Dữ liệu hiện diện ở khắp mọi nơi. Các cơ quan chính phủ, tổ chức tài chính, trường đại học và nền tảng mạng xã hội thường cung cấp quyền truy cập dữ liệu của họ thông qua API. Hệ thống này đóng vai trò như một cầu nối, thường trả về khối dữ liệu được yêu cầu dưới định dạng tệp JSON. Việc nắm vững cách sử dụng Python để gửi các truy vấn API và xử lý dữ liệu JSON thu được ngay bên trong môi trường Stata là một kỹ năng cực kỳ hữu ích cho quá trình phân tích dữ liệu hiện đại.
Khái quát về cấu trúc API và định dạng JSON
API là một phần mềm trung gian cho phép hệ thống của bạn yêu cầu dữ liệu từ một hệ thống máy tính khác. Cú pháp truy vấn thường mang tính đặc thù tùy thuộc vào từng hệ thống cung cấp, nhưng một cấu trúc điển hình luôn bắt đầu bằng một URL theo sau là các tùy chọn tham số. Bài viết này sẽ lấy ví dụ về việc sử dụng hệ thống openFDA để truy xuất dữ liệu về các biến cố bất lợi của thuốc từ Cục Quản lý Thực phẩm và Dược phẩm Hoa Kỳ.
Chúng ta hoàn toàn có thể thêm các điều kiện lọc vào lời gọi API để thu hẹp phạm vi dữ liệu trả về. Dữ liệu này hiển thị dưới dạng JSON, một định dạng lưu trữ phổ biến được cấu trúc bởi tập hợp các cặp khóa và giá trị. Khóa hoạt động tương tự như một biến số trong tập dữ liệu Stata, còn giá trị chính là dữ liệu thực tế được ghi nhận.
Điểm đặc trưng của JSON là dữ liệu thường được lồng ghép vào nhau thành nhiều tầng. Cấu trúc lồng ghép này đòi hỏi chúng ta phải có kỹ thuật bóc tách phù hợp. Mục tiêu cốt lõi là gọi dữ liệu từ openFDA, giải quyết cấu trúc lồng nhau này và chuyển đổi thành một tập dữ liệu Stata hoàn chỉnh thông qua hai thư viện là requests và pandas.
Khởi tạo và xây dựng địa chỉ truy vấn dữ liệu
Bước đầu tiên là xác định một chuỗi mang tên URL bên trong khối mã Python. Chuỗi này chứa đường dẫn cơ bản dùng để lấy dữ liệu. Thay vì viết một chuỗi truy vấn dài và phức tạp, việc chia nhỏ các thành phần sẽ giúp mã lệnh dễ kiểm soát hơn. Các biến chuỗi sẽ lần lượt đại diện cho ngày tháng, quốc gia và tên thuốc cần lọc. Quá trình nối chuỗi sẽ tạo ra một địa chỉ URL hoàn chỉnh.
1API = 'https://api.fda.gov/drug/event.json?search='
2date = 'receivedate:[20180101+TO+20180105]'
3country = 'occurcountry:"US"'
4drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
5data = 'count=receivedate'
6URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
7print(URL)Gửi yêu cầu truy xuất và định dạng kết quả
Khi địa chỉ truy vấn đã được xây dựng chính xác, bước tiếp theo là gửi yêu cầu đến máy chủ cung cấp dữ liệu. Hàm get từ thư viện requests sẽ thực thi việc truy cập URL và lưu trữ toàn bộ phản hồi JSON vào một đối tượng từ điển. Do dữ liệu thô ban đầu hiển thị dưới dạng một khối văn bản đặc rất khó đọc, mô đun json sẽ được sử dụng để tái định dạng lại.
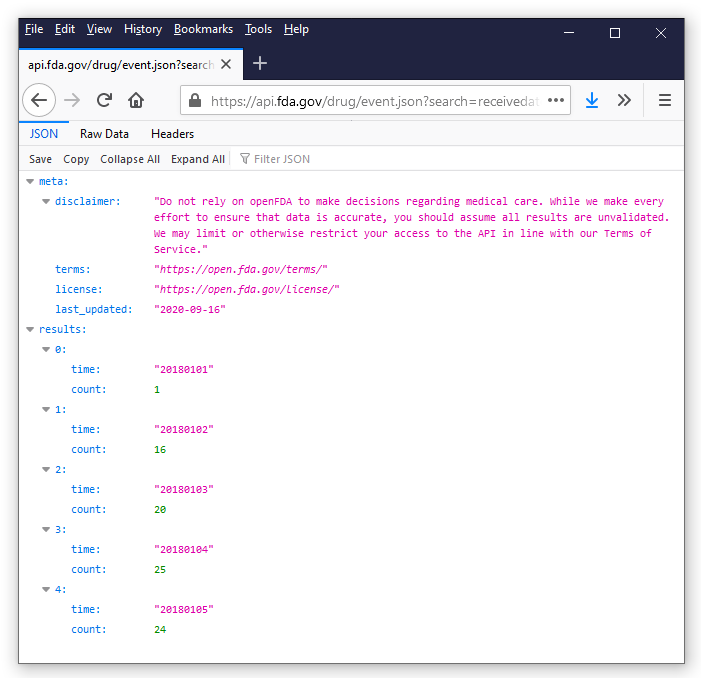
Bằng cách thiết lập thông số thụt đầu dòng, các cấp độ lồng nhau của khối dữ liệu hiện ra rõ ràng hơn. Chúng ta có thể thấy dữ liệu được chia thành hai nhóm khóa chính, trong đó khóa lưu trữ kết quả thực tế là phần thông tin trọng tâm cần trích xuất.
1import requests
2import json
3data = requests.get(URL).json()
4print(json.dumps(data, indent=4, sort_keys=True))Chuyển đổi dữ liệu JSON thành tập dữ liệu Stata
Dựa vào cấu trúc vừa phân tích, phương thức get sẽ tiến hành trích xuất riêng phần dữ liệu thuộc khóa kết quả và đặt chúng vào một đối tượng danh sách. Mặc dù đã được tách riêng, dữ liệu vẫn mang định dạng khóa và giá trị. Để biến đổi thành cấu trúc hàng và cột truyền thống, thư viện pandas sẽ can thiệp thông qua phương thức read_json, đưa toàn bộ danh sách này vào một data frame.
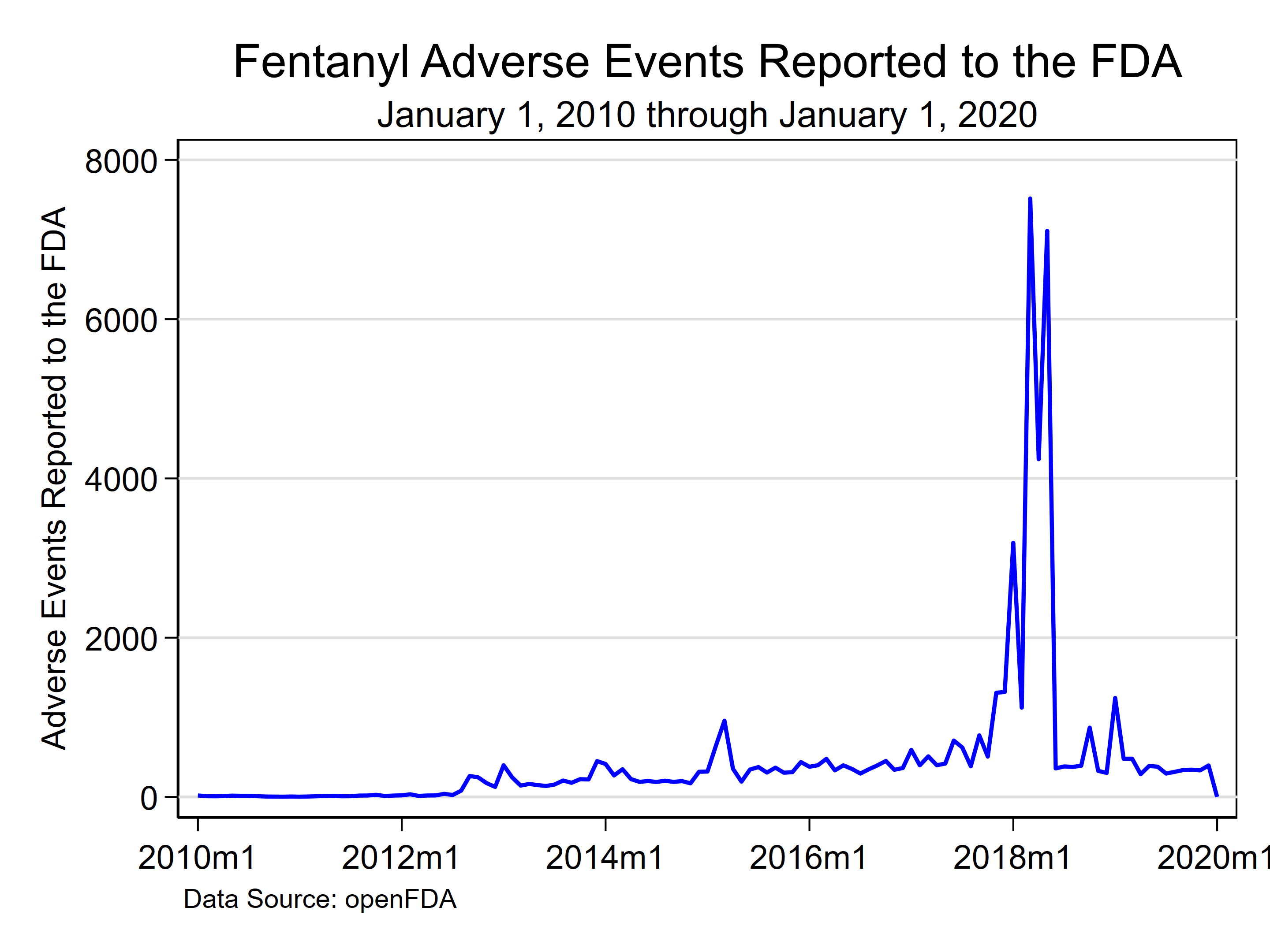
Khi data frame đã hình thành với các cột hiển thị thời gian và số lượng biến cố, phương thức to_stata thực hiện nhiệm vụ cuối cùng là xuất data frame này thành tệp Stata có đuôi mở rộng dta để tương thích với quy trình phân tích thống kê tiếp theo.
1import requests
2import json
3import pandas as pd
4API = 'https://api.fda.gov/drug/event.json?search='
5date = 'receivedate:[20100101+TO+20200101]'
6country = 'occurcountry:"US"'
7drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
8data = 'count=receivedate'
9URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
10data = requests.get(URL).json()
11fdadata = data.get('results', [])
12fda_df = pd.read_json(json.dumps(fdadata))
13fda_df.to_stata('fentanyl.dta', version=118)Sau khi tệp dữ liệu được lưu thành công trên ổ cứng, các mã lệnh Stata thuần túy có thể lập tức mở tệp, xử lý lại định dạng chuỗi thời gian cho chuẩn xác và tiến hành vẽ biểu đồ trực quan hóa xu hướng sự kiện.
1use fentanyl.dta, clear
2drop index
3generate date = mofd(date(string(time, "%8.0f"),"YMD"))
4format date %tm
5collapse (sum) count, by(date)
6tsset date, monthly✨ Khả năng kết hợp sức mạnh thu thập dữ liệu tự động của Python với nền tảng phân tích thống kê chuyên sâu của Stata mang lại một quy trình làm việc hoàn toàn liền mạch. Người làm khoa học dữ liệu không còn phải chuyển đổi thủ công qua lại giữa các phần mềm, từ đó giảm thiểu sai sót và tối ưu hóa thời gian từ bước thu thập thô đến bước trực quan hóa cuối cùng.
Cấu trúc lồng ghép của định dạng JSON đôi khi không chỉ dừng lại ở một hoặc hai cấp độ mà có thể chứa các danh sách phức tạp nằm sâu bên trong. Theo bạn, khi đối mặt với một phản hồi API chứa các mảng dữ liệu lồng nhau đan xen không đồng nhất, phương pháp nào trong thư viện pandas là tối ưu nhất để làm phẳng toàn bộ cấu trúc này trước khi xuất sang tệp thống kê?