Giả sử bạn đang làm việc với một mô hình có các tham số mang tính phi tuyến. Đó có thể là mô hình tăng trưởng của một cái cây với mức tiệm cận đạt giá trị tối đa, hoặc mô hình nồng độ huyết thanh của một loại thuốc tăng nhanh đến mức đỉnh rồi giảm dần theo hàm mũ. Thông thường, bạn sẽ dùng hồi quy phi tuyến để khớp mô hình này. Nhưng vấn đề đặt ra là: điều gì sẽ xảy ra nếu bạn có các phép đo lặp lại cho cùng một cái cây hoặc các mức huyết thanh được đo nhiều lần trên cùng một bệnh nhân? Bạn sẽ cần tính toán đến sự tương quan dữ liệu bên trong cùng một cá thể. Thậm chí, bạn có thể cho rằng mỗi cái cây có một mức tăng trưởng tiệm cận của riêng nó. Đây chính là lúc bạn cần đến các mô hình hỗn hợp phi tuyến, hay còn gọi là mô hình phân cấp phi tuyến hoặc mô hình đa cấp phi tuyến.
Giới thiệu về mô hình hỗn hợp phi tuyến
Lệnh menl được giới thiệu trong Stata giúp chúng ta khớp các mô hình hỗn hợp phi tuyến một cách dễ dàng. Các mô hình phi tuyến cổ điển thường giả định rằng mỗi cá thể chỉ có một quan sát và các cá thể hoàn toàn độc lập với nhau. Bạn có thể xem mô hình hỗn hợp phi tuyến là một sự mở rộng của mô hình phi tuyến cho trường hợp nhiều phép đo được thực hiện trên cùng một cá thể và các quan sát trong cùng một cá thể này thường có tính tương quan.
Bạn cũng có thể coi đây là dạng tổng quát hóa của mô hình hỗn hợp tuyến tính, trong đó một số hoặc tất cả các tác động ngẫu nhiên được đưa vào mô hình theo cách phi tuyến. Dù tiếp cận theo cách nào, các mô hình này đều được sử dụng để mô tả một biến phản hồi dưới dạng một hàm phi tuyến của các hiệp biến, đồng thời kiểm soát sự tương quan giữa các quan sát trên cùng một cá thể.
Khám phá dữ liệu tăng trưởng của cây
Chúng ta sẽ phân tích một bộ dữ liệu về chu vi thân của năm cây cam khác nhau. Dữ liệu này đo lường chu vi thân cây tính bằng milimet trong bảy thời điểm khác nhau, trải dài trong khoảng thời gian sinh trưởng chừng bốn năm. Mục tiêu là lập mô hình tăng trưởng của những cây cam này. Trước tiên, hãy vẽ biểu đồ dữ liệu để có cái nhìn trực quan.
1. webuse orange
2. twoway scatter circumf age, connect(L) ylabel(#6)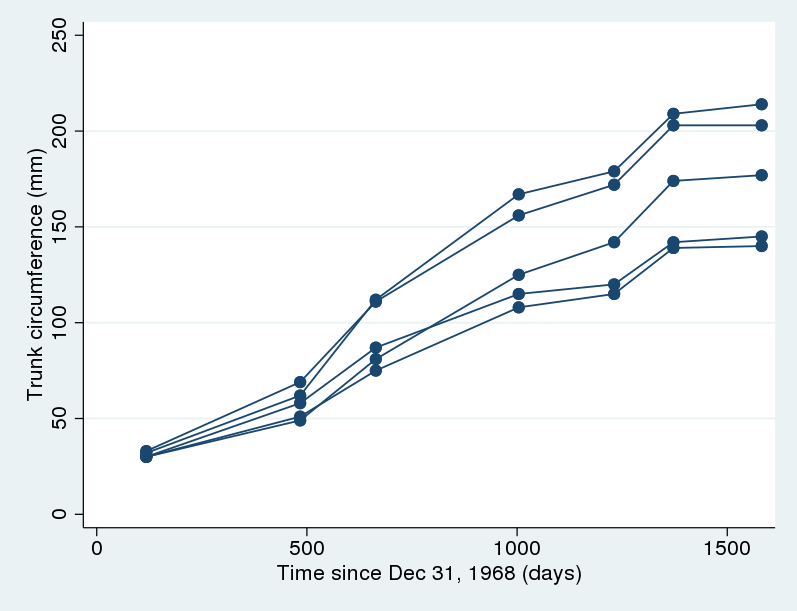
Biểu đồ cho thấy có sự biến thiên nhất định trong các đường cong sinh trưởng, nhưng nhìn chung cả năm cây đều có chung một hình dạng tổng thể. Cụ thể, mức độ tăng trưởng có xu hướng đi ngang về giai đoạn cuối. Từ dữ liệu này, một cấu trúc mô hình tăng trưởng phi tuyến đã được đề xuất dựa trên ba tham số chính.
Các tham số của mô hình hỗn hợp phi tuyến thường có ý nghĩa diễn giải khoa học rõ ràng và tạo thành nền tảng cho các câu hỏi nghiên cứu. Trong mô hình này, tham số phi 1 đại diện cho chu vi thân cây tiệm cận trung bình khi tuổi của cây tiến tới vô cực. Tham số phi 2 là độ tuổi trung bình mà tại đó cây đạt được một nửa chu vi thân cây tiệm cận hay còn gọi là chu kỳ bán sinh. Tham số phi 3 đóng vai trò là tham số tỷ lệ.
Phân tích mô hình bỏ qua sự tương quan
Bây giờ, hãy thử tạm thời bỏ qua những hậu quả của việc không kiểm soát sự tương quan và tính không đồng nhất tiềm ẩn giữa các quan sát, chẳng hạn như ước lượng độ không chắc chắn kém chính xác hơn hoặc các kiểm định giả thuyết yếu hơn. Thay vào đó, chúng ta sẽ coi tất cả các quan sát là phân phối độc lập và đồng nhất. Chúng ta sẽ sử dụng lệnh menl để khớp mô hình.
1. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3})), stddeviations
2Obtaining starting values:
3NLS algorithm:
4Iteration 0: residual SS = 17480.234
5Iteration 1: residual SS = 17480.234
6Computing standard errors:
7Mixed-effects ML nonlinear regression Number of obs = 35
8Log Likelihood = -158.39871
9------------------------------------------------------------------------------
10 circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
11-------------+----------------------------------------------------------------
12 /phi1 | 192.6876 20.24411 9.52 0.000 153.0099 232.3653
13 /phi2 | 728.7564 107.2984 6.79 0.000 518.4555 939.0573
14 /phi3 | 353.5337 81.47184 4.34 0.000 193.8518 513.2156
15------------------------------------------------------------------------------
16------------------------------------------------------------------------------
17 Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
18-----------------------------+------------------------------------------------
19 sd(Residual) | 22.34805 2.671102 17.68079 28.24734
20------------------------------------------------------------------------------Tùy chọn stddeviations yêu cầu lệnh menl báo cáo độ lệch chuẩn của sai số thay vì phương sai. Bởi vì chúng ta đang ép chung một đường cong sinh trưởng cho tất cả các cây, những khác biệt cá nhân thể hiện trong biểu đồ ban đầu đã bị dồn hết vào phần dư, từ đó làm tăng cao độ lệch chuẩn của phần dư.
Tích hợp tác động ngẫu nhiên vào mô hình
Thực tế là chúng ta có nhiều quan sát từ cùng một cái cây và chúng rất có thể tương quan với nhau. Một cách để giải quyết sự phụ thuộc này là thêm vào một tác động ngẫu nhiên u, được chia sẻ bởi tất cả các quan sát thuộc cùng một cây. Hãy xem kết quả khi chúng ta chạy mô hình này.
1. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3}))+{U[tree]}, stddev
2Obtaining starting values by EM:
3Alternating PNLS/LME algorithm:
4Iteration 1: linearization log likelihood = -147.631786
5Iteration 2: linearization log likelihood = -147.631786
6Computing standard errors:
7Mixed-effects ML nonlinear regression Number of obs = 35
8Group variable: tree Number of groups = 5
9 Obs per group:
10 min = 7
11 avg = 7.0
12 max = 7
13Linearization log likelihood = -147.63179
14------------------------------------------------------------------------------
15 circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
16-------------+----------------------------------------------------------------
17 /phi1 | 192.2526 17.06127 11.27 0.000 158.8131 225.6921
18 /phi2 | 729.3642 68.05493 10.72 0.000 595.979 862.7494
19 /phi3 | 352.405 58.25042 6.05 0.000 238.2363 466.5738
20------------------------------------------------------------------------------
21------------------------------------------------------------------------------
22 Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
23-----------------------------+------------------------------------------------
24tree: Identity |
25 sd(U) | 17.65093 6.065958 8.999985 34.61732
26-----------------------------+------------------------------------------------
27 sd(Residual) | 13.7099 1.76994 10.64497 17.65728
28------------------------------------------------------------------------------Các ước lượng tác động cố định tương tự nhau ở cả hai mô hình, nhưng sai số chuẩn của chúng lại nhỏ hơn trong mô hình thứ hai này. Độ lệch chuẩn của phần dư cũng nhỏ hơn vì một phần sự khác biệt giữa các cá thể đã được kiểm soát bởi tác động ngẫu nhiên. Việc thêm tác động ngẫu nhiên u vào mô hình ngụ ý rằng hiệp phương sai giữa hai quan sát bất kỳ trên cùng một cây là một giá trị lớn hơn không, và giá trị này thực chất bằng với phương sai của u. Do đó, tác động ngẫu nhiên tạo ra một sự tương quan dương giữa các quan sát trong cùng một nhóm.
Lựa chọn thay thế bằng cấu trúc hiệp phương sai
Vẫn còn một cách khác để xử lý sự tương quan giữa các quan sát trong cùng nhóm. Bạn có thể mô hình hóa trực tiếp cấu trúc hiệp phương sai của phần dư thông qua tùy chọn rescovariance() của lệnh menl. Khái niệm này liên quan đến mô hình biên phi tuyến có cấu trúc ma trận hiệp phương sai hoán đổi. Hai mô hình này sẽ tương đương nhau khi sự tương quan của các quan sát trong cùng nhóm mang giá trị dương.
1. menl circumf = {phi1}/(1+exp(-(age-{phi2})/{phi3})), rescovariance(exchangeable, group(tree)) stddev
2Obtaining starting values:
3Alternating GNLS/ML algorithm:
4Iteration 1: log likelihood = -147.632441
5Iteration 2: log likelihood = -147.631786
6Iteration 3: log likelihood = -147.631786
7Iteration 4: log likelihood = -147.631786
8Computing standard errors:
9Mixed-effects ML nonlinear regression Number of obs = 35
10Group variable: tree Number of groups = 5
11 Obs per group:
12 min = 7
13 avg = 7.0
14 max = 7
15Log Likelihood = -147.63179
16------------------------------------------------------------------------------
17 circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
18-------------+----------------------------------------------------------------
19 /phi1 | 192.2526 17.06127 11.27 0.000 158.8131 225.6921
20 /phi2 | 729.3642 68.05493 10.72 0.000 595.979 862.7494
21 /phi3 | 352.405 58.25042 6.05 0.000 238.2363 466.5738
22------------------------------------------------------------------------------
23------------------------------------------------------------------------------
24 Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
25-----------------------------+------------------------------------------------
26Residual: Exchangeable |
27 sd | 22.34987 4.87771 14.57155 34.28026
28 corr | .6237137 .1741451 .1707327 .8590478
29------------------------------------------------------------------------------Phần kết quả tác động cố định hoàn toàn giống nhau ở cả hai mô hình và ước lượng ma trận hiệp phương sai biên cũng vậy. Mặc dù tương đương nhau về mặt toán học, nhưng cách tiếp cận bằng cách đưa tác động ngẫu nhiên vào cho phép chúng ta không chỉ tính đến sự phụ thuộc của các phép đo mà còn ước lượng được sự biến thiên giữa các cây và dự đoán được đặc tính riêng của từng cây sau khi ước lượng.
Cấu hình tham số ngẫu nhiên cấp độ cá nhân
Hai mô hình trước ẩn chứa một giả định rằng đường cong tăng trưởng của tất cả các cây có cùng hình dạng và chỉ khác biệt ở một mức dịch chuyển theo trục dọc tương đương với giá trị u. Trong thực tế, giả định này có thể quá cứng nhắc. Nhìn lại biểu đồ dữ liệu, độ phân tán về chu vi của các cây càng lớn khi chúng càng tiến gần đến chiều cao giới hạn.
Vì vậy, sẽ hợp lý hơn nếu chúng ta cho phép tham số phi 1 biến thiên giữa các cây. Điều này cũng mang lại một diễn giải thú vị mang tính cá thể cho các tham số. Chúng ta giả định rằng tham số phi 1 bằng với tham số beta 1 cộng thêm tác động ngẫu nhiên u. Bạn có thể hiểu tham số beta 1 là chiều cao tiệm cận trung bình và u là độ lệch ngẫu nhiên so với mức trung bình đặc trưng cho từng cây cụ thể.
1. menl circumf = ({b1}+{U1[tree]})/(1+exp(-(age-{phi2})/{phi3}))
2Obtaining starting values by EM:
3Alternating PNLS/LME algorithm:
4Iteration 1: linearization log likelihood = -131.584579
5Computing standard errors:
6Mixed-effects ML nonlinear regression Number of obs = 35
7Group variable: tree Number of groups = 5
8 Obs per group:
9 min = 7
10 avg = 7.0
11 max = 7
12Linearization log likelihood = -131.58458
13------------------------------------------------------------------------------
14 circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
15-------------+----------------------------------------------------------------
16 /b1 | 191.049 16.15403 11.83 0.000 159.3877 222.7103
17 /phi2 | 722.556 35.15082 20.56 0.000 653.6616 791.4503
18 /phi3 | 344.1624 27.14739 12.68 0.000 290.9545 397.3703
19------------------------------------------------------------------------------
20------------------------------------------------------------------------------
21 Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
22-----------------------------+------------------------------------------------
23tree: Identity |
24 var(U1) | 991.1514 639.4636 279.8776 3510.038
25-----------------------------+------------------------------------------------
26 var(Residual) | 61.56371 15.89568 37.11466 102.1184
27------------------------------------------------------------------------------Nếu muốn đào sâu hơn, chúng ta còn có thể thiết lập thêm mô hình cấu trúc hiệp phương sai sai số bên trong cá thể bằng cách áp dụng cấu trúc hoán đổi.
1. menl circumf = ({b1}+{U1[tree]})/(1+exp(-(age-{phi2})/{phi3})), rescovariance(exchangeable)
2Obtaining starting values by EM:
3Alternating PNLS/LME algorithm:
4Iteration 1: linearization log likelihood = -131.468559
5Iteration 2: linearization log likelihood = -131.470388
6Iteration 3: linearization log likelihood = -131.470791
7Iteration 4: linearization log likelihood = -131.470813
8Iteration 5: linearization log likelihood = -131.470813
9Computing standard errors:
10Mixed-effects ML nonlinear regression Number of obs = 35
11Group variable: tree Number of groups = 5
12 Obs per group:
13 min = 7
14 avg = 7.0
15 max = 7
16Linearization log likelihood = -131.47081
17------------------------------------------------------------------------------
18 circumf | Coef. Std. Err. z P>|z| [95% Conf. Interval]
19-------------+----------------------------------------------------------------
20 /b1 | 191.2005 15.59015 12.26 0.000 160.6444 221.7566
21 /phi2 | 721.5232 35.66132 20.23 0.000 651.6283 791.4182
22 /phi3 | 344.3675 27.20839 12.66 0.000 291.0401 397.695
23------------------------------------------------------------------------------
24------------------------------------------------------------------------------
25 Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
26-----------------------------+------------------------------------------------
27tree: Identity |
28 var(U1) | 921.3895 582.735 266.7465 3182.641
29-----------------------------+------------------------------------------------
30Residual: Exchangeable |
31 var | 54.85736 14.16704 33.06817 91.00381
32 cov | -9.142893 2.378124 -13.80393 -4.481856
33------------------------------------------------------------------------------Ở đoạn mã trên, chúng ta không cần khai báo tùy chọn group() vì khi có sự hiện diện của các tác động ngẫu nhiên, hệ thống sẽ tự động xác định nhóm cấp thấp nhất dựa trên tác động ngẫu nhiên đã định nghĩa.
Mở rộng mô hình với cú pháp define
Các mô hình được sử dụng từ nãy đến giờ đều biểu diễn tác động ngẫu nhiên theo phương thức tuyến tính. Tuy nhiên, trong mô hình hỗn hợp phi tuyến, tác động ngẫu nhiên hoàn toàn có thể tham gia vào mô hình theo dạng phi tuyến giống hệt như các tác động cố định. Bên cạnh tham số phi 1, chúng ta có thể gán tác động ngẫu nhiên riêng cho các tham số khác.
1. menl circumf = {phi1:}/(1+exp(-(age-{phi2:})/{phi3:})), define(phi1:{b1}+{U1[tree]}) define(phi2:{b2}+{U2[tree]}) define(phi3:{b3}+{U3[tree]})Do số lượng quan sát thực tế chỉ có năm cây nên mô hình trên trở nên quá phức tạp đối với bộ dữ liệu này và chỉ mang mục đích minh họa cú pháp. Nhưng qua đó, bạn có thể thấy rằng tùy chọn define cực kỳ hữu dụng khi bạn đối mặt với một biểu thức phi tuyến cồng kềnh và muốn chia nhỏ nó ra cho dễ quản lý. Các tham số được khai báo bên trong define cũng có thể được dùng để chạy dự báo sau quá trình ước lượng. Ví dụ, bạn có thể tạo một biến mới dự báo mức chiều cao tiệm cận.
1. predict (phi1 = {phi1:})Trong trường hợp bộ dữ liệu lớn hơn với nhiều cây hơn, chúng ta còn có thể thiết lập thêm cấu trúc hiệp phương sai cho hàng loạt các tác động ngẫu nhiên này.
1. menl circumf = {phi1:}/(1+exp(-(age-{phi2:})/{phi3:})), define(phi1:{b1}+{U1[tree]}) define(phi2:{b2}+{U2[tree]}) define(phi3:{b3}+{U3[tree]}) covariance(U1 U2 U3, unstructured)Lệnh menl còn cung cấp khả năng tích hợp dữ liệu với các cấp độ phân cấp sâu hơn, chẳng hạn như cấu trúc ba cấp với các quan sát lặp lại nằm trong từng cây cá biệt, và các cây lại nằm trong từng khu vực trồng trọt khác nhau.
✨ Việc chuyển đổi từ mô hình phi tuyến tiêu chuẩn sang mô hình hỗn hợp phi tuyến giúp giải quyết triệt để bài toán tương quan dữ liệu nội bộ. Thông qua việc phân bổ sai số một cách thông minh vào các yếu tố ngẫu nhiên thay vì gom toàn bộ vào phần dư, phân tích của bạn sẽ bám sát thực tế hơn, mang lại các khoảng tin cậy hẹp và độ chính xác dự báo vượt trội.
Nếu dữ liệu bạn đang phân tích trong các lĩnh vực như y tế hoặc kinh tế cũng có cấu trúc đo lường lặp lại theo thời gian, bạn sẽ áp dụng cấu trúc tác động ngẫu nhiên cho tham số nào để phản ánh đúng bản chất sinh học hoặc hành vi của nhóm đối tượng mục tiêu?