Hồi quy phân vị cho phép tác động của các biến giải thích thay đổi tùy theo từng phân vị khác nhau của biến phụ thuộc. Các nhà nghiên cứu ứng dụng thường ưa chuộng mô hình này vì nó giúp làm rõ cách một biến số ảnh hưởng đến các nhóm đối tượng khác nhau trong quần thể. Chẳng hạn, thêm một năm đi học có thể có tác động rất lớn đến nhóm có mức thu nhập thấp nhưng lại mang lại hiệu quả ít hơn đối với nhóm có thu nhập cao. Tương tự, việc hút thêm một bao thuốc lá mỗi ngày có thể ảnh hưởng đến chức năng hô hấp của người có thể trạng yếu nghiêm trọng hơn nhiều so với người có thể trạng tốt.
Hiểu Về Phân Vị Điều Kiện Qua Dữ Liệu Mô Phỏng
Giả sử mỗi con số từ 0 đến 1 đại diện cho vị thế của một cá nhân trong quần thể, hay còn gọi là thứ hạng. Với một giá trị x cho trước, hàm phân vị điều kiện sẽ ánh xạ một thứ hạng tau nằm trong khoảng từ 0 đến 1 thành một kết quả y cụ thể. Quá trình này về bản chất là nghịch đảo của hàm phân phối điều kiện.
Để minh họa, chúng ta sử dụng dữ liệu mô phỏng từ phân phối Weibull. Biểu đồ dưới đây hiển thị sự phân tán của kết quả y theo biến x, bao gồm đường trung bình điều kiện, đường phân vị 0.8, trung vị và đường phân vị 0.2.
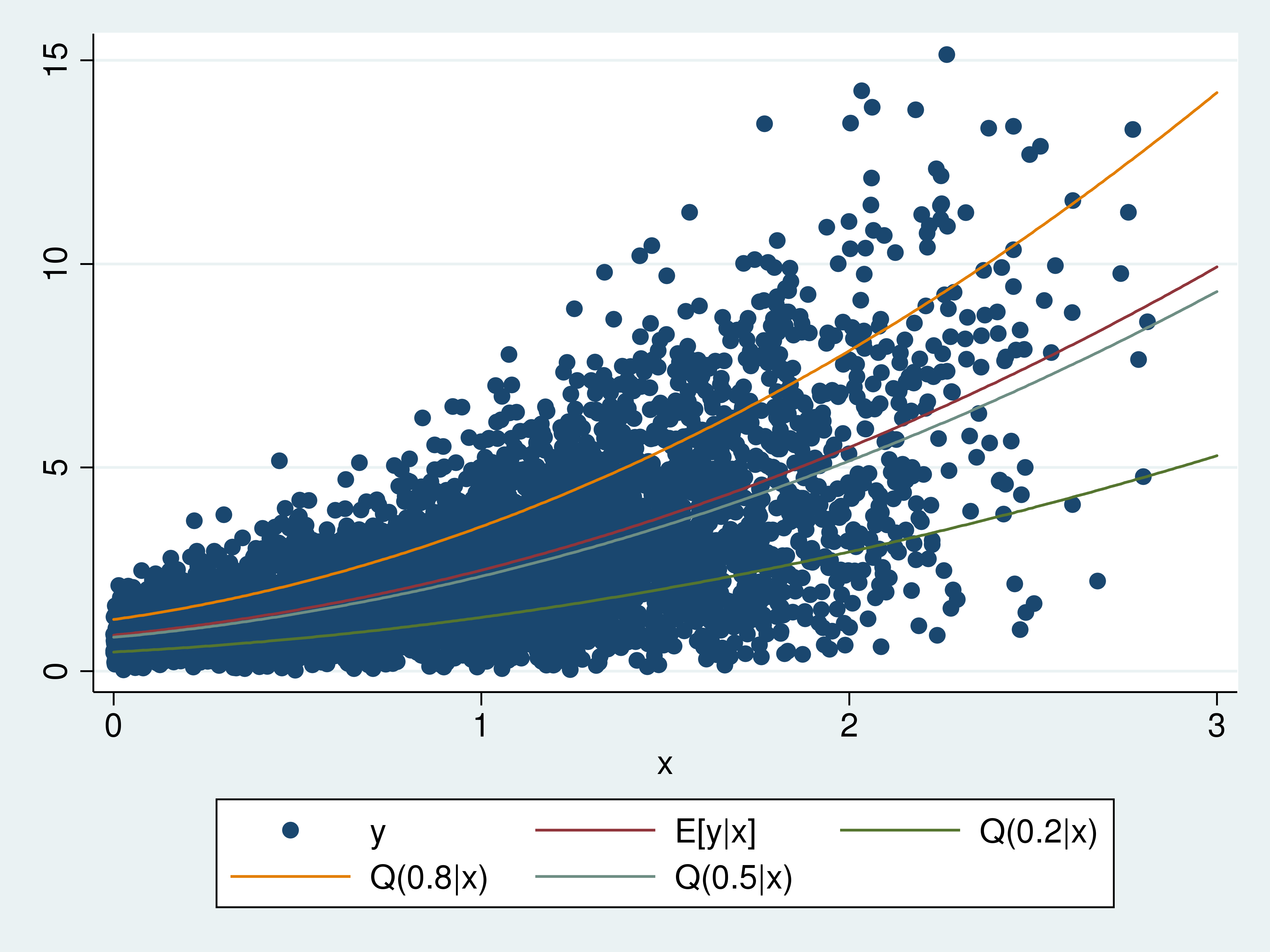
Đường phân vị 0.8 biểu diễn kết quả y tương ứng với thứ hạng 0.8 tại mỗi giá trị x. Tương tự, các đường 0.5 và 0.2 lần lượt đại diện cho các thứ hạng tương ứng. Thứ tự của các đường này luôn được duy trì vì giá trị phân vị cao hơn sẽ cho kết quả y lớn hơn. Trong ví dụ này, các đường cong có xu hướng hướng lên trên do chúng ta sử dụng hàm bậc hai của x trong quá trình mô phỏng. Đường trung bình nằm trên đường trung vị vì phân phối Weibull có phần đuôi bên phải dài và mỏng.
Về mặt kỹ thuật, hàm phân vị là nghịch đảo của hàm phân phối tích lũy. Nếu hàm phân phối ánh xạ giá trị y thành một vị trí xếp hạng, thì hàm phân vị sẽ thực hiện ngược lại: lấy một thứ hạng cho trước và trả về giá trị y tương ứng.
Ước Lượng Hàm Phân Vị Điều Kiện Với Lệnh Qreg
Lệnh qreg trong phần mềm Stata được sử dụng để ước lượng các tham số của hàm phân vị điều kiện. Tương tự như phương pháp bình phương tối thiểu thông thường, các hàm phân vị điều kiện được giả định là các tổ hợp tuyến tính của các biến giải thích. Các biến bậc cao hoặc tương tác có thể được xử lý dễ dàng thông qua các biến thừa số.
Trong ví dụ đầu tiên, chúng ta sẽ ước lượng các hệ số delta cho hàm phân vị điều kiện 0.2.
1use quantile1
2qreg y x c.x#c.x, quantile(0.2)Kết quả từ lệnh qreg được thực hiện bằng cách tối thiểu hóa tổng sai lệch tuyệt đối có trọng số bất đối xứng. Bảng kết quả dưới đây cung cấp các ước lượng điểm và suy diễn thống kê cho các hệ số trong mô hình.
Khi mô phỏng dữ liệu này, các giá trị thực tế của hệ số beta được thiết lập lần lượt là 1, 1 và 0.8 với tham số alpha bằng 2. Điều này dẫn đến các giá trị thực của delta lần lượt là 0.47, 0.47 và 0.38. Các hệ số ước lượng được từ mô hình rất sát với các giá trị thực tế này.
So Sánh Phân Vị Ước Lượng Và Hàm Thực Tế
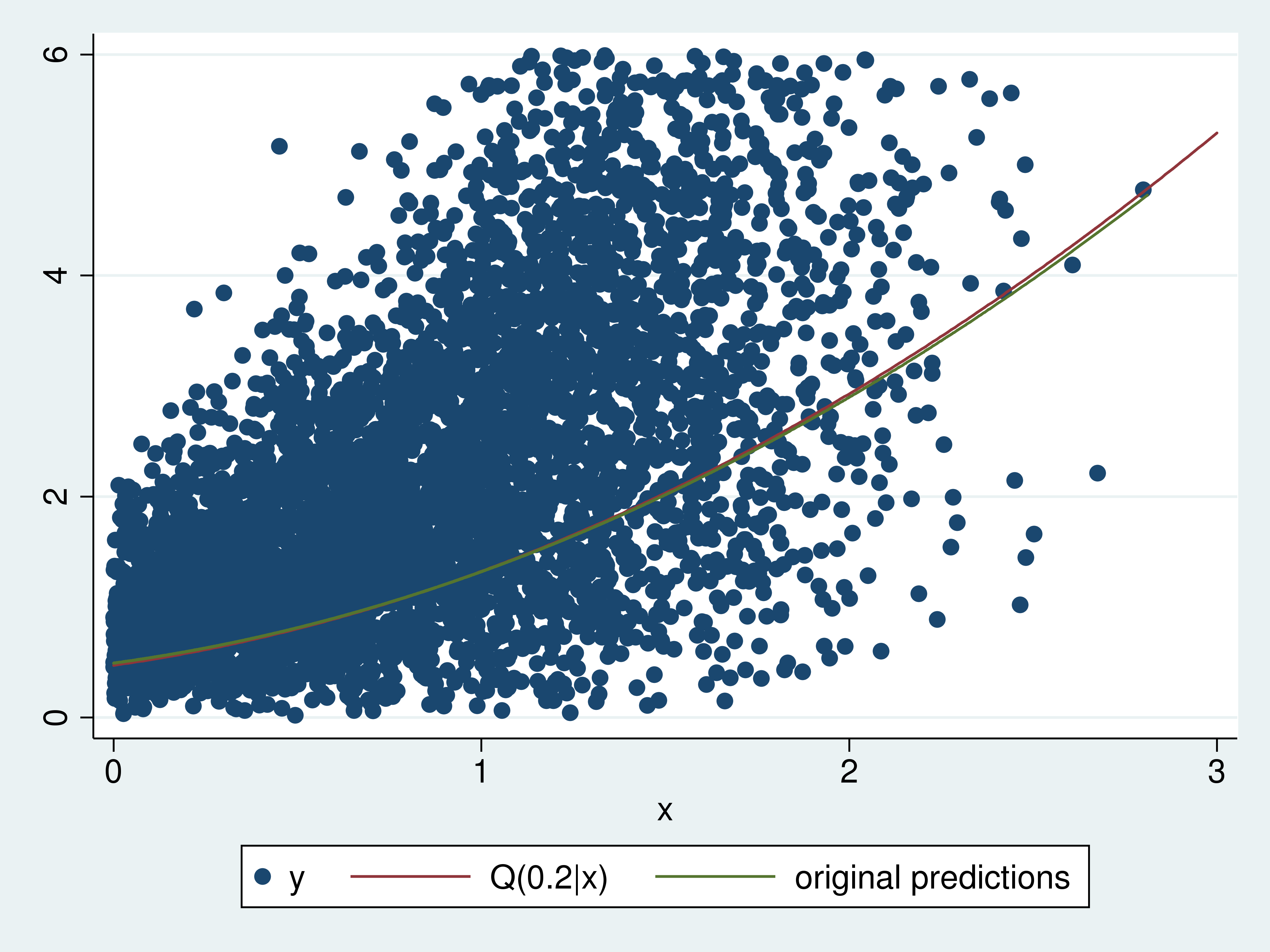
Một cách khác để kiểm chứng độ chính xác của hồi quy phân vị là so sánh hàm phân vị điều kiện 0.2 vừa ước lượng với hàm thực tế. Chúng ta sẽ tính toán giá trị dự báo và vẽ chúng trên cùng một biểu đồ.
1predict xb0
2label variable xb0 "original predictions"
3sort x
4twoway (scatter y x if y<6) (function q20 = (1+x+0.8*x^2)*((-ln(1-0.2))^(1/2)) , range(0 3)) (line xb0 x), legend(label(2 "Q(0.2|x)")) legend(cols(3))Đường phân vị điều kiện 0.2 được ước lượng nằm rất gần với đường thực tế. Để thấy rõ sự khác biệt nhỏ giữa hai đường cong, chúng ta đã loại bớt các quan sát lớn ra khỏi biểu đồ phân tán.
Ước Lượng Tác Động Của Biến Giải Thích
Sự thay đổi trong hàm phân vị điều kiện khi một biến giải thích thay đổi được gọi là tác động của biến số. Ví dụ, tác động khi biến x tăng thêm một đơn vị lên phân vị 0.2 chính là sự chênh lệch giữa giá trị phân vị tại x cộng một và tại x.
1generate orig = x
2replace x = x+1
3predict xb1
4label variable xb1 "x=x+1 predictions"
5replace x = orig
6generate effects = xb1 - xb0
7label variable effects "Q(0.2|(x+1)) - Q(0.2|x)"
8scatter effects x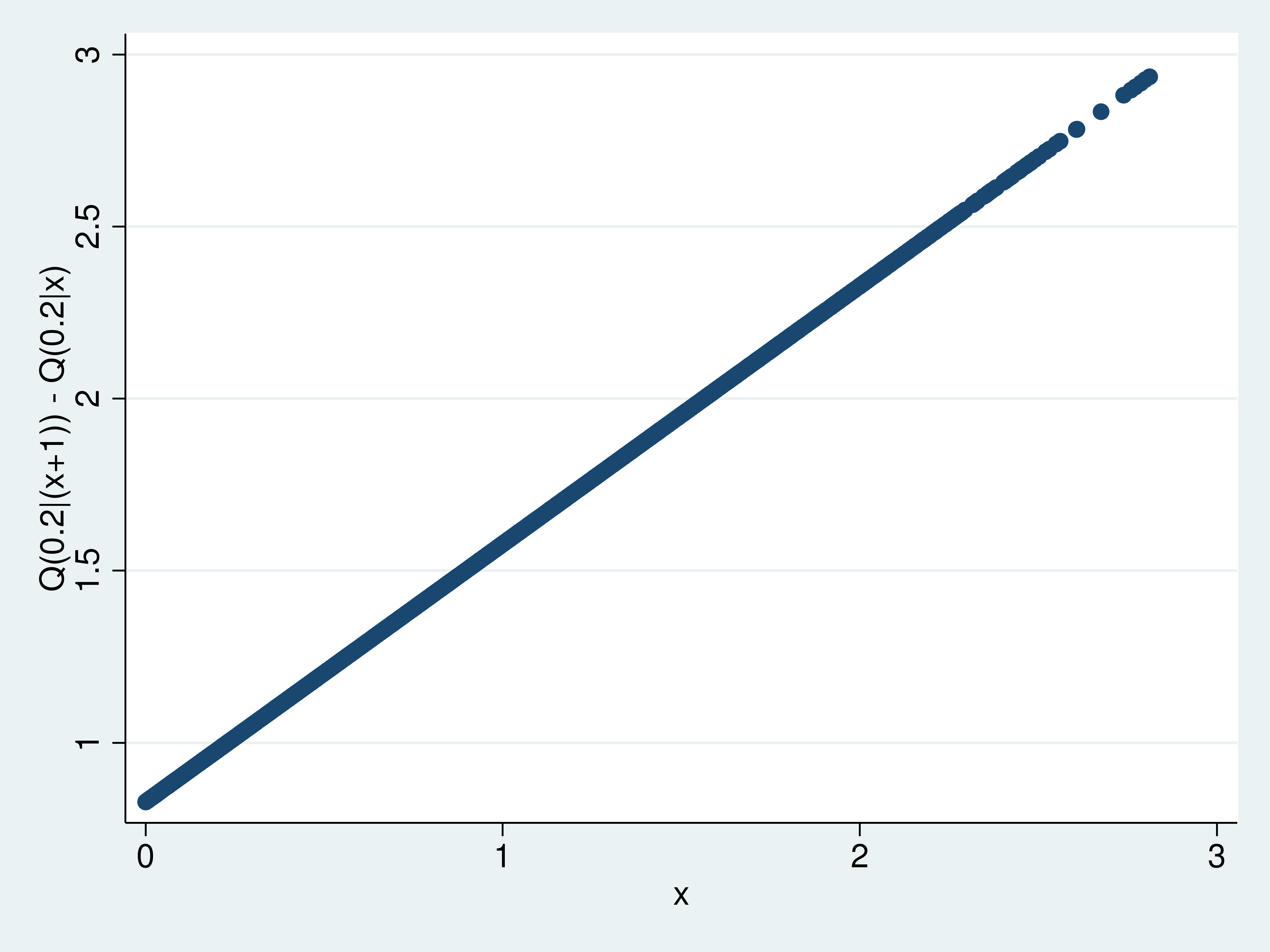
Biểu đồ này cho thấy các tác động thay đổi như thế nào dọc theo biến x, nhưng nó chưa cung cấp thông tin về độ tin cậy của các ước lượng này. Để giải quyết vấn đề đó, lệnh predictnl được sử dụng để ước lượng các biểu thức ở cấp độ quan sát và tạo ra các khoảng tin cậy điểm.
1predictnl effects2 = _b[x] + 2*_b[c.x#c.x]*x + _b[c.x#c.x], ci(low up)
2sort x
3twoway (rarea up low x) (scatter effects2 x), ytitle("Q(0.2|(x+1)) - Q(0.2|x)") legend(off)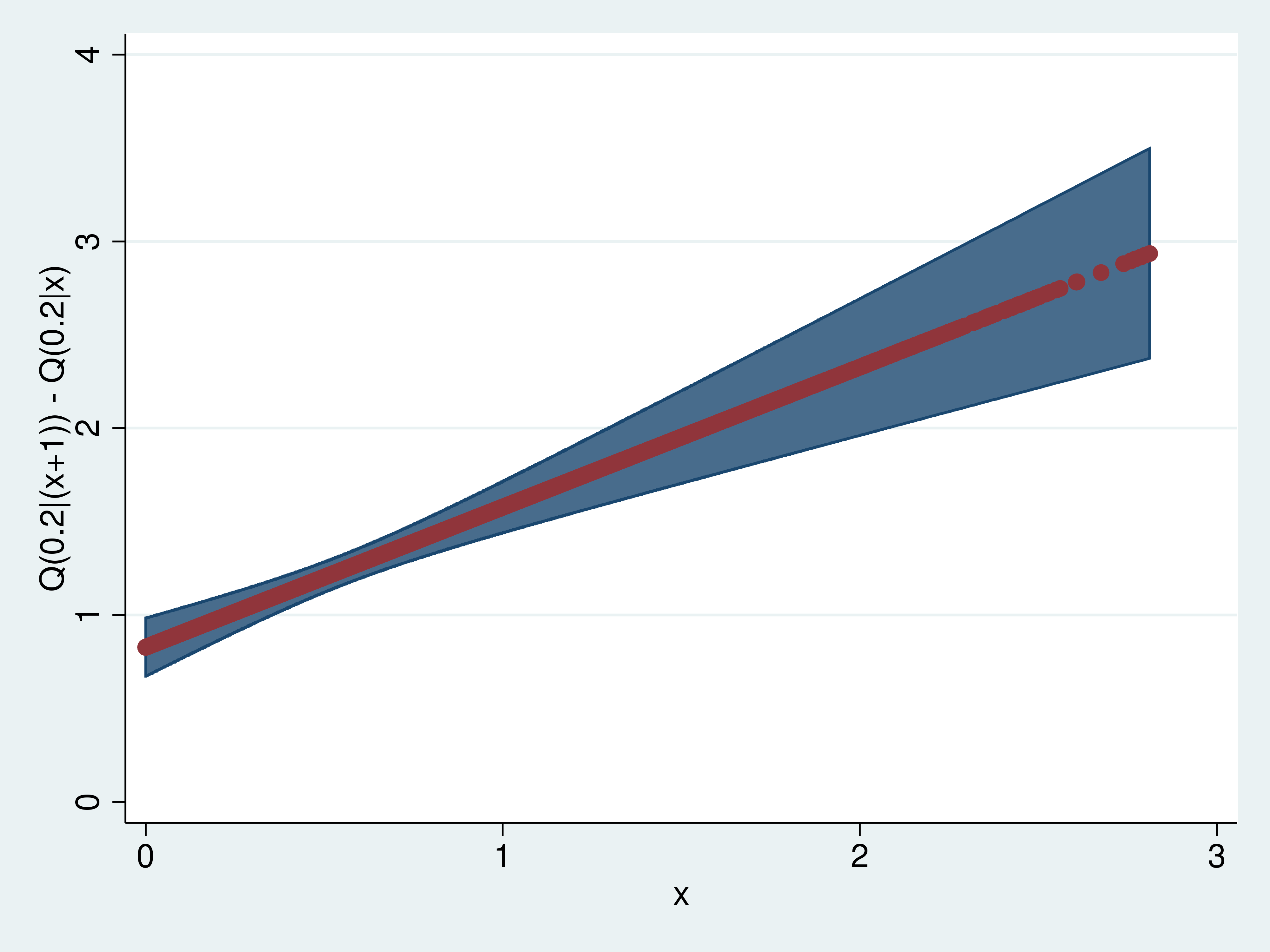
Việc liệt kê các kết quả cho thấy hai cách tính toán đều cho ra cùng một giá trị. Sau khi xác nhận sự tương đương này, chúng ta có thể tự tin biểu diễn các tác động kèm theo khoảng tin cậy.
So Sánh Tác Động Giữa Các Phân Vị Khác Nhau
Lý do chính khiến hồi quy phân vị trở nên quan trọng là vì tác động của biến số có thể khác nhau giữa các phân vị. Giả thuyết ở đây là những người ở thứ hạng thấp sẽ chịu ảnh hưởng khác với những người ở thứ hạng cao. Để so sánh, chúng ta tiếp tục ước lượng hàm phân vị điều kiện cho mức 0.8.
1qreg y x c.x#c.x, quantile(.8)
2predictnl effects3 = _b[x] + 2*_b[c.x#c.x]*x + _b[c.x#c.x], ci(low3 up3)
3label variable effects3 "Q(0.8|(x=1)) - Q(0.8|x)"Cuối cùng, chúng ta vẽ biểu đồ so sánh tác động của việc tăng thêm một đơn vị x lên cả hai mức phân vị 0.2 và 0.8.
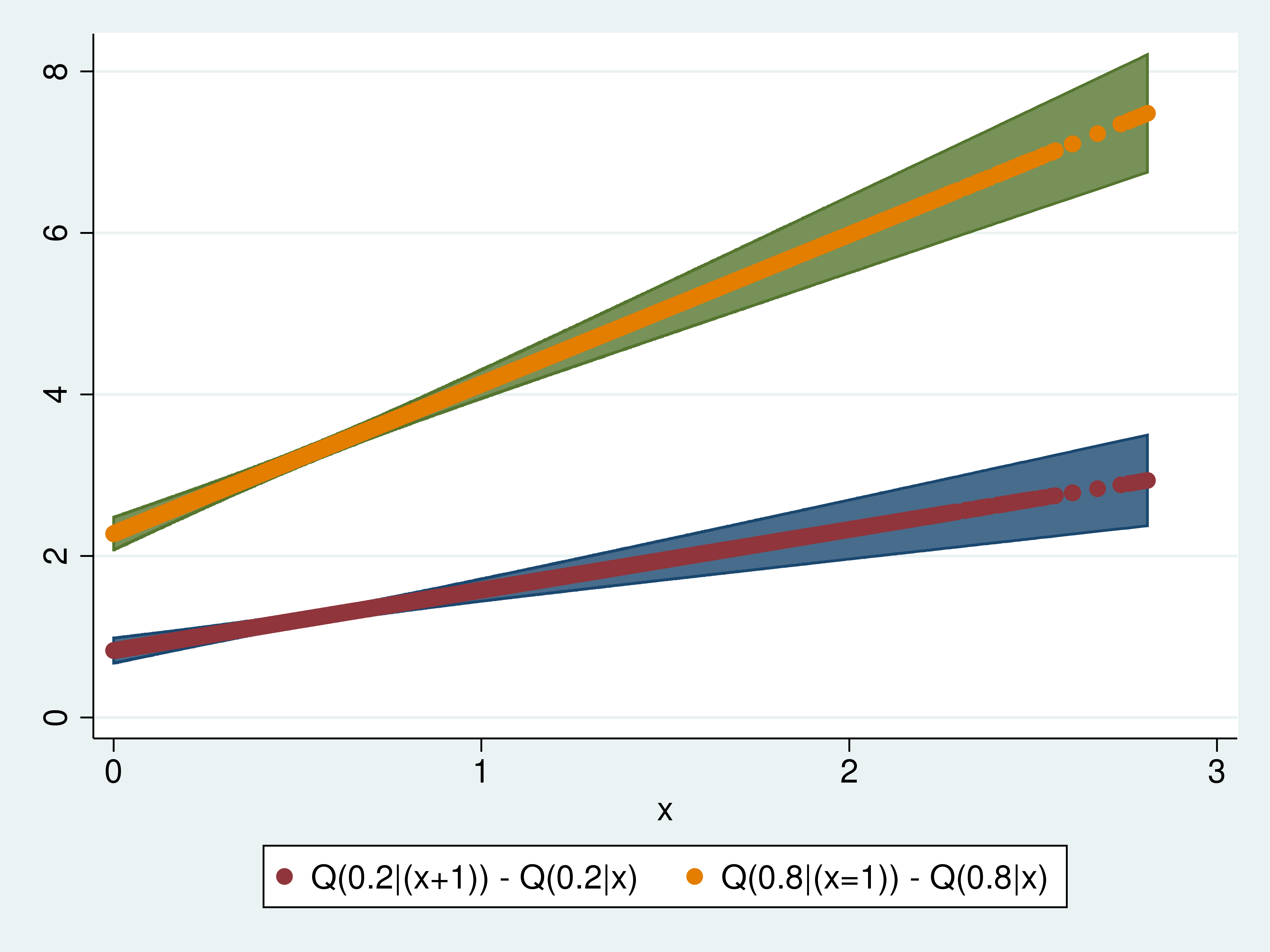
Kết quả cho thấy cả độ lớn và độ dốc của tác động ở phân vị 0.8 đều lớn hơn đáng kể so với ở phân vị 0.2. Điều này minh chứng rằng biến x có ảnh hưởng mạnh mẽ hơn nhiều đối với nhóm đối tượng nằm ở phía trên của phân phối.
✨ Hồi quy phân vị là một công cụ không thể thiếu khi bạn muốn vượt qua giới hạn của giá trị trung bình để khám phá bức tranh toàn cảnh về sự không đồng nhất trong dữ liệu, từ đó đưa ra các nhận định sâu sắc và chính xác hơn về các hiện tượng kinh tế xã hội.
**Câu hỏi tư duy:** Trong trường hợp nào việc sử dụng hồi quy bình phương tối thiểu thông thường có thể dẫn đến những kết luận thiếu sót về tác động của chính sách đối với nhóm người nghèo nhất trong xã hội? Hãy thử áp dụng lệnh qreg với bộ dữ liệu của riêng bạn và so sánh kết quả ở phân vị 0.1 và 0.9.