Trong mô hình tự hồi quy một biến, một chuỗi thời gian dừng thường được mô hình hóa bằng cách phụ thuộc vào các giá trị trễ của chính nó. Khi phân tích nhiều chuỗi thời gian cùng lúc, bước phát triển tự nhiên tiếp theo là sử dụng mô hình vector tự hồi quy, hay còn gọi là mô hình VAR. Trong cấu trúc này, một hệ thống các biến số được giải thích bởi độ trễ của chính chúng và độ trễ của tất cả các biến số khác tồn tại trong hệ thống. Các nhà kinh tế vĩ mô ứng dụng thường sử dụng dạng mô hình này để mô tả dữ liệu thực tế, thực hiện suy luận nhân quả và đưa ra các tư vấn chính sách nền tảng.
Bài viết này sẽ minh họa cách ước lượng mô hình VAR ba biến số bao gồm tỷ lệ thất nghiệp, tỷ lệ lạm phát và lãi suất danh nghĩa tại Mỹ. Đây là bộ khung cơ bản được ứng dụng rộng rãi trong các phân tích về chính sách tiền tệ.
Dữ liệu và phương pháp lựa chọn độ trễ
Khi xây dựng một mô hình VAR, người nghiên cứu cần đưa ra hai quyết định cốt lõi. Thứ nhất, quyết định những biến số nào sẽ được đưa vào mô hình dựa trên câu hỏi nghiên cứu và nền tảng lý thuyết. Thứ hai, lựa chọn độ trễ sao cho phù hợp nhất. Bạn có thể dùng quy tắc kinh nghiệm như bao gồm toàn bộ dữ liệu của một năm, hoặc sử dụng các tiêu chuẩn lựa chọn độ trễ mang tính định lượng chính xác hơn.
Dữ liệu được sử dụng bao gồm các quan sát theo quý về tỷ lệ thất nghiệp, lạm phát giá tiêu dùng và lãi suất danh nghĩa ngắn hạn của Mỹ từ năm 1955 đến năm 2005. Trong các trích xuất Stata bên dưới, lạm phát có tên biến là inflation, tỷ lệ thất nghiệp là unrate và lãi suất quỹ liên bang là ffr. Hệ phương trình được thiết lập sao cho mỗi biến số tại thời điểm hiện tại là kết quả tổng hòa từ các giá trị trễ của cả ba biến, đi kèm với ma trận hệ số và phần tử sai số.
Bước đầu tiên trong quá trình tính toán là xác định độ trễ hợp lý thông qua lệnh varsoc để chạy các chẩn đoán chuyên sâu.
1. varsoc inflation unrate ffr, maxlag(8)
2 Selection-order criteria
3 Sample: 41 - 236 Number of obs = 196
4 +---------------------------------------------------------------------------+
5 |lag | LL LR df p FPE AIC HQIC SBIC |
6 |----+----------------------------------------------------------------------|
7 | 0 | -1242.78 66.5778 12.712 12.7323 12.7622 |
8 | 1 | -433.701 1618.2 9 0.000 .018956 4.54796 4.62922 4.74867 |
9 | 2 | -366.662 134.08 9 0.000 .010485 3.95574 4.09793 4.30696* |
10 | 3 | -351.034 31.257 9 0.000 .009801 3.8881 4.09123 4.38985 |
11 | 4 | -337.734 26.6 9 0.002 .009383 3.84422 4.1083 4.4965 |
12 | 5 | -319.353 36.763 9 0.000 .008531 3.7485 4.07351 4.5513 |
13 | 6 | -296.967 44.77* 9 0.000 .007447* 3.61191* 3.99787* 4.56524 |
14 | 7 | -292.066 9.8034 9 0.367 .007773 3.65373 4.10063 4.75759 |
15 | 8 | -286.45 11.232 9 0.260 .008057 3.68826 4.1961 4.94265 |
16 +---------------------------------------------------------------------------+
17 Endogenous: inflation unrate ffr
18 Exogenous: _consKết quả hiển thị cho thấy cả kiểm định tỷ số hợp lý lẫn tiêu chuẩn thông tin Akaike đều gợi ý mức độ trễ tối ưu là sáu. Với độ trễ đã được xác định, lệnh var sẽ thực hiện ước lượng các ma trận hệ số bằng phương pháp bình phương tối thiểu cho từng phương trình riêng biệt và ước tính ma trận hiệp phương sai của phần dư.
1. var inflation unrate ffr, lags(1/6) dfk small
2Vector autoregression
3Sample: 39 - 236 Number of obs = 198
4Log likelihood = -298.8751 AIC = 3.594698
5FPE = .0073199 HQIC = 3.97786
6Det(Sigma_ml) = .0041085 SBIC = 4.541321
7Equation Parms RMSE R-sq F P > F
8----------------------------------------------------------------
9inflation 19 .430015 0.9773 427.7745 0.0000
10unrate 19 .252309 0.9719 343.796 0.0000
11ffr 19 .795236 0.9481 181.8093 0.0000
12----------------------------------------------------------------Vì mô hình VAR ba biến số với sáu độ trễ sẽ tạo ra một bảng kết quả khổng lồ với gần sáu mươi hệ số, việc đọc từng p-value riêng lẻ không mang lại nhiều góc nhìn tổng thể. Do đó, các bài báo phân tích thực nghiệm hiếm khi in toàn bộ bảng hệ số này ra. Thay vào đó, toàn bộ trọng tâm được chuyển hướng sang các thống kê sau ước lượng. Hai phần tiếp theo sẽ khám phá kỹ thuật kiểm định nhân quả và khảo sát biến động nền kinh tế.
Đánh giá mô hình bằng kiểm định nhân quả Granger
Một biến số được ghi nhận là nguyên nhân Granger của một biến số khác nếu, trong điều kiện đã kiểm soát toàn bộ độ trễ của biến phụ thuộc, các độ trễ của biến độc lập cùng nhau đóng góp mức độ ý nghĩa thống kê vào phương trình đó. Lệnh vargranger tự động thực hiện một chuỗi các thao tác kiểm định giả thuyết này.
1. quietly var inflation unrate ffr, lags(1/6) dfk small
2. vargranger
3 Granger causality Wald tests
4 +------------------------------------------------------------------------+
5 | Equation Excluded | F df df_r Prob > F |
6 |--------------------------------------+---------------------------------|
7 | inflation unrate | 3.5594 6 179 0.0024 |
8 | inflation ffr | 1.6612 6 179 0.1330 |
9 | inflation ALL | 4.6433 12 179 0.0000 |
10 |--------------------------------------+---------------------------------|
11 | unrate inflation | 2.0466 6 179 0.0618 |
12 | unrate ffr | 1.2751 6 179 0.2709 |
13 | unrate ALL | 3.3316 12 179 0.0002 |
14 |--------------------------------------+---------------------------------|
15 | ffr inflation | 3.6745 6 179 0.0018 |
16 | ffr unrate | 7.7692 6 179 0.0000 |
17 | ffr ALL | 5.1996 12 179 0.0000 |
18 +------------------------------------------------------------------------+Hãy xem xét kết quả dành cho phương trình tỷ lệ thất nghiệp ở khối bảng thứ hai. Dòng ffr excluded tiến hành kiểm tra giả thuyết không rằng tất cả các hệ số trễ của lãi suất trong phương trình thất nghiệp đều bằng không. Với p-value bằng không phẩy hai bảy, chúng ta không có đủ cơ sở để bác bỏ giả thuyết này. Điều này kết luận rằng lãi suất không đóng vai trò nguyên nhân Granger đối với thất nghiệp. Tuy nhiên ở chiều ngược lại, nhìn vào phương trình lãi suất, cả lạm phát và thất nghiệp đều đóng vai trò là nguyên nhân Granger định hình biểu đồ lãi suất trong tương lai.
Bạn hoàn toàn có thể tự mình tái tạo lại kết quả này một cách thủ công thông qua phương pháp hồi quy tuyến tính bình thường và câu lệnh test đa biến.
1. quietly regress unrate l(1/6).unrate l(1/6).ffr l(1/6).inflation
2. test l1.ffr=l2.ffr=l3.ffr=l4.ffr=l5.ffr=l6.ffr=0
3 ( 1) L.ffr - L2.ffr = 0
4 ( 2) L.ffr - L3.ffr = 0
5 ( 3) L.ffr - L4.ffr = 0
6 ( 4) L.ffr - L5.ffr = 0
7 ( 5) L.ffr - L6.ffr = 0
8 ( 6) L.ffr = 0
9 F( 6, 179) = 1.28
10 Prob > F = 0.2709Phân tích hàm phản ứng đẩy trực giao
Nhóm chỉ số thứ hai được dùng để khai thác triệt để sức mạnh của VAR là theo dõi hàm phản ứng đẩy. Cơ chế hoạt động bao gồm việc tạo ra một cú sốc vào hệ thống, sau đó quan sát cách các biến nội sinh lan truyền chấn động đó qua thời gian. Khó khăn lớn nhất nằm ở chỗ các chuỗi sai số thường có tương quan chéo với nhau, việc nói về một cú sốc lạm phát thuần túy sẽ trở nên mâu thuẫn nếu không xử lý được sự tương quan này.
Cách tiếp cận chuẩn xác nhất là giả định hệ thống tồn tại những cú sốc cấu trúc nền tảng không có sự tương quan. Dựa vào kỹ thuật toán học mang tên phân rã Cholesky tác động lên ma trận hiệp phương sai của phần dư, dữ liệu sẽ được chuyển đổi thành cấu trúc dạng tam giác dưới. Việc này đòi hỏi chúng ta phải áp đặt một thứ tự cụ thể cho các biến số. Trật tự này mang thông điệp kinh tế học cực kỳ rõ rệt: cú sốc từ biến đứng trước sẽ tác động tức thì đến các biến đứng sau, nhưng biến đứng sau thì không có quyền thay đổi biến đứng trước ngay trong cùng một khoảng thời gian gốc.
Trong ví dụ này, trình tự được áp dụng lần lượt là lạm phát, tỷ lệ thất nghiệp và lãi suất. Sau khi định nghĩa luồng dữ liệu, thao tác tạo đồ thị hàm phản ứng đẩy trực giao được thực hiện trơn tru bằng cú pháp irf create và irf graph.
1. irf create var1, step(20) set(myirf) replace
2(file myirf.irf now active)
3(file myirf.irf updated)
4. irf graph oirf, impulse(inflation unrate ffr) response(inflation unrate ffr) yline(0,lcolor(black)) xlabel(0(4)20) byopts(yrescale)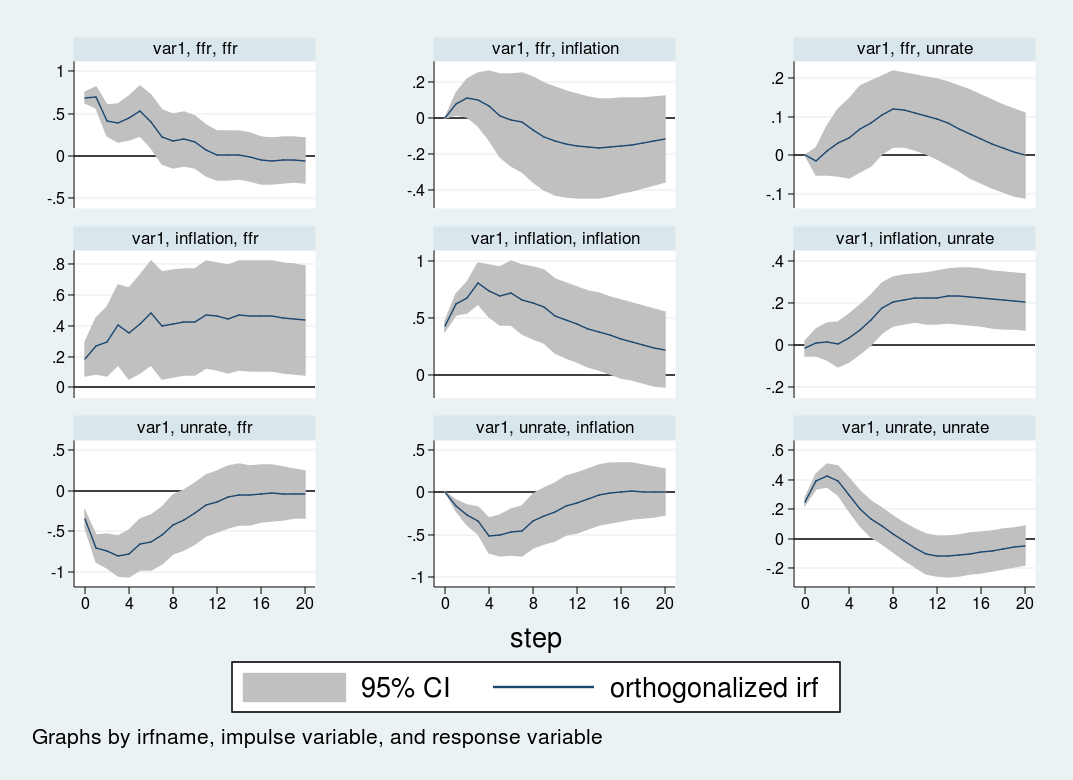
Bố cục của hàm phản ứng đẩy sắp xếp các cú sốc theo hàng và biến số tiếp nhận phản hồi theo cột. Trục hoành biểu thị đơn vị thời gian theo quý kéo dài đến hai mươi chu kỳ tương đương năm năm, trong khi trục tung đo lường độ lệch theo điểm phần trăm.
Nhìn vào hàng trên cùng, cú sốc dương từ lãi suất tạo ra một trạng thái dai dẳng kéo dài đến ba năm trước khi trở về điểm cân bằng ban đầu. Lạm phát có xu hướng giảm sau khoảng tám quý nhưng không đạt mức ý nghĩa thống kê rõ rệt. Tỷ lệ thất nghiệp phản ứng chậm chạp và chạm mức cao nhất là tăng không phẩy hai điểm phần trăm trước khi trượt dốc.
Hàng thứ hai diễn tả sự kiện lạm phát bùng nổ. Sự gia tăng ngoài dự kiến này đi kèm với sự leo thang bền vững của cả thất nghiệp và lãi suất. Đáng chú ý là hai biến số này vẫn duy trì ở mức cao kể cả khi vòng đời năm năm của cú sốc đã kết thúc.
Cuối cùng ở hàng thứ ba, diễn biến thị trường lao động xấu đi khi thất nghiệp bất ngờ tăng sẽ làm lạm phát giảm xuống khoảng nửa điểm phần trăm trong vòng một năm tiếp theo. Lãi suất ngay lập tức lao dốc mạnh gần một điểm phần trăm, phản ánh sự can thiệp điều tiết hòng cứu vãn cục diện nền kinh tế.
✨ Giá trị đắt giá: Bản chất của sự diễn dịch cấu trúc trong hàm phản ứng đẩy trực giao phụ thuộc vô cùng lớn vào giả định thứ tự biến số khi thực hiện phân rã Cholesky. Những lựa chọn trình tự khác nhau sẽ sinh ra những kết luận chính sách hoàn toàn khác nhau.
Nếu bạn thử đưa biến số tỷ lệ thất nghiệp lên đứng ở vị trí đầu tiên trong chuỗi phân rã hệ thống, bạn dự đoán đường cong lạm phát và lãi suất sẽ biến đổi theo chiều hướng nào trong những quý đầu tiên xảy ra cú sốc?

