
Sự phụ thuộc chéo
Sự phụ thuộc chéo (Cross-Sectional Dependence) đề cập đến mối tương quan giữa các đối tượng tại cùng một thời điểm. Ví dụ về thương mại quốc tế được đại diện bởi tổng kim ngạch xuất nhập khẩu, quan sát tại hai quốc gia A và B, lượng nhập khẩu quốc gia A tăng cũng có nghĩa làm tăng lượng xuất khẩu của quốc gia B, và cùng làm tăng tổng kim ngạch xuất nhập khẩu của cả hai quốc gia. Trên thực tế, hầu hết các quốc gia có hoạt động thương mại qua lại lẫn nhau, dẫn đến sự tương quan về tổng kim ngạch XNK giữa các quốc gia, hay dữ liệu bảng quan sát hoạt động thương mại này có thể tồn tại sự phụ thuộc chéo.
Ở khía cạnh kinh tế lượng, sự phụ thuộc chéo thường được xác định dựa trên kiểm định được đề xuất bởi Pesaran (2004). Xét mô hình dữ liệu bảng:
Giả thuyết cho kiểm định sự phụ thuộc chéo như sau:
Số cặp phụ thuộc chéo có thể có tăng theo số đối tượng (N).
Đối với dữ liệu bảng cân bằng:
Đối với dữ liệu bảng không cân bằng:
Với
Kiểm định của Pesaran (2004) đề xuất được sử dụng đối với dữ liệu bảng có N lớn, T nhỏ. Tuy nhiên, đối với dữ liệu bảng có N nhỏ, kiểm định này vẫn cho thấy hiệu quả. Hơn nữa, kiểm định có thể sử dụng đối với cả dữ liệu bảng cân bằng và không cân bằng. Do vậy, kiểm định sự phụ thuộc chéo do Pesaran (2004) đề xuất được ứng dụng rộng rãi. Hiện nay, đã có một số kiểm định sự phụ thuộc chéo được phát triển thêm như Weighted CD (Juodis and Reese, 2022), Power Enhanced CD (Juodis and Reese, 2022 and Fan et. al., 2015) và CD Star (Pesaran & Xie, 2021).
Thực hành trên STATA
Tải dữ liệu SciEco_trade.
1//Nhập dữ liệu
2 use SciEco_trade, clear
3
4//Khai báo dữ liệu bảng
5 xtset ID year
6
7//Tính tổng kim ngạch XNK
8 gen trade_total=export+import
9
10//Ước lượng FEM/REM
11 xtreg trade_total,fe
12
13//Kiểm định CSD
14 xtcsd, pesaran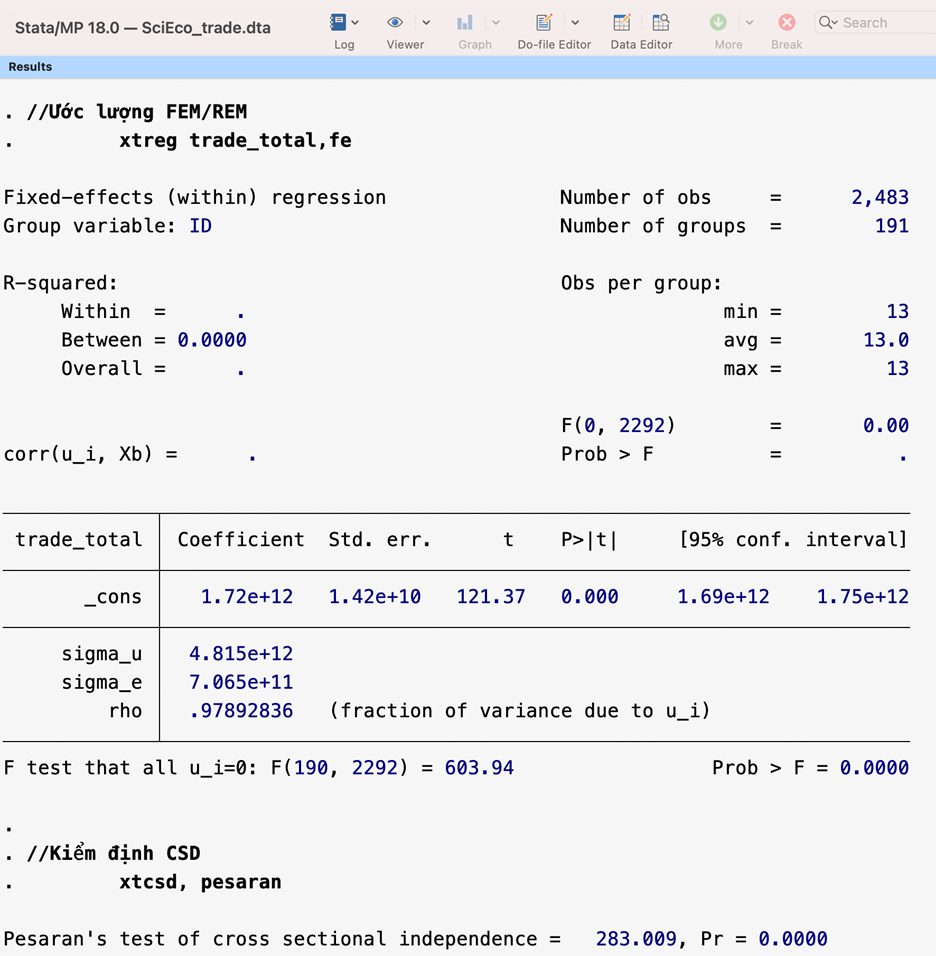
Kết quả kiểm định sự phụ thuộc chéo đối với biến trade_total có P_value=0.000, do đó, bác bỏ giả thuyết , hay tồn tại sự thuộc chéo.
Áp dụng tương tự với những biến còn lại trong mô hình nghiên cứu của bạn để có góc nhìn tổng thể về vấn đề phụ thuộc chéo trong dữ liệu, từ đó đưa ra các quyết định lựa chọn phương pháp kiểm định nghiệm đơn vị, đồng tích hợp… phù hợp. Sự chi phối của vấn đề phụ thuộc chéo đến quyết định lựa chọn các kiểm định khác của dữ liệu bảng là nội dung quan trọng và SciEco sẽ giới thiệu trong các bài viết tiếp theo.

