Trong phân tích chuỗi thời gian, việc xử lý các dữ liệu có tính chu kỳ theo ngày luôn là một thách thức lớn đối với các nhà khoa học dữ liệu. Một trong những công cụ mạnh mẽ và linh hoạt nhất hiện nay để giải quyết vấn đề này là mô hình ADAM. Đây là một khung mô hình thích ứng động giúp nắm bắt hiệu quả các đặc tính phức tạp của dữ liệu tài chính mà không cần quá nhiều bước tiền xử lý thủ công.
Khám phá sức mạnh của mô hình ADAM trong phân tích tài chính
Mô hình ADAM tỏ ra đặc biệt hiệu quả khi áp dụng vào các chỉ số chứng khoán như BIST 100. Điểm ưu việt của phương pháp này nằm ở khả năng tự động nhận diện xu hướng và tính chu kỳ vốn có trong dữ liệu. Thay vì phải tạo ra hàng loạt biến ngoại sinh thông qua các bước trích xuất đặc trưng từ thời gian, thuật toán ADAM có thể tự điều chỉnh để khớp với cấu trúc của chuỗi số liệu một cách tự nhiên.
Việc tinh giản quy trình chuẩn bị dữ liệu không chỉ giúp tiết kiệm thời gian mà còn giảm thiểu rủi ro gây nhiễu cho mô hình. Khi các thành phần xu hướng và chu kỳ được xử lý nội tại, mô hình sẽ giữ được độ tinh gọn cần thiết mà vẫn đảm bảo độ chính xác cao trong các khoảng dự báo.
Triển khai mô hình với ngôn ngữ R
Để thực hiện dự báo, chúng ta sử dụng hệ sinh thái tidymodels kết hợp với thư viện modeltime. Quy trình bắt đầu từ việc lấy dữ liệu từ các nguồn tài chính, sau đó phân chia dữ liệu thành tập huấn luyện và tập kiểm tra để đảm bảo tính khách quan khi đánh giá hiệu suất.
Quy trình xây dựng và hiệu chuẩn mô hình
Bước đầu tiên là thực hiện kiểm tra tính chu kỳ để hiểu rõ hơn về cấu trúc dữ liệu. Sau đó, chúng ta thiết lập công cụ dự báo bằng cách sử dụng hàm adam_reg. Quá trình hiệu chuẩn đóng vai trò quan trọng trong việc tinh chỉnh các tham số dựa trên tập kiểm tra, từ đó đưa ra các chỉ số sai số thực tế như RMSE hoặc MAPE.
Đoạn mã dưới đây minh họa toàn bộ quy trình từ tải dữ liệu đến vẽ biểu đồ dự báo:
1library(tidyverse)
2library(tidyquant)
3library(tidymodels)
4library(timetk)
5library(modeltime)
6df_bist <-
7 tq_get("XU100.IS") %>%
8 select(date, close)
9splits <-
10 time_series_split(
11 df_bist,
12 assess = "1 month",
13 cumulative = TRUE
14 )
15df_train <- training(splits)
16df_test <- testing(splits)
17mod_adam <-
18 adam_reg() %>%
19 set_engine("auto_adam")
20mod_fit <-
21 mod_adam %>%
22 fit(formula = close ~ date, data = df_train)
23calibration_tbl <-
24 mod_fit %>%
25 modeltime_calibrate(new_data = df_test)
26calibration_tbl %>%
27 modeltime_accuracy(metric_set = metric_set(rmse, rsq, mape))
28calibration_tbl %>%
29 modeltime_forecast(new_data = df_test,
30 actual_data = df_test) %>%
31 plot_modeltime_forecast(.interactive = FALSE,
32 .legend_show = FALSE,
33 .line_size = 1.5,
34 .color_lab = "",
35 .title = "BIST 100") +
36 labs(subtitle = "Khoảng dự báo của mô hình ADAM") +
37 scale_y_continuous(labels = scales::label_currency(prefix = "₺",
38 suffix = "")) +
39 scale_x_date(labels = scales::label_date("%b %d"),
40 date_breaks = "4 days") +
41 theme_minimal()Đánh giá kết quả dự báo
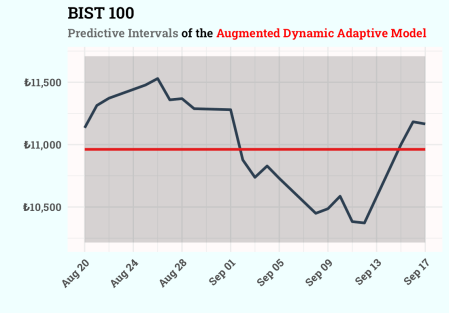
Kết quả từ mô hình ADAM cung cấp cái nhìn trực quan về biến động của chỉ số chứng khoán trong tương lai gần. Các khoảng dự báo giúp nhà đầu tư và các chuyên gia phân tích định lượng xác định được phạm vi dao động khả thi của giá đóng cửa. Việc sử dụng biểu đồ tĩnh với các tùy chỉnh về màu sắc và bố cục giúp thông tin được truyền tải một cách chuyên nghiệp và dễ hiểu hơn.
✨ Giá trị đắt giá của mô hình ADAM nằm ở khả năng cân bằng giữa sự đơn giản trong triển khai và sức mạnh trong phân tích nội tại, giúp nhà nghiên cứu tập trung vào việc giải thích kết quả thay vì sa lầy vào các bước kỹ thuật phức tạp.
Câu hỏi tư duy: Theo bạn, trong trường hợp dữ liệu có những biến động đột ngột do sự kiện kinh tế lớn, chúng ta có nên bổ sung các biến giả hay vẫn nên tin tưởng hoàn toàn vào khả năng tự thích ứng của mô hình ADAM?