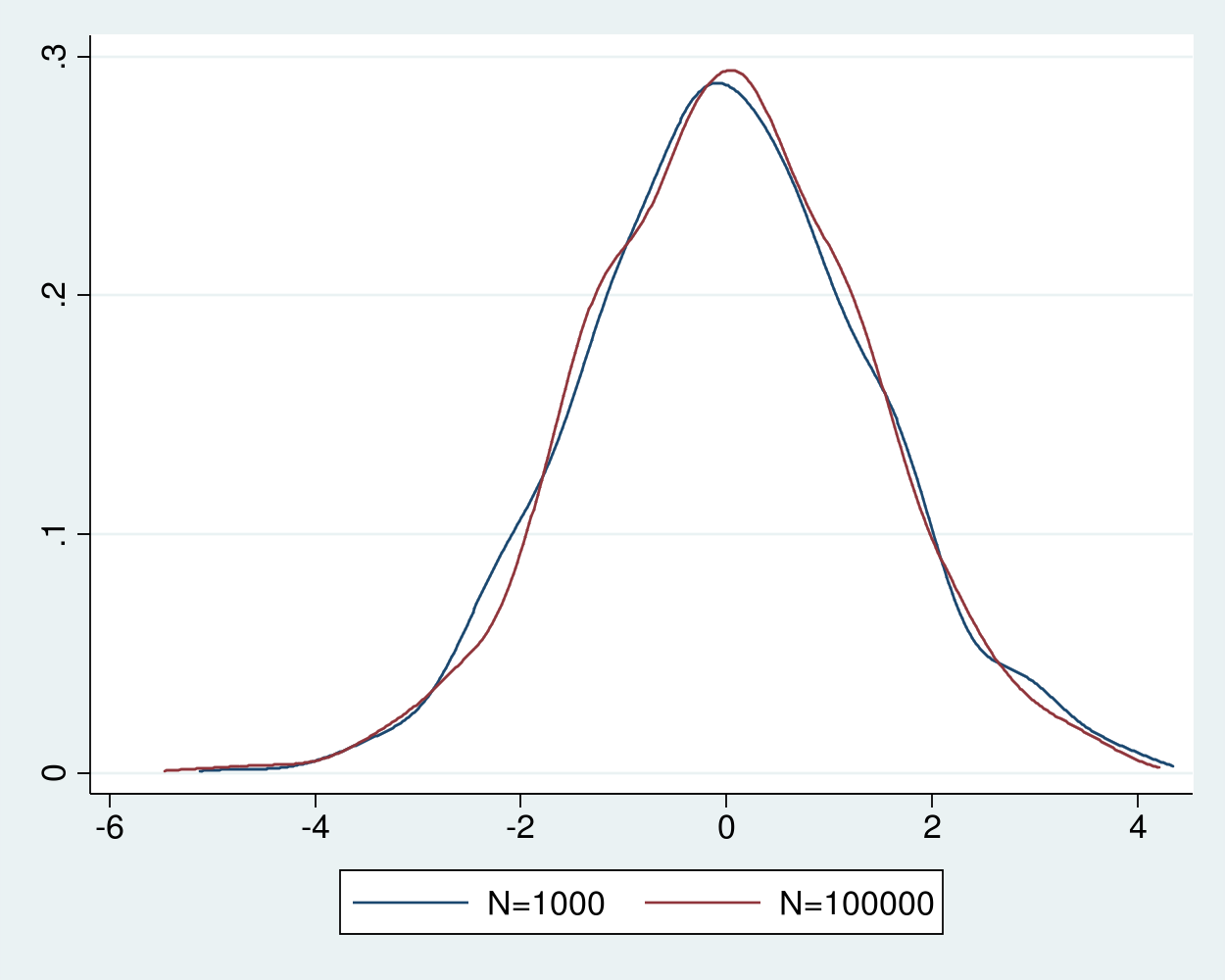
Đường cong mật độ của các bộ ước lượng định tâm và thu phóng trong biểu đồ gần như không thể phân biệt được với nhau và trông rất giống một phân phối chuẩn. Định lý giới hạn trung tâm Lindberg-Levy đảm bảo rằng khi cỡ mẫu tăng lên, phân phối của trung bình mẫu định tâm và thu phóng từ các biến ngẫu nhiên sẽ tiến sát về một phân phối chuẩn với trung bình bằng không và phương sai bằng phương sai của biến gốc.
Do phương sai của phân phối chi bình phương với một bậc tự do bằng hai, chúng ta có thể thêm một đường phân phối chuẩn với trung bình bằng không và phương sai bằng hai vào biểu đồ để đối chiếu.
1twoway (line f_1000n x_1000n) (line f_100000n x_100000n) (function normalden(x, sqrt(2)), range(-4 4)), legend( label(3 "Normal(0, 2)") cols(3))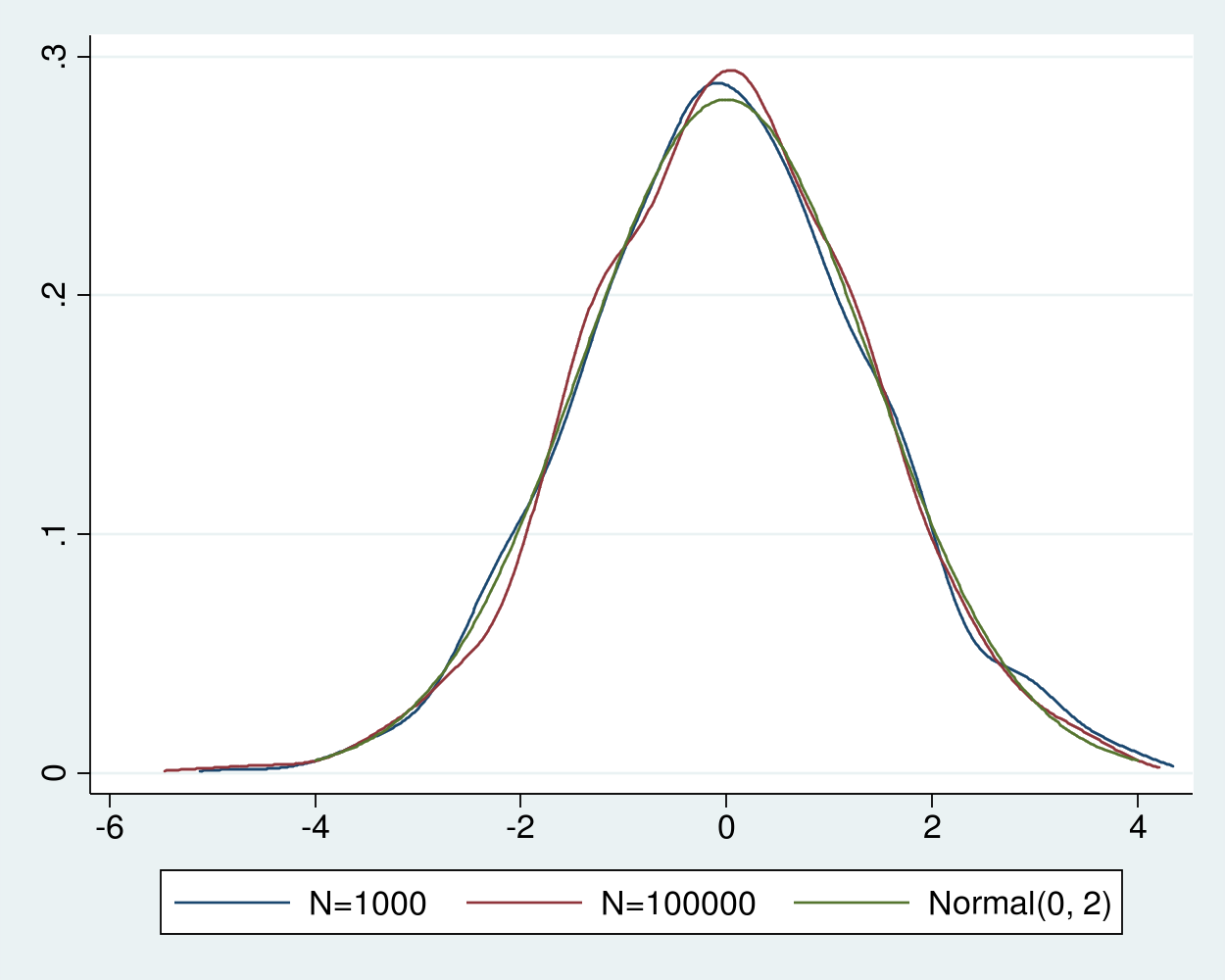
Đúng như lý thuyết dự đoán, mật độ của các bộ ước lượng định tâm và thu phóng lại hoàn toàn trùng khớp với mật độ của phân phối chuẩn có trung bình không và phương sai hai. Nhiều bộ ước lượng hợp lý cực đại hay bộ ước lượng phương pháp moment cũng có tính nhất quán và chuẩn tiệm cận dựa trên các giả định cụ thể về quá trình tạo ra dữ liệu.
✨ Bài viết đã trực quan hóa thành công hai định lý nền tảng nhất của kinh tế lượng và thống kê học. Việc thấu hiểu tính nhất quán giúp ta an tâm rằng dữ liệu đủ lớn sẽ dẫn lối đến sự thật, trong khi tính chuẩn tiệm cận cung cấp công cụ toán học vững chắc để thực hiện các kiểm định giả thuyết ngay cả khi ta không biết rõ hình dáng của thế giới thực.
Dựa trên những gì đã quan sát về việc nhân biểu thức với căn bậc hai của N, theo bạn, nếu chúng ta không thực hiện bước định tâm và thu phóng này mà chỉ đơn thuần vẽ phân phối của sai số ước lượng khi cỡ mẫu tăng dần lên một triệu hay mười triệu quan sát, đồ thị thu được sẽ có hình dáng như thế nào?

