Mô phỏng dược động học và dược lực học luôn là một lĩnh vực đầy thách thức đối với những người làm khoa học dữ liệu trong mảng y sinh. Thay vì chỉ đọc các tài liệu nghiên cứu với những con số mô hình hóa phức tạp, việc trực tiếp viết mã lệnh để thực hiện phân tích Monte Carlo mang lại một góc nhìn trực quan và sâu sắc hơn rất nhiều. Quá trình tính toán xác suất đạt mục tiêu của các nồng độ ức chế tối thiểu khác nhau không chỉ giúp củng cố lý thuyết mà còn mở ra những câu hỏi thú vị về cách thuốc phân bố trong cơ thể. Bài viết này sẽ trình bày cách xây dựng một mô hình cơ bản với gói mrgsolve trong R để mô phỏng nồng độ thuốc ceftriaxone, đồng thời đánh giá tác động của các biến số lâm sàng như độ thanh thải creatinine và tình trạng giảm albumin máu.
Dược động học quần thể và các tham số quan trọng
Dược động học quần thể là một phương pháp thống kê mô tả cách các loại thuốc hoạt động trong cơ thể qua các nhóm người khác nhau, có tính đến sự biến thiên giữa các cá thể. Thay vì nghiên cứu sâu một người, phương pháp này phân tích dữ liệu thưa thớt từ nhiều bệnh nhân để hiểu hành vi dùng thuốc điển hình và lý do tại sao mọi người lại khác nhau về mức độ phơi nhiễm thuốc.
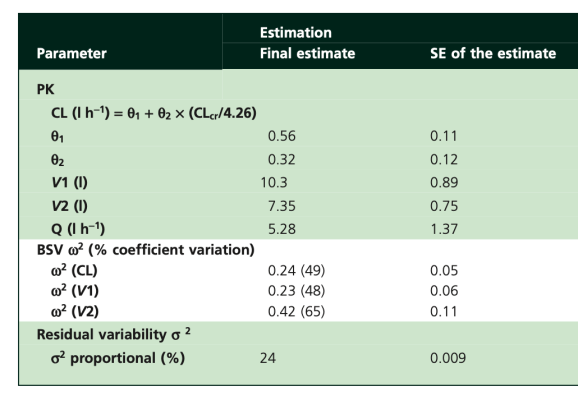
Khi phân tích một nghiên cứu dược động học quần thể, việc xác định đúng các tham số là bước nền tảng. Dựa trên mô hình đánh giá ceftriaxone ở bệnh nhân nhiễm trùng huyết nặng, chúng ta có thể tập trung vào các thông số sau:
Độ thanh thải được tính bằng tổng của theta 1 và tích của theta 2 với tỷ lệ giữa độ thanh thải creatinine và 4.26. Trong đó, theta 1 là thành phần thanh thải không qua thận ở mức cơ sở và theta 2 là hệ số thu phóng thanh thải qua thận. Các thông số phân bố bao gồm thể tích phân bố của khoang trung tâm V1 và thể tích phân bố của khoang ngoại vi V2. Sự chuyển hóa giữa hai khoang này được đại diện bởi thông số thanh thải liên khoang Q. Ngoài ra, mô hình còn bao gồm độ biến thiên giữa các cá thể đối với độ thanh thải, thể tích khoang trung tâm và thể tích khoang ngoại vi, thường được biểu diễn bằng các giá trị phương sai omega bình phương.

Đây là một mô hình hiệu ứng hỗn hợp, nơi các ước lượng được mô hình hóa như một hàm của hiệu ứng cố định theta và hiệu ứng ngẫu nhiên eta. Hiệu ứng cố định đại diện cho giá trị điển hình của tham số trong quần thể, trong khi hiệu ứng ngẫu nhiên đại diện cho sự biến thiên giữa các cá thể. Hiệu ứng ngẫu nhiên được giả định là có phân phối chuẩn với trung bình bằng không và phương sai là omega bình phương. Quá trình bắt đầu với việc thuốc được dùng vào khoang trung tâm, sau đó đi vào khoang ngoại vi hoặc được thải trừ. Luồng di chuyển giữa khoang trung tâm và ngoại vi là hai chiều, trong khi các hướng khác chỉ là đi vào khoang trung tâm hoặc đi ra khỏi khoang trung tâm để thải trừ.
Xây dựng mô hình cơ bản bằng mã lệnh
Dưới đây là cách triển khai mô hình dược động học hai khoang bằng mrgsolve trong R. Các khối tham số được khai báo dựa trên dữ liệu chuẩn, kết hợp với các phương trình vi phân thường để mô tả sự thay đổi nồng độ thuốc theo thời gian.
1library(mrgsolve)
2library(tidyverse)
3mod <- mcode(model = "ceftriaxone", code='
4$PARAM
5theta1 = 0.56,
6theta2 = 0.32,
7CLcr = 4.26, // median creatinine clearance of 68.5 ml min-1, hence ~4.26 L hr-1
8V1 = 10.3,
9V2 = 7.35,
10Q = 5.28,
11fu = 0.10 // fraction of unbound, picked a static value from package insert range
12$CMT CENT PERI
13$MAIN
14double CL = theta1 + theta2 * (CLcr / 4.26);
15double CLi = CL * exp(ETA(1));
16double V1i = V1 * exp(ETA(2));
17double V2i = V2 * exp(ETA(3));
18$OMEGA
190.24
200.23
210.42
22$SIGMA
230.0576
24$ODE
25dxdt_CENT = -(CLi/V1i)*CENT - (Q/V1i)*CENT + (Q/V2i)*PERI;
26dxdt_PERI = (Q/V1i)*CENT - (Q/V2i)*PERI;
27$TABLE
28double Cp_total = (CENT / V1i)*(1+EPS(1));
29double Cp_free = fu * Cp_total;
30$CAPTURE Cp_free
31')
32dosing <- ev(amt = 2000, rate = 4000, ii = 24, addl = 2, cmt = "CENT")
33set.seed(1)
34sims <- mod |>
35 ev(dosing) |>
36 mrgsim(nid = 1000, end = 72, delta = 0.25) |>
37 as_tibble()Trong đoạn mã trên, biến ETA đại diện cho hiệu ứng ngẫu nhiên và biến EPS đại diện cho sai số mô hình. Hàm ev thiết lập phác đồ liều lượng với lượng thuốc là 2000 mg ceftriaxone, truyền trong 30 phút mỗi 24 giờ cho tổng cộng 3 liều vào khoang trung tâm. Hàm mrgsim sẽ thực hiện mô phỏng cho 1000 cá thể trong 72 giờ với khoảng thời gian chia nhỏ là 0.25 giờ.
Bước tiếp theo là tính toán xác suất đạt mục tiêu cho mức nồng độ ức chế tối thiểu. Tại mức giá trị bằng 1, dữ liệu sau 48 giờ được lọc ra để đảm bảo trạng thái ổn định, từ đó tính trung bình lượng ceftriaxone tự do vượt ngưỡng yêu cầu trong hơn 50% thời gian.
1MIC <- 1
2print(paste0("Probability of Target Attainment: ", sims |>
3 filter(time >= 48) |>
4 group_by(ID) |>
5 summarise(fT = mean(Cp_free > MIC)) |>
6 summarise(PTA = mean(fT >= 0.50)) |>
7 pull()))
8sims |>
9 ggplot(aes(x=time,y=Cp_free,group=ID)) +
10 geom_line(alpha=0.01) +
11 geom_hline(yintercept = MIC, color = "red") +
12 theme_bw()Tác động của sự thay đổi độ thanh thải creatinine
Khi kiểm tra khả năng đáp ứng của mô hình dưới các mức độ thanh thải creatinine khác nhau, chúng ta có thể chạy một vòng lặp để cập nhật giá trị đầu vào và lưu lại kết quả mô phỏng tương ứng.
1library(glue)
2crcl_vec <- c(1.8,7.2,10.8)
3crcl_vec_i <- c(30, 120, 180)
4for (crcl in crcl_vec) {
5mod <- mcode(model = "ceftriaxone", code=glue('
6$PARAM
7theta1 = 0.56,
8theta2 = 0.32,
9CLcr = {crcl},
10V1 = 10.3,
11V2 = 7.35,
12Q = 5.28,
13fu = 0.10
14$CMT CENT PERI
15$MAIN
16double CL = theta1 + theta2 * (CLcr / 4.26);
17double CLi = CL * exp(ETA(1));
18double V1i = V1 * exp(ETA(2));
19double V2i = V2 * exp(ETA(3));
20$OMEGA
210.24
220.23
230.42
24$SIGMA
250.0576
26$ODE
27dxdt_CENT = -(CLi/V1i)*CENT - (Q/V1i)*CENT + (Q/V2i)*PERI;
28dxdt_PERI = (Q/V1i)*CENT - (Q/V2i)*PERI;
29$TABLE
30double Cp_total = (CENT / V1i)*(1+EPS(1));
31double Cp_free = fu * Cp_total;
32$CAPTURE Cp_free
33',crcl))
34dosing <- ev(amt = 2000, rate = 4000, ii = 24, addl = 2, cmt = "CENT")
35set.seed(1)
36sims <- mod |>
37 ev(dosing) |>
38 mrgsim(nid = 1000, end = 72, delta = 0.25) |>
39 as_tibble()
40MIC <- 1
41pta <- paste0("Probability of Target Attainment: ", sims |>
42 filter(time >= 48) |>
43 group_by(ID) |>
44 summarise(fT = mean(Cp_free > MIC)) |>
45 summarise(PTA = mean(fT >= 0.50)) |>
46 pull(), " ,CrCl: ", crcl_vec_i[crcl_vec==crcl], "ml/min")
47plot <- sims |>
48 ggplot(aes(x=time,y=Cp_free,group=ID)) +
49 geom_line(alpha=0.01) +
50 geom_hline(yintercept = MIC, color = "red") +
51 theme_bw() +
52 ggtitle(pta)
53plot(plot)
54}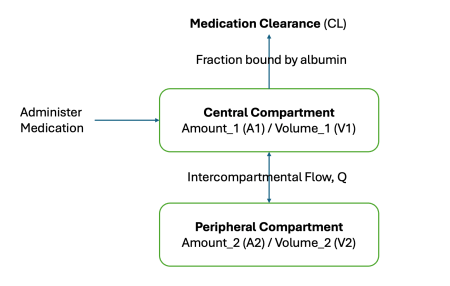
Sự gia tăng độ thanh thải creatinine sẽ làm tăng tốc độ đào thải ceftriaxone, do đó làm giảm xác suất đạt mục tiêu. Tuy nhiên, mức độ chấp nhận được đối với chỉ số này trong các tình huống lâm sàng khác nhau vẫn là một yếu tố cần được đánh giá dựa trên từng phác đồ cụ thể.
Hiệu chỉnh mô hình với tình trạng giảm albumin máu
Mô hình ban đầu sử dụng một tỷ lệ thuốc không gắn kết cố định. Tuy nhiên ở những bệnh nhân nặng, tình trạng giảm albumin máu rất phổ biến và có thể dẫn đến sự gia tăng tỷ lệ thuốc tự do, ảnh hưởng trực tiếp đến cấu hình dược động lực học. Để đưa yếu tố này vào mã lệnh mrgsolve, hàm tính toán thuốc tự do cần được định nghĩa lại trong khối toàn cục dựa trên nồng độ tổng số vị trí liên kết protein.
1mod <- mcode(model = "ceftriaxone", code='
2$PARAM
3theta1 = 0.56,
4theta2 = 0.32,
5CLcr = 4.26,
6V1 = 10.3,
7V2 = 7.35,
8Q = 5.28,
9np = 517,
10kaff = 0.0367
11$OMEGA
120.24
130.23
140.42
15$SIGMA
160.0576
17$CMT CENT PERI
18$GLOBAL
19double solveFree(double CTOT, double np, double kaff) {
20 double cf = (-(np+1/kaff-CTOT)+sqrt(pow(np+1/kaff-CTOT,2.0)+(4.0*CTOT/kaff)));
21 return cf > 0 ? cf : 0;
22}
23$MAIN
24double CL = theta1 + theta2 * (CLcr / 4.26);
25double CLi = CL * exp(ETA(1));
26double V1i = V1 * exp(ETA(2));
27double V2i = V2 * exp(ETA(3));
28$ODE
29double CTOT = CENT / V1i;
30double CFREE = solveFree(CTOT, np, kaff);
31dxdt_CENT = -CLi * CFREE
32 - (Q / V1i) * CENT
33 + (Q / V2i) * PERI;
34dxdt_PERI = (Q / V1i) * CENT
35 - (Q / V2i) * PERI;
36$TABLE
37double CTOTAL = CENT / V1i;
38double Cp_free = solveFree(CTOTAL, np, kaff);
39double Cp_bound = CTOTAL - Cp_free;
40double FU = Cp_free / (CTOTAL + 1e-9);
41double Cp_obs = CTOTAL * (1 + EPS(1));
42$CAPTURE CTOTAL Cp_free Cp_bound FU Cp_obs
43')
44dosing <- ev(amt = 2000, rate = 4000, ii = 24, addl = 2, cmt = "CENT")
45set.seed(1)
46sims <- mod |>
47 param(np = 295) |>
48 ev(dosing) |>
49 mrgsim(nid = 1000, end = 72, delta = 0.25) |>
50 as_tibble()
51MIC <- 1
52pta <- paste0("Probability of Target Attainment: ", sims |>
53 filter(time >= 48) |>
54 group_by(ID) |>
55 summarise(fT = mean(Cp_free > MIC)) |>
56 summarise(PTA = mean(fT >= 0.50)) |>
57 pull(),", Albumin: ~25g/L, CrCl: ~63 ml/min")
58plot <- sims |>
59 ggplot(aes(x=time,y=Cp_free,group=ID)) +
60 geom_line(alpha=0.01) +
61 geom_hline(yintercept = MIC, color = "red") +
62 theme_bw() +
63 ggtitle(pta)
64plot(plot)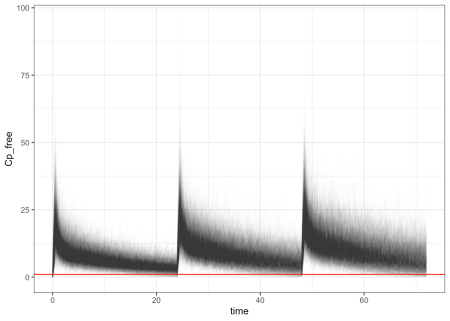
Khi phù hợp đúng phương trình ước tính ceftriaxone tự do, kết quả cho thấy xác suất đạt mục tiêu được cải thiện ngay cả khi nồng độ albumin thấp. Điều này cho thấy vai trò quan trọng của việc mô hình hóa chính xác sự gắn kết protein trong phân tích dữ liệu y sinh.
Thử nghiệm phác đồ liều mỗi 48 giờ
Khi đẩy các tham số đến kịch bản cực đoan như nồng độ albumin rất thấp, độ thanh thải creatinine rất cao và yêu cầu thời gian thuốc tự do vượt ngưỡng nồng độ ức chế tối thiểu lên hơn 70%, kết quả mô phỏng cho thấy nồng độ thuốc tự do vẫn duy trì ở mức khá cao. Điều này dẫn đến một thử nghiệm mở rộng: đánh giá phác đồ liều lượng giãn cách mỗi 48 giờ.
1dosing <- ev(amt = 2000, rate = 4000, ii = 48, addl = 2, cmt = "CENT")
2set.seed(1)
3sims <- mod |>
4 param(np = 172, CLcr = 10.8) |>
5 ev(dosing) |>
6 mrgsim(nid = 1000, end = 144, delta = 0.25) |>
7 as_tibble()
8MIC <- 1
9pta <- paste0("PTA: ", sims |>
10 filter(time >= 48) |>
11 group_by(ID) |>
12 summarise(fT = mean(Cp_free > MIC)) |>
13 summarise(PTA = mean(fT >= 0.70)) |>
14 pull(),", Albumin: ~15g/L, CrCl: ~180 ml/min, fT > mic >= 70%, q48h dosing")
15plot <- sims |>
16 ggplot(aes(x=time,y=Cp_free,group=ID)) +
17 geom_line(alpha=0.01) +
18 geom_hline(yintercept = MIC, color = "red") +
19 theme_bw() +
20 ggtitle(pta)
21plot(plot)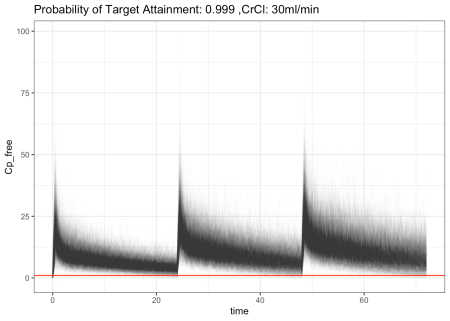
Kết quả mô phỏng cho thấy xác suất đạt mục tiêu vẫn duy trì ở mức vô cùng ấn tượng. Ngay cả khi nâng tiêu chuẩn đánh giá lên mức 99% thời gian duy trì nồng độ cao hơn mức ức chế tối thiểu, xác suất này vẫn đạt gần 0.98. Khám phá này mở ra nhiều khía cạnh đáng cân nhắc về việc thiết kế các thử nghiệm mô phỏng và cách so sánh chúng với các dữ liệu thực tế lâm sàng.
✨ Việc ứng dụng thư viện mrgsolve không chỉ giúp tự động hóa quá trình chạy phân tích Monte Carlo mà còn củng cố nền tảng kiến thức về dược động học quần thể, phương trình vi phân mô tả mô hình hai khoang và ý nghĩa thực tế của các thông số kỹ thuật.
Với kết quả mô phỏng cho thấy nồng độ ceftriaxone tự do vượt trội ngay cả trong kịch bản sử dụng liều giãn cách 48 giờ và thông số thanh thải cực đoan, theo bạn, liệu có yếu tố ẩn nào trong việc thiết lập giới hạn nồng độ ức chế tối thiểu đang làm sai lệch kết quả mô phỏng so với kỳ vọng sinh lý thông thường không?