Trong bài phân tích trước, chúng ta đã làm quen với mô hình tuyến tính tổng quát thông qua một tập dữ liệu khá đặc biệt: số ca tử vong do ngựa đá trong quân đội Phổ. Tập dữ liệu này đếm số lượng tử vong của các quân đoàn qua từng năm. Vì đây là dữ liệu đếm, chúng ta đã điều chỉnh mô hình tuyến tính để sử dụng phân phối Poisson, đồng thời áp dụng hàm liên kết log.
Tuy nhiên, có một khía cạnh mà chúng ta chưa xem xét: liệu tất cả các quân đoàn có tỷ lệ tử vong giống hệt nhau không?
Khám phá dữ liệu theo từng nhóm
Trước tiên, chúng ta cần thiết lập môi trường trong R.
1library(tidyverse)
2library(knitr)
3library(Horsekicks)
4prussian.colours <- c("#333333", "#F9BE11", "#BE0007")
5hk.tidy <- hkdeaths |>
6 pivot_longer(
7 c(kick, drown, fall),
8 names_to = "death.type",
9 values_to = "death.count"
10 )Tiếp theo, chúng ta sẽ vẽ biểu đồ số ca tử vong theo thời gian cho từng quân đoàn để xem xu hướng của chúng có tương đồng hay có sự khác biệt rõ rệt. Tập dữ liệu cung cấp ba loại tử vong do tai nạn, cho phép chúng ta kiểm tra toàn diện cả ba loại này.
1ggplot(hk.tidy) +
2 aes(x = year, y = death.count, colour = death.type) +
3 facet_grid(
4 rows = vars(death.type),
5 cols = vars(corps),
6 scale = "free_y",
7 switch = "y"
8 ) +
9 scale_colour_manual(values = prussian.colours, name = "Death type") +
10 geom_line(show.legend = FALSE) +
11 labs(x = "Year", y = "Number of deaths") +
12 stat_smooth(
13 method = "glm",
14 se = F,
15 formula = y ~ x,
16 method.args = list(family = poisson),
17 show.legend = F
18 ) +
19 theme_minimal() +
20 theme(
21 axis.text.x = element_blank(),
22 axis.text.y = element_blank(),
23 panel.grid = element_blank(),
24 panel.border = element_rect(colour = "grey", fill = "transparent")
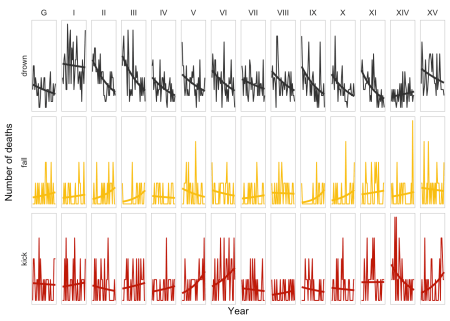
25 )Biểu đồ trên áp dụng mô hình tuyến tính tổng quát cho từng nhóm, giúp chúng ta dễ dàng nhận thấy xu hướng riêng của mỗi quân đoàn. Rõ ràng là có sự khác biệt. Ví dụ, quân đoàn XIV là đơn vị duy nhất có số ca tử vong do đuối nước tăng lên theo thời gian, nhưng lại có sự cải thiện lớn nhất về số ca tử vong do ngựa đá. Mặc dù vậy, đây chưa chắc đã là cách khớp đường xu hướng tốt nhất vì lượng dữ liệu của mỗi quân đoàn khá ít.
Điều này có thể được giải thích do sự thay đổi về số lượng binh lính hoặc ngựa qua các năm, trong khi tỷ lệ tử vong trên đầu người thực chất vẫn giữ nguyên. Đáng tiếc là tập dữ liệu không bao gồm thông tin về quân số, nhưng nó cho thấy số lượng trung đoàn trong mỗi quân đoàn là không đổi. Trong khuôn khổ phân tích thống kê, chúng ta không quá bận tâm đến nguyên nhân thực tế mà chỉ coi đây là một thử nghiệm trên dữ liệu.
Giới thiệu về mô hình hiệu ứng hỗn hợp
Làm thế nào để cải thiện mô hình nhằm đáp ứng những khác biệt ở cấp độ quân đoàn này? Giải pháp chính là mô hình hiệu ứng hỗn hợp (Mixed Effects Models).
Phương pháp này, đôi khi còn được gọi là mô hình đa cấp hay mô hình phân cấp, mô tả biến phản hồi như là kết quả của các hiệu ứng cố định kết hợp với các hiệu ứng ngẫu nhiên theo cụm. Điều này có nghĩa là bên cạnh một xu hướng chung toàn cầu cho tất cả các quan sát, còn có các xu hướng riêng cho từng nhóm nhỏ bên trong dữ liệu.
Các hiệu ứng cố định đóng vai trò giống như trong mô hình tuyến tính thông thường, ở đây là hệ số chặn và hệ số góc cho biến thời gian. Đồng thời, mô hình cũng tiến hành tìm ra các hệ số riêng cho từng quân đoàn dựa trên nền tảng của các hiệu ứng cố định.
Ở góc độ mô hình tuyến tính cơ bản, biến phản hồi là số ca tử vong và biến dự báo là năm. Chúng ta sẽ có hai bộ hệ số. Bộ hệ số hiệu ứng cố định đại diện cho xu hướng chung, trong khi bộ hệ số hiệu ứng ngẫu nhiên đại diện cho độ lệch của từng quân đoàn. Những hiệu ứng ngẫu nhiên này được giả định là tuân theo phân phối chuẩn với giá trị trung bình bằng không. Phương sai của hiệu ứng ngẫu nhiên chính là thông số mà thuật toán sẽ học. Tóm lại, kỳ vọng về số ca tử vong của mỗi quân đoàn là sự kết hợp tuyến tính giữa xu hướng chung, đặc điểm riêng của quân đoàn đó và sai số chuẩn.
Việc mở rộng khái niệm này thành mô hình tuyến tính tổng quát hỗn hợp khá đơn giản: chỉ cần chọn một phân phối và một hàm liên kết phù hợp. Tương tự như phân tích trước, chúng ta tiếp tục sử dụng phân phối Poisson và hàm liên kết log.
Xây dựng mô hình với gói lme4
Dưới đây là cách triển khai mô hình trong R bằng gói lme4, tập trung vào việc dự báo dữ liệu tử vong do đuối nước.
1library(lme4)
2midyear <- quantile(hkdeaths$year, 0.5)
3fit <- glmer(
4 drown ~ I(year - midyear) + (1 + I(year - midyear) | corps),
5 family = poisson,
6 data = hkdeaths
7)
8summary(fit)1Generalized linear mixed model fit by maximum likelihood (Laplace
2 Approximation) [glmerMod]
3 Family: poisson ( log )
4Formula: drown ~ I(year - midyear) + (1 + I(year - midyear) | corps)
5 Data: hkdeaths
6 AIC BIC logLik -2*log(L) df.resid
7 2076.0 2096.7 -1033.0 2066.0 457
8Random effects:
9 Groups Name Variance Std.Dev. Corr
10 corps (Intercept) 6.600e-02 0.256900
11 I(year - midyear) 9.499e-05 0.009746 0.12
12Number of obs: 462, groups: corps, 14
13Fixed effects:
14 Estimate Std. Error z value Pr(>|z|)
15(Intercept) 1.364285 0.072815 18.74 < 2e-16
16I(year - midyear) -0.023013 0.003624 -6.35 2.15e-10 Điểm đáng chú ý trong đoạn mã trên là biến thời gian đã được xác định lại thành khoảng cách từ năm trung vị. Kỹ thuật này giúp tránh các vấn đề về hội tụ của thuật toán tối ưu và làm cho hệ số chặn dễ diễn giải hơn. Phần cú pháp chứa ký hiệu gạch đứng bên trong ngoặc đơn chỉ định việc tạo ra hệ số chặn và hệ số góc riêng cho từng quân đoàn.
Chúng ta có thể trích xuất các hiệu ứng ngẫu nhiên của mỗi quân đoàn để kiểm tra. Cần nhớ rằng giá trị này được cộng thêm vào hiệu ứng cố định chung, do đó một hệ số góc dương ở đây chỉ mang ý nghĩa là tốc độ giảm tử vong của quân đoàn đó chậm hơn mức trung bình toàn cục, chứ không hẳn là số ca tử vong đang tăng lên.
1ranef(fit)$corps |> kable(digits = 3)1 (Intercept) I(year - midyear)
2G -0.246 0.003
3I 0.548 0.014
4II 0.151 -0.007
5III 0.230 -0.007
6IV -0.168 -0.003
7V 0.000 0.001
8VI 0.062 -0.001
9VII -0.019 0.005
10VIII 0.057 0.000
11IX 0.009 -0.007
12X -0.151 -0.005
13XI -0.188 -0.010
14XIV -0.473 0.013
15XV 0.257 0.006Kết quả phân tích cho thấy mô hình đánh giá quân đoàn I có hệ số góc dương lớn hơn một chút so với quân đoàn XIV. Điều này khá bất ngờ nhưng hoàn toàn có thể hiểu được nếu bạn đối chiếu lại với biểu đồ xu hướng trực quan ở phần đầu.
✨ Giá trị đắt giá: Khả năng vay mượn thông tin chéo giữa các nhóm là ưu điểm vượt trội của phương pháp luận này. Thay vì xây dựng một mô hình chung cứng nhắc bỏ qua đặc thù của từng nhóm, hoặc chia nhỏ dữ liệu để xây dựng hàng chục mô hình độc lập dễ bị quá khớp do thiếu hụt dữ liệu, kiến trúc phân cấp giúp bạn cân bằng hoàn hảo giữa xu hướng tổng thể và độ lệch địa phương.
Giả sử bạn có dữ liệu điểm thi của học sinh từ hàng trăm trường học khác nhau được thu thập liên tục trong nhiều năm. Bạn sẽ thiết lập biến phản hồi, hiệu ứng cố định và hiệu ứng ngẫu nhiên như thế nào để đánh giá tốc độ cải thiện chất lượng giáo dục của từng trường học mà không bị nhiễu bởi sự khác biệt về quy mô học sinh?