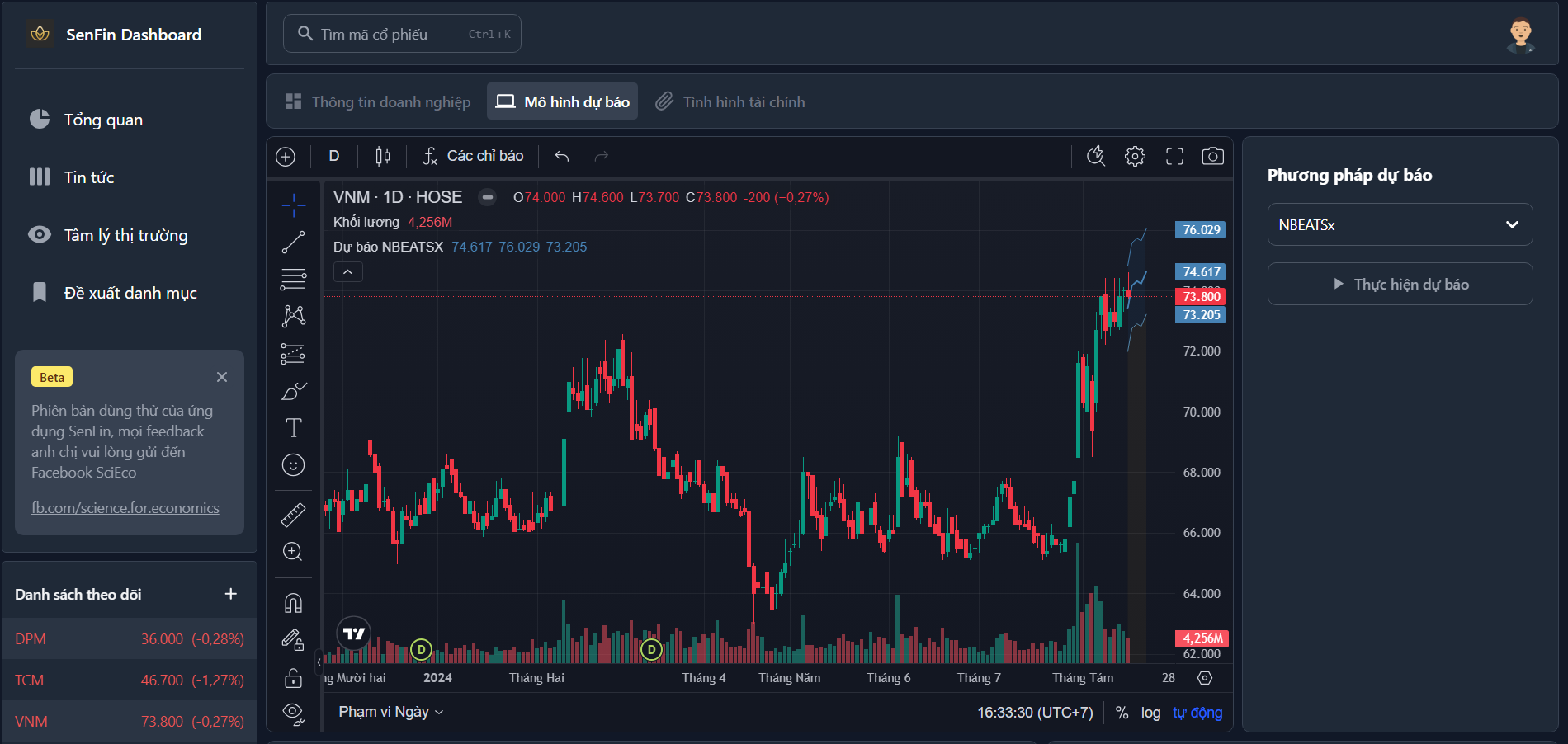
Điều Gì Làm Nên Sự Độc Đáo của Advanced Chart của TradingView?
- Advanced Chart của TradingView đã nhanh chóng trở thành một trong những công cụ phân tích thị trường phổ biến nhất trên toàn cầu, và lợi ích của công cụ này ngày càng được công nhận. Với việc tích hợp thành công trên nền tảng giao dịch của TVS, nhà đầu tư sẽ được trải nghiệm những ưu điểm nổi bật sau:
- Giao Diện Người Dùng Thân Thiện: Advanced Chart của TradingView có một giao diện người dùng dễ sử dụng, linh hoạt và tương tác. Các công cụ và chức năng được sắp xếp một cách rõ ràng, giúp người dùng dễ dàng tìm thấy và sử dụng các tính năng một cách hiệu quả trên nền tảng giao dịch của TVS.
- Biểu Đồ Tương Tác Mạnh Mẽ: Những biểu đồ linh hoạt cho phép nhà đầu tư thay đổi khung thời gian, vẽ đường hỗ trợ và kháng cự, tạo ra các phạm vi Fibonacci và thực hiện nhiều thao tác phân tích kỹ thuật khác. Tính năng này giúp nhà đầu tư dễ dàng xác định xu hướng và các điểm mua/bán tiềm năng trên biểu đồ.
- Chỉ Báo và Công Cụ Phân Tích Kỹ Thuật Đa Dạng: Advanced Chart hỗ trợ nhiều chỉ báo kỹ thuật phong phú và đa dạng, giúp nhà đầu tư phân tích xu hướng, đánh giá sức mạnh thị trường và xác định điểm mua/bán tiềm năng một cách chính xác.
- Tùy Chỉnh và Lưu Trữ Biểu Đồ: Nhà đầu tư có thể tùy chỉnh biểu đồ và các cài đặt hiển thị theo ý muốn, có thể lưu trữ và quản lý nhiều biểu đồ và mẫu, giúp tiết kiệm thời gian và nỗ lực trong việc quản lý các phân tích và chiến lược giao dịch.
Lợi Ích Cho Nhà Đầu Tư trên Nền Tảng SenFin:
- Trải Nghiệm Giao Dịch Hiện Đại: Sự kết hợp giữa SenFin và TradingView mang lại trải nghiệm hiện đại và linh hoạt nhất cho nhà đầu tư trên thị trường chứng khoán.
- Quyết Định Giao Dịch Thông Minh: Advanced Chart kết hợp cùng với các công cụ phân tích mạnh mẽ khác tới từ TradingView như lịch kinh tế, bộ lọc cổ phiếu và các chỉ báo của SciEco giúp nhà đầu tư đưa ra các quyết định giao dịch thông minh dựa trên phân tích thị trường chi tiết và chính xác.
- Truy cập Nhanh Chóng và Thuận Tiện: Nhà đầu tư có thể truy cập Advanced Chart một cách thuận tiện trực tiếp từ nền tảng SciEco mà không cần chuyển đổi giữa các ứng dụng khác nhau.

