Trong các bài viết trước, tôi đã hướng dẫn cách tính công suất thống kê cho kiểm định t, tích hợp mô phỏng vào lệnh power trong Stata, cũng như áp dụng cho mô hình hồi quy tuyến tính và hồi quy logistic. Hôm nay, chúng ta sẽ tiến thêm một bước xa hơn bằng cách ước lượng công suất thống kê cho các mô hình đa cấp và mô hình dữ liệu dọc thông qua mô phỏng.
Mục tiêu của chúng ta là xây dựng một chương trình có khả năng tính toán công suất thống kê cho các giá trị tham số khác nhau của mô hình. Ví dụ, chúng ta có thể đánh giá sự thay đổi của công suất khi số lượng quan sát ở cấp độ 1 và cấp độ 2 thay đổi trong một nghiên cứu theo thời gian.
Các bước chuẩn bị cho mô phỏng mô hình đa cấp
Để thực hiện mô phỏng một cách hệ thống, chúng ta sẽ tuân theo quy trình gồm bảy bước cụ thể. Trong ví dụ này, hãy tưởng tượng bạn đang lập kế hoạch cho một nghiên cứu dọc về trọng lượng của trẻ em và bạn đặc biệt quan tâm đến sự tương tác giữa độ tuổi và giới tính.
Xác định mô hình hồi quy và các tham số
Bước đầu tiên là viết ra mô hình toán học bao gồm tất cả các tham số cần thiết. Mô hình của chúng ta có dạng: trọng lượng của trẻ i tại thời điểm t bằng hệ số chặn beta 0 cộng với beta 1 nhân với tuổi, cộng beta 2 nhân với biến giả giới tính nữ, cộng với beta 3 nhân với biến tương tác giữa tuổi và giới tính nữ. Ngoài ra, mô hình còn bao gồm các sai số ngẫu nhiên u0i cho hệ số chặn, u1i cho hệ số góc của biến tuổi và sai số quan sát eit.
Chúng ta giả định rằng các sai số ngẫu nhiên u0i, u1i và eit đều tuân theo phân phối chuẩn với trung bình bằng 0 và các phương sai tương ứng là tau 0, tau 1 và sigma. Chúng ta cũng giả định hiệp phương sai giữa tau 0 và tau 1 bằng 0 để đơn giản hóa.
Thiết lập chi tiết cho các biến hiệp biến
Vì đây là một nghiên cứu dọc, chúng ta cần xác định độ tuổi bắt đầu, khoảng thời gian giữa các lần đo và tổng số lần đo. Chúng ta cũng cần xem xét tỷ lệ nam và nữ trong mẫu nghiên cứu. Giả sử chúng ta sẽ đo trọng lượng của trẻ em mỗi 6 tháng một lần trong vòng 2 năm, bắt đầu từ 12 tháng tuổi, và mẫu sẽ có tỷ lệ giới tính cân bằng 50 phần trăm nữ.
Tìm kiếm giá trị tham số hợp lý
Chúng ta có thể chọn giá trị tham số dựa trên các nghiên cứu trước đây hoặc dữ liệu thử nghiệm. Ở đây, tôi sử dụng tập dữ liệu về trọng lượng của trẻ em châu Á để ước lượng các thông số ban đầu.
1use http://www.stata-press.com/data/r16/childweight.dta, clear
2describe
3list in 1/5
4mixed weight c.age##i.girl || id: age, stddevTừ kết quả của mô hình hỗn hợp trên, chúng ta có thể rút ra các giá trị ước lượng: beta 0 bằng 5.35, beta 1 bằng 3.59, beta 2 bằng âm 0.47, beta 3 bằng âm 0.24. Các độ lệch chuẩn cho thành phần ngẫu nhiên lần lượt là tau 0 bằng 0.24, tau 1 bằng 0.57 và sigma bằng 1.17.
Thực hiện mô phỏng và kiểm tra mô hình
Sau khi đã có các thông số, chúng ta tiến hành tạo một tập dữ liệu giả lập và khớp mô hình để kiểm tra xem quy trình có hoạt động chính xác hay không.
Mô phỏng một tập dữ liệu đơn lẻ
Dưới đây là mã lệnh để tạo dữ liệu cho 200 trẻ em với 5 lần đo cho mỗi trẻ.
1set seed 16
2clear
3set obs 200
4generate child = _n
5generate female = rbinomial(1,0.5)
6generate u_0i = rnormal(0,0.25)
7generate u_1i = rnormal(0,0.60)
8expand 5
9bysort child: generate age = (_n-1)*0.5
10generate interaction = age*female
11generate e_ij = rnormal(0,1.2)
12generate weight = 5.35 + 3.6*age + (-0.5)*female + (-0.25)*interaction + u_0i + age*u_1i + e_ij
13mixed weight age i.female c.age#i.female || child: age , stddev nolog noheaderĐể kiểm tra giả thuyết rằng hệ số của biến tương tác bằng 0, chúng ta sử dụng kiểm định tỷ số hợp lý bằng cách so sánh mô hình đầy đủ và mô hình rút gọn.
1estimates store full
2mixed weight age i.female || child: age , stddev nolog noheader
3estimates store reduced
4lrtest full reducedXử lý vấn đề hội tụ trong mô phỏng
Khi chạy mô phỏng hàng nghìn lần, một số mô hình có thể không hội tụ do dữ liệu ngẫu nhiên không tương thích. Điều này có thể làm chậm quá trình mô phỏng đáng kể. Để xử lý, chúng ta thêm tùy chọn giới hạn số vòng lặp và kiểm tra trạng thái hội tụ của mô hình trước khi tính toán p-value.
1mixed weight age i.female c.age#i.female || child: age, iter(200)
2local conv1 = e(converged)
3estimates store full
4mixed weight age i.female || child: age, iter(200)
5local conv2 = e(converged)
6estimates store reduced
7lrtest full reduced
8local reject = cond(`conv1'+`conv2'==2, r(p)<`alpha', .)Tự động hóa với lệnh power trong stata
Để thuận tiện cho việc đánh giá công suất trên nhiều quy mô mẫu khác nhau, chúng ta sẽ đóng gói toàn bộ quy trình vào các chương trình con.
Xây dựng chương trình mô phỏng simmixed
Chương trình này sẽ thực hiện việc tạo dữ liệu, khớp mô hình và trả về kết quả bác bỏ giả thuyết không.
1capture program drop simmixed
2program simmixed, rclass
3 version 16
4 syntax, n1(integer) n(integer) [ alpha(real 0.05) intercept(real 5.35) age(real 3.6) female(real -0.5) interact(real -0.25) u0i(real 0.25) u1i(real 0.60) eij(real 1.2) ]
5 quietly {
6 drop _all
7 set obs `n'
8 generate child = _n
9 generate female = rbinomial(1,0.5)
10 generate u_0i = rnormal(0,`u0i')
11 generate u_1i = rnormal(0,`u1i')
12 expand `n1'
13 bysort child: generate age = (_n-1)*0.5
14 generate interaction = age*female
15 generate e_ij = rnormal(0,`eij')
16 generate weight = `intercept' + `age'*age + `female'*female + `interact'*interaction + u_0i + age*u_1i + e_ij
17 mixed weight age i.female c.age#i.female || child: age, iter(200)
18 local conv1 = e(converged)
19 estimates store full
20 mixed weight age i.female || child: age, iter(200)
21 local conv2 = e(converged)
22 estimates store reduced
23 lrtest full reduced
24 local reject = cond(`conv1' + `conv2'==2, (r(p)<`alpha'), .)
25 }
26 return scalar reject = `reject'
27 return scalar conv = `conv1'+`conv2'end
Tích hợp hoàn toàn vào hệ thống Power và Sample Size
Cuối cùng, chúng ta viết thêm chương trình điều khiển và chương trình khởi tạo để có thể sử dụng danh sách số lượng quan sát.
1capture program drop power_cmd_simmixed
2program power_cmd_simmixed, rclass
3 version 16
4 syntax, n1(integer) n(integer) [ alpha(real 0.05) intercept(real 5.35) age(real 3.6) female(real -0.5) interact(real -0.25) u0i(real 0.25) u1i(real 0.60) eij(real 1.2) reps(integer 1000) ]
5 quietly {
6 simulate reject=r(reject), reps(`reps'): simmixed, n1(`n1') n(`n') alpha(`alpha') intercept(`intercept') age(`age') female(`female') interact(`interact') u0i(`u0i') u1i(`u1i') eij(`eij')
7 summarize reject
8 }
9 return scalar power = r(mean)
10 return scalar n1 = `n1'
11 return scalar N = `n'
12 return scalar alpha = `alpha'capture program drop power_cmd_simmixed_init
program power_cmd_simmixed_init, sclass
version 16
sreturn clear
sreturn local pss_colnames "n1 intercept age female interact u0i u1i eij"
sreturn local pss_numopts "n1 intercept age female interact u0i u1i eij"
end
end
Bây giờ, chúng ta có thể dễ dàng chạy các phân tích phức tạp với bảng biểu và đồ thị minh họa.
1power simmixed, n1(5 6) n(100(100)500) reps(1000) table(n1 N power) graph(ydimension(power) xdimension(N) plotdimension(n1) xtitle(Level 2 Sample Size) legend(title(Level 1 Sample Size)))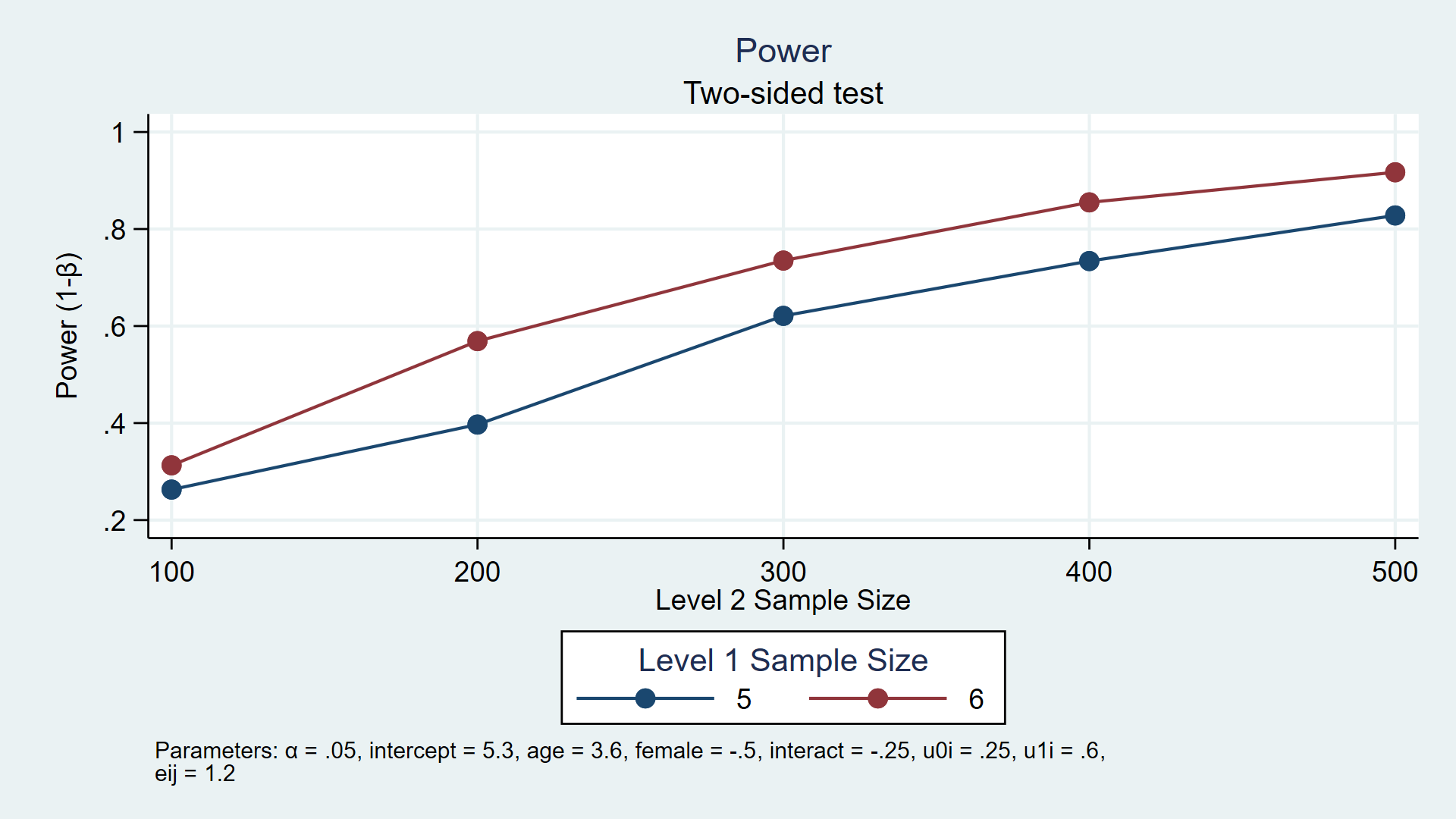
Kết quả từ bảng và đồ thị cho thấy công suất đạt mức 80 phần trăm với một vài sự kết hợp mẫu. Dựa trên các giả định, chúng ta ước tính cần khoảng 400 trẻ em với 6 lần đo mỗi trẻ, hoặc 500 trẻ em với 5 lần đo mỗi trẻ để phát hiện tham số tương tác ở mức âm 0.25.
✨ Việc sử dụng mô phỏng Monte Carlo giúp nhà nghiên cứu chủ động hơn trong việc thiết kế các nghiên cứu đa cấp phức tạp, nơi mà các công thức tính toán sẵn có thường không đáp ứng đủ các ràng buộc thực tế.
Câu hỏi tư duy và bài tập ứng dụng
1. Nếu phương sai của sai số ngẫu nhiên u1i tăng gấp đôi, bạn dự đoán công suất thống kê sẽ thay đổi như thế nào đối với cùng một quy mô mẫu?
2. Hãy thử sửa đổi chương trình simmixed để giả định tỷ lệ nữ giới trong mẫu chỉ chiếm 30 phần trăm thay vì 50 phần trăm và thực hiện lại tính toán công suất. Quyết định về quy mô mẫu của bạn sẽ thay đổi ra sao?