Việc xác định tính dừng của một chuỗi thời gian là bước quan trọng hàng đầu trước khi bắt đầu bất kỳ phân tích chuyên sâu nào. Hầu hết các đặc tính thống kê của những mô hình ước lượng trong chuỗi thời gian đều dựa trên giả định rằng dữ liệu phải đạt trạng thái dừng yếu. Nói một cách đơn giản, một quy trình dừng yếu có trung bình, phương sai và hiệp phương sai tự hồi quy không thay đổi theo thời gian.
Tuy nhiên, trong thực tế, nhiều chuỗi dữ liệu quan sát được thường chứa các thành phần xu hướng khiến chúng trở nên không dừng. Các xu hướng này có thể là tất định hoặc ngẫu nhiên. Việc phân biệt chính xác loại xu hướng là cực kỳ quan trọng vì mỗi loại yêu cầu một phương pháp xử lý khác nhau để đưa chuỗi về trạng thái dừng. Ví dụ, một xu hướng ngẫu nhiên, thường được gọi là nghiệm đơn vị, có thể được loại bỏ bằng cách lấy sai phân. Ngược lại, nếu chúng ta lấy sai phân một chuỗi có xu hướng tất định, chúng ta sẽ vô tình tạo ra nghiệm đơn vị trong quy trình trung bình trượt.
Hiểu về xu hướng ngẫu nhiên và tất định
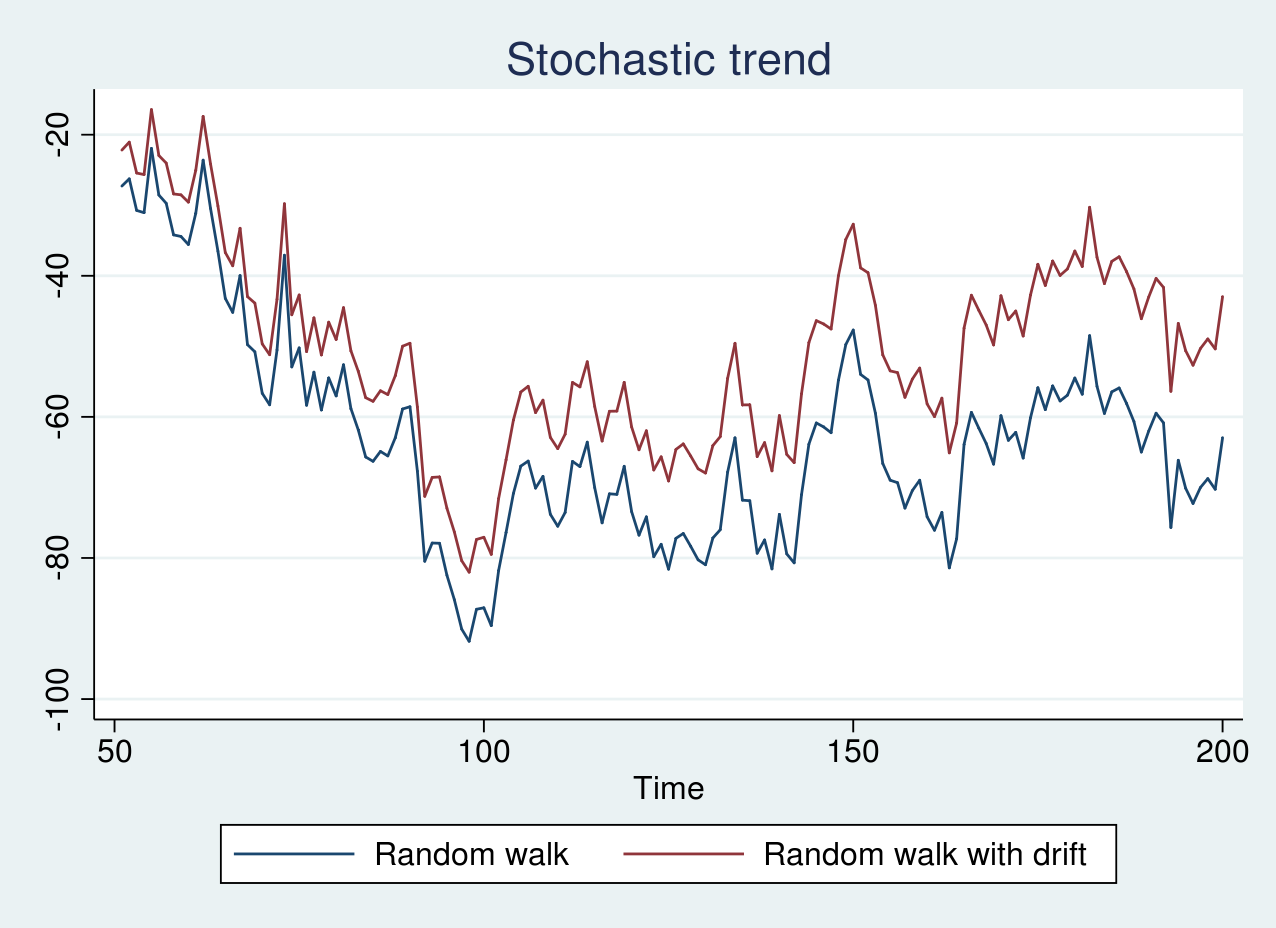
Một ví dụ điển hình của quy trình có xu hướng ngẫu nhiên là bước ngẫu nhiên. Trong mô hình này, giá trị hiện tại được xác định bởi giá trị ngay trước đó cộng với một sai số ngẫu nhiên có trung bình bằng không và phương sai không đổi. Nếu quy trình bắt đầu từ giá trị khởi tạo bằng không, giá trị tại bất kỳ thời điểm nào cũng chính là tổng của các sai số ngẫu nhiên tích lũy. Khi đó, phương sai của chuỗi sẽ tăng dần theo thời gian, khiến chuỗi không đạt được tính dừng.
Nếu chúng ta thêm một hằng số vào mô hình bước ngẫu nhiên, chúng ta sẽ có quy trình bước ngẫu nhiên có hệ số trôi. Lúc này, giá trị của chuỗi bao gồm một thành phần tuyến tính theo thời gian và một thành phần ngẫu nhiên tích lũy. Cả trung bình và phương sai của chuỗi đều sẽ thay đổi theo thời gian.
Đối với xu hướng tất định, mô hình thường bao gồm một hằng số, một biến xu hướng thời gian tuyến tính và một thành phần tự hồi quy với hệ số nhỏ hơn một. Điểm khác biệt quan trọng là chuỗi có xu hướng tất định không chứa thành phần ngẫu nhiên tích lũy như bước ngẫu nhiên.
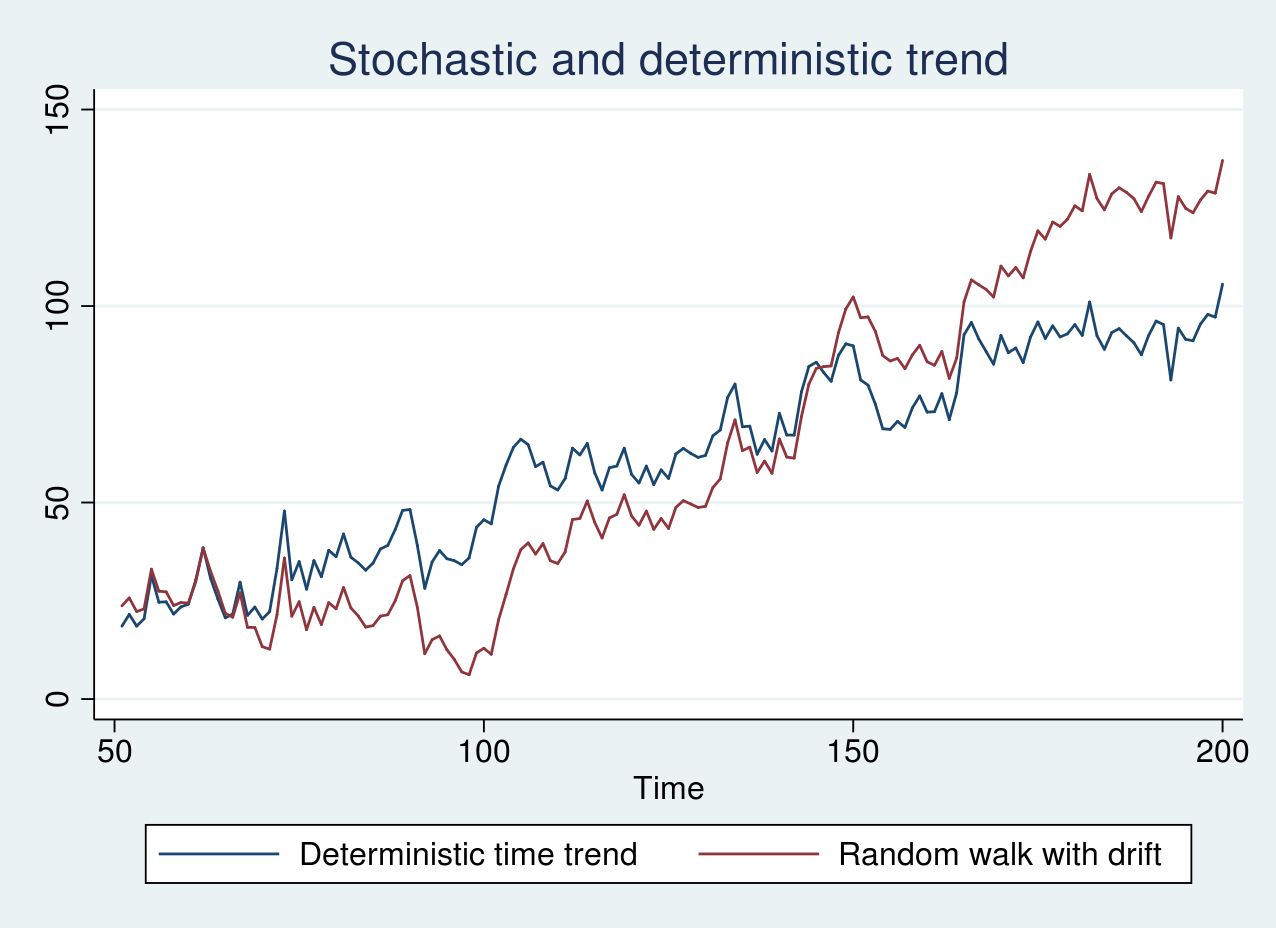
Khi quan sát biểu đồ, chuỗi bước ngẫu nhiên và bước ngẫu nhiên có hệ số trôi thường không thể hiện một xu hướng rõ ràng nếu hệ số trôi quá nhỏ. Tuy nhiên, khi hệ số trôi lớn, biểu đồ của chuỗi bước ngẫu nhiên trông sẽ rất giống với chuỗi có xu hướng thời gian tất định. Điều này khiến việc kiểm định bằng mắt thường trở nên bất khả thi và đòi hỏi các công cụ thống kê chính xác.
Các phương pháp kiểm định nghiệm đơn vị trong Stata
Giả thuyết không của các kiểm định nghiệm đơn vị thường cho rằng quy trình thực sự là một bước ngẫu nhiên hoặc bước ngẫu nhiên có hệ số trôi. Nếu giả thuyết này đúng, các phương pháp hồi quy bình phương tối thiểu thông thường sẽ không còn chính xác và các kiểm định t truyền thống sẽ mất hiệu lực do phân phối của các hệ số ước lượng không còn ở dạng chuẩn.
Kiểm định Augmented Dickey Fuller
Kiểm định này thực hiện hồi quy sai phân của biến phụ thuộc theo giá trị trễ của chính nó và các sai phân trễ bổ sung để xử lý vấn đề tự tương quan của sai số. Trong Stata, lệnh dfuller được sử dụng phổ biến để thực hiện phép thử này. Chúng ta có thể thêm tùy chọn trend để kiểm soát xu hướng thời gian tuyến tính trong mô hình.
Dưới đây là ví dụ thực hiện kiểm định trên dữ liệu mô phỏng cho chuỗi có hệ số trôi và chuỗi có xu hướng tất định:
1. dfuller yrwd2, trend
2Dickey-Fuller test for unit root Number of obs = 149
3 ---------- Interpolated Dickey-Fuller ---------
4 Test 1% Critical 5% Critical 10% Critical
5 Statistic Value Value Value
6----------------------------------------------------------------------------
7 Z(t) -2.664 -4.024 -3.443 -3.143
8----------------------------------------------------------------------------
9MacKinnon approximate p-value for Z(t) = 0.2511Kết quả trên cho thấy p-value bằng 0.2511, lớn hơn các mức ý nghĩa thông thường. Do đó, chúng ta không đủ bằng chứng để bác bỏ giả thuyết không, nghĩa là chuỗi yrwd2 có chứa nghiệm đơn vị (unit root). Tiếp tục thực hiện với chuỗi yt:
1. dfuller yt, trend
2Dickey-Fuller test for unit root Number of obs = 149
3 ---------- Interpolated Dickey-Fuller ---------
4 Test 1% Critical 5% Critical 10% Critical
5 Statistic Value Value Value
6----------------------------------------------------------------------------
7 Z(t) -5.328 -4.024 -3.443 -3.143
8----------------------------------------------------------------------------
9MacKinnon approximate p-value for Z(t) = 0.0000Với p-value xấp xỉ bằng không, chúng ta bác bỏ giả thuyết không và kết luận chuỗi yt là chuỗi dừng xung quanh một xu hướng tất định.
Kiểm định Phillips Perron
Kiểm định này điều chỉnh thống kê kiểm định để tính đến khả năng tự tương quan và phương sai sai số thay đổi. Lệnh pperron trong Stata có cú pháp tương tự như dfuller và thường cho kết quả nhất quán trong các mẫu lớn.
Kiểm định GLS detrended Augmented Dickey Fuller
Đây là một biến thể của kiểm định ADF nhưng dữ liệu được biến đổi qua hồi quy bình phương tối thiểu tổng quát trước khi thực hiện kiểm định. Phương pháp này được chứng minh là có quyền lực thống kê tốt hơn ADF truyền thống. Trong Stata, chúng ta sử dụng lệnh dfgls.
1. dfgls yrwd2, maxlag(4)
2DF-GLS for yrwd2 Number of obs = 145
3 DF-GLS tau 1% Critical 5% Critical 10% Critical
4 [lags] Test Statistic Value Value Value
5---------------------------------------------------------------------------
6 4 -1.404 -3.520 -2.930 -2.643
7 3 -1.420 -3.520 -2.942 -2.654
8 2 -1.638 -3.520 -2.953 -2.664
9 1 -1.644 -3.520 -2.963 -2.673
10Opt Lag (Ng-Perron seq t) = 0 [use maxlag(0)]
11Min SC = 3.31175 at lag 1 with RMSE 5.060941
12Min MAIC = 3.295598 at lag 1 with RMSE 5.060941Mặc định lệnh dfgls sẽ kiểm soát xu hướng thời gian tuyến tính. Kết quả trên một lần nữa xác nhận việc không thể bác bỏ giả thuyết có nghiệm đơn vị cho chuỗi yrwd2.
Phụ lục: Mã nguồn mô phỏng dữ liệu
Để thực hành các kiểm định trên, bạn có thể sử dụng đoạn mã Stata sau để tạo dữ liệu giả lập cho các quy trình bước ngẫu nhiên và xu hướng tất định:
1clear all
2set seed 2016
3local T = 200
4set obs `T'
5gen time = _n
6label var time "Time"
7tsset time
8gen eps = rnormal(0,5)
9gen yrw = eps in 1
10replace yrw = l.yrw + eps in 2/l
11gen yrwd1 = 0.1 + eps in 1
12replace yrwd1 = 0.1 + l.yrwd1 + eps in 2/l
13gen yrwd2 = 1 + eps in 1
14replace yrwd2 = 1 + l.yrwd2 + eps in 2/l
15gen yt = 0.5 + 0.1*time + eps in 1
16replace yt = 0.5 + 0.1*time + 0.8*l.yt + eps in 2/l
17drop in 1/50
18tsline yrw yrwd1, title("Stochastic trend")
19tsline yt yrwd2, title("Stochastic and deterministic trend")✨ Giá trị đắt giá: Việc nhầm lẫn giữa xu hướng ngẫu nhiên và xu hướng tất định có thể dẫn đến những kết luận sai lầm nghiêm trọng trong dự báo. Luôn sử dụng kết hợp nhiều loại kiểm định như ADF và GLS-ADF để tăng độ tin cậy cho kết quả phân tích chuỗi thời gian của bạn.
Câu hỏi tư duy: Tại sao khi một chuỗi có xu hướng tất định, việc lấy sai phân bậc một lại không phải là cách tối ưu để đưa chuỗi về trạng thái dừng so với phương pháp loại bỏ xu hướng bằng hồi quy tuyến tính?