
Trong trò chơi 20 câu hỏi, chiến thuật thông minh nhất mà chúng ta thường áp dụng là đặt ra những câu hỏi có khả năng chia đôi các lựa chọn còn lại. Cách tiếp cận này có sự tương đồng đáng kinh ngạc với thuật toán cây quyết định trong học máy, dù giữa chúng có một điểm khác biệt căn bản. Một cây quyết định thực tế thường có hành vi giống như đang gian lận. Trong khi người chơi phải tự tìm ra đáp án, thuật toán cây quyết định lại biết trước mục tiêu cuối cùng là gì. Nó cố gắng tìm ra những đặc trưng và giá trị phân tách tốt nhất để tách biệt đối tượng mục tiêu khỏi các dữ liệu còn lại tại mỗi node, nhưng nó cần biết câu trả lời đúng để đưa ra những câu hỏi tối ưu nhất. Đây chính là lý do tại sao khi chúng ta thay đổi đối tượng cần tìm, thuật toán có thể chọn các đặc trưng và điểm phân chia hoàn toàn khác nhau.
Xây dựng mô hình cây quyết định với dữ liệu Tổng thống Hoa Kỳ
Để thử nghiệm giả thuyết này, tôi đã sử dụng tập dữ liệu về các đời Tổng thống Hoa Kỳ. Một thách thức nhỏ khi xử lý dữ liệu này là một số biến số có quá nhiều giá trị riêng biệt, ví dụ như tên các đảng phái chính trị vào thế kỷ 18. Để mô hình hoạt động hiệu quả hơn, tôi đã tiến hành nhóm các giá trị này lại nhằm giảm bớt sự phức tạp. Ban đầu, tôi thử chọn ngẫu nhiên một vị Tổng thống, nhưng sau đó tôi quyết định chọn Ronald Reagan làm mục tiêu để tạo ra một cấu trúc cây thú vị và gần gũi hơn với cách đặt câu hỏi của con người. Nếu chọn President Garfield, chúng ta có thể có câu hỏi độc đáo về việc ông từng chứng minh định lý Pythagoras, nhưng điều đó có vẻ hơi quá chuyên sâu cho một mô hình tổng quát.
Dưới đây là cấu trúc cây quyết định được tạo ra để tìm ra mục tiêu Ronald Reagan:
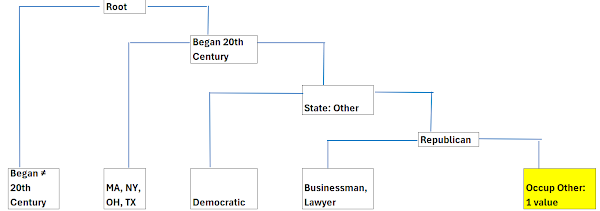
Triển khai mã nguồn trên ngôn ngữ R
Để xây dựng mô hình này, tôi sử dụng thư viện rpart để huấn luyện cây và rpart.plot để trực quan hóa kết quả. Dữ liệu đầu vào bao gồm các thông tin về đảng phái, tiểu bang, nghề nghiệp và thời gian nhậm chức của các Tổng thống.
1library(dplyr)
2library(rpart)
3library(rpart.plot)
4library(ggplot2)
5df <- read.csv("prez.csv", header=TRUE)
6set.seed(123)
7r <- 40
8answer <- df$LastName[r]
9print(paste("The target president is:", answer))
10df$target <- rep(0, nrow(df))
11df$target[r] <- 1
12df <- df %>%
13 mutate(
14 Party = case_when(
15 Party %in% c("Democratic") ~ "Democratic",
16 Party %in% c("Republican") ~ "Republican",
17 TRUE ~ "Other"),
18 Occupation = case_when(
19 Occupation %in% c("Businessman", "Lawyer") ~ Occupation,
20 TRUE ~ "Other"),
21 State = case_when(
22 State %in% c("New York") ~ "NY",
23 State %in% c("Ohio") ~ "OH",
24 State %in% c("Virginia") ~ "VA",
25 State %in% c("Massachusetts") ~ "MA",
26 State %in% c("Texas") ~ "TX", TRUE ~ "Other"),
27 Religion = case_when(
28 Religion %in% c("Episcopalian", "Presbyterian", "Unitarian", "Baptist", "Methodist") ~ "Main_Prot",
29 TRUE ~ "Other"),
30 DOB = cut(DOB, breaks = c(-Inf, 1800, 1900, 2000, Inf),
31 labels = c("18th century", "19th century", "20th century", "21st century"), right = FALSE),
32 DOD = cut(DOD, breaks = c(-Inf, 1800, 1900, 2000, Inf),
33 labels = c("18th century", "19th century", "20th century", "21st century"), right = FALSE),
34 Began = cut(Began, breaks = c(-Inf, 1800, 1900, 2000, Inf),
35 labels = c("18th century", "19th century", "20th century", "21st century"), right = FALSE),
36 Ended = cut(Ended, breaks = c(-Inf, 1800, 1900, 2000, Inf),
37 labels = c("18th century", "19th century", "20th century", "21st century"), right = FALSE)
38 ) %>%
39 mutate_at(vars(Party, State, Occupation, Religion, Assassinated, Military, Terms_GT_1, Pres_During_War, Was_Veep, DOB, DOD, Began, Ended), as.factor)
40formula <- as.formula(target ~ Began + State + Party + Occupation + Pres_During_War)
41prez_tree <- rpart(formula, data = df, method = "class",
42 control = rpart.control(cp = 0.001, minsplit = 2, minbucket = 1))
43rpart.plot(prez_tree, type = 4, extra = 101, main = "President Twenty Questions")Phân tích mức độ quan trọng của các biến
Sau khi xây dựng cây, chúng ta có thể đánh giá xem yếu tố nào đóng vai trò then chốt trong việc phân loại. Mức độ quan trọng của biến được tính toán dựa trên tổng mức độ cải thiện tại tất cả các node mà biến đó được sử dụng để phân tách dữ liệu. Điều thú vị là thứ tự các biến trong biểu đồ mức độ quan trọng không nhất thiết phải trùng khớp với thứ tự các lần phân tách trên cây quyết định.
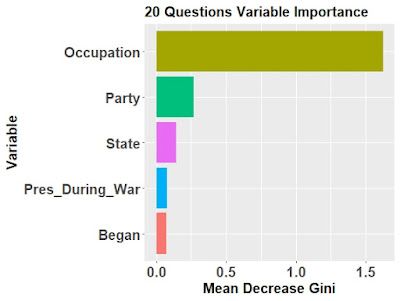
Trong mô hình này, thời điểm bắt đầu nhiệm kỳ và đảng phái thường là những câu hỏi mang tính quyết định nhất để thu hẹp phạm vi tìm kiếm một Tổng thống cụ thể.
Mở rộng thử nghiệm với tất cả các đời Tổng thống
Tôi cũng đã thực hiện một vòng lặp để kiểm tra xem với mỗi Tổng thống khác nhau, biến số nào sẽ được mô hình chọn để thực hiện lần phân tách đầu tiên. Kết quả cho thấy thuật toán cực kỳ linh hoạt trong việc thay đổi chiến lược hỏi tùy thuộc vào mục tiêu mà nó đã biết trước.
1library(purrr)
2get_first_split_row <- function(df, r) {
3 df$target <- 0
4 df$target[r] <- 1
5 tree <- rpart(formula, data = df, method = "class",
6 control = rpart.control(cp = 0.001, minsplit = 2, minbucket = 1))
7 frame <- tree$frame
8 if (nrow(frame) > 1) {
9 first_split_var <- as.character(frame$var[1])
10 } else {
11 first_split_var <- "No split"
12 }
13 return(data.frame(
14 President = df$LastName[r],
15 First_Split_Variable = first_split_var
16 ))
17}
18indices_to_run <- 1:nrow(df)
19first_split_results_df <- map_dfr(indices_to_run, ~ get_first_split_row(df, .x))
20print(table(first_split_results_df$First_Split_Variable))✨ Giá trị đắt giá: Cây quyết định không chỉ là một công cụ dự báo mạnh mẽ mà còn cung cấp khả năng diễn giải tuyệt vời, giúp chúng ta hiểu rõ lộ trình logic dẫn đến kết quả, tương tự như cách con người tư duy trong các trò chơi giải đố.
Câu hỏi tư duy: Nếu bạn thêm một biến số mới về chiều cao của các Tổng thống vào mô hình, liệu biến số này có khả năng trở thành câu hỏi đầu tiên trong cây quyết định hay không? Tại sao?

