Trong quá trình phân tích dữ liệu, chúng ta thường phải tạo ra rất nhiều bảng kết quả hồi quy với cùng một định dạng và nhãn dán lặp đi lặp lại. Thay vì phải định dạng lại từ đầu cho mỗi bảng báo cáo, Stata cung cấp một giải pháp hiệu quả giúp bạn lưu lại toàn bộ cấu trúc trình bày để tái sử dụng về sau. Bài viết này sẽ hướng dẫn cách lưu các thiết lập định dạng bảng và áp dụng chúng cho những dự án phân tích dữ liệu trong tương lai.
Tạo bảng kết quả cơ bản
Chúng ta sẽ bắt đầu bằng việc mở tập dữ liệu thông qua lệnh webuse nhanes2l. Sau đó, chúng ta dùng lệnh table để tạo một bảng cơ bản cho mô hình hồi quy logistic với biến phụ thuộc nhị phân là highbp. Bảng này sẽ bao gồm tỷ số chênh, sai số chuẩn, thống kê z, p-value và khoảng tin cậy. Lưu ý rằng ký hiệu biến phân loại của Stata được sử dụng để đưa vào hiệu ứng chính của biến liên tục age, hiệu ứng chính của các biến phân loại sex và diabetes, cùng với sự tương tác giữa age và sex.
1. webuse nhanes2l
2(Second National Health and Nutrition Examination Survey)
3. table () (command result),
4> command(_r_b _r_se _r_z _r_p _r_ci
5> : logistic highbp c.age##i.sex i.diabetes)
6--------------------------------------------------------------------------------------------------
7 | logistic highbp c.age##i.sex i.diabetes
8 | Coefficient Std. error z p-value 95% CI
9-----------------------------+--------------------------------------------------------------------
10Age (years) | 1.034281 .0018566 18.78 0.000 1.030648 1.037926
11Sex=Male | 1 0
12Sex=Female | .1549363 .0223461 -12.93 0.000 .1167849 .2055511
13Sex=Male # Age (years) | 1 0
14Sex=Female # Age (years) | 1.028856 .0027958 10.47 0.000 1.023391 1.034351
15Diabetes status=Not diabetic | 1 0
16Diabetes status=Diabetic | 1.521011 .154103 4.14 0.000 1.247073 1.855124
17Intercept | .1730928 .0157789 -19.24 0.000 .144772 .2069537
18--------------------------------------------------------------------------------------------------Tạo và lưu phong cách trình bày tùy chỉnh
Trước tiên, hãy dọn dẹp bộ nhớ tạm của Stata bằng lệnh collect clear.
1. collect clearTiếp theo, chúng ta áp dụng các lệnh định dạng để làm sạch bảng dữ liệu. Các chú thích trong đoạn mã dưới đây sẽ giải thích chức năng của từng dòng lệnh, từ việc tắt các mức cơ sở của biến phân loại, gộp nhãn, xóa đường kẻ dọc cho đến định dạng lại các con số thập phân.
1// Tat muc co so cho cac bien phan loai
2collect style showbase off
3// Gop cac nhan hang va thay doi dau phan cach tuong tac
4collect style row stack, delimiter(" x ") nobinder
5// Xoa duong ke doc
6collect style cell border_block, border(right, pattern(nil))
7// Dinh dang cac con so
8collect style cell result[_r_b _r_se _r_ci], nformat(%8.2f)
9collect style cell result[_r_p], nformat(%5.4f)
10collect style cell result[_r_ci], sformat("[%s]") cidelimiter(,)
11// An lenh hoi quy logistic
12collect style header command, level(hide)Cuối cùng, sử dụng lệnh collect style save để lưu toàn bộ phong cách này vào một tệp tin mang tên MyLogitStyle.stjson.
1. collect style save MyLogitStyle, replace
2(style from mylogit saved to file MyLogitStyle.stjson)Tạo và lưu nhãn tùy chỉnh
Bên cạnh phong cách trình bày, việc tùy chỉnh nhãn dán cũng rất quan trọng. Các hệ số trong kết quả hồi quy logistic thực chất là các tỷ số chênh. Chúng ta sẽ thay đổi nhãn hiển thị từ Coefficient thành Odds Ratio.
1collect label levels result _r_b "Odds Ratio", modifyTương tự như trên, chúng ta lưu thiết lập nhãn này thành một tệp tin tên là MyLogitLabels.stjson.
1. collect label save MyLogitLabels, replace
2(labels from mylogit saved to file MyLogitLabels.stjson)Ứng dụng phong cách và nhãn đã lưu
Khi tạo một bảng mới, bạn có thể gọi lại ngay các định dạng vừa lưu bằng cách thêm tùy chọn style và label. Nếu bạn đang làm việc trong cùng thư mục lưu tệp, chỉ cần gõ tên tệp. Nếu ở thư mục khác, bạn cần cung cấp đường dẫn đầy đủ.
1. table () (command result),
2> command(_r_b _r_se _r_z _r_p _r_ci
3> : logistic highbp c.age##i.sex i.diabetes)
4> style(c:\MyFolder\MyLogitStyle.stjson, override)
5> label(c:\MyFolder\MyLogitLabels.stjson)
6-------------------------------------------------------------------------------
7 Odds Ratio Std. error z p-value 95% CI
8-------------------------------------------------------------------------------
9Age (years) 1.03 0.00 18.78 0.0000 [1.03, 1.04]
10Sex
11 Female 0.15 0.02 -12.93 0.0000 [0.12, 0.21]
12Sex x Age (years)
13 Female 1.03 0.00 10.47 0.0000 [1.02, 1.03]
14Diabetes status
15 Diabetic 1.52 0.15 4.14 0.0000 [1.25, 1.86]
16Intercept 0.17 0.02 -19.24 0.0000 [0.14, 0.21]
17-------------------------------------------------------------------------------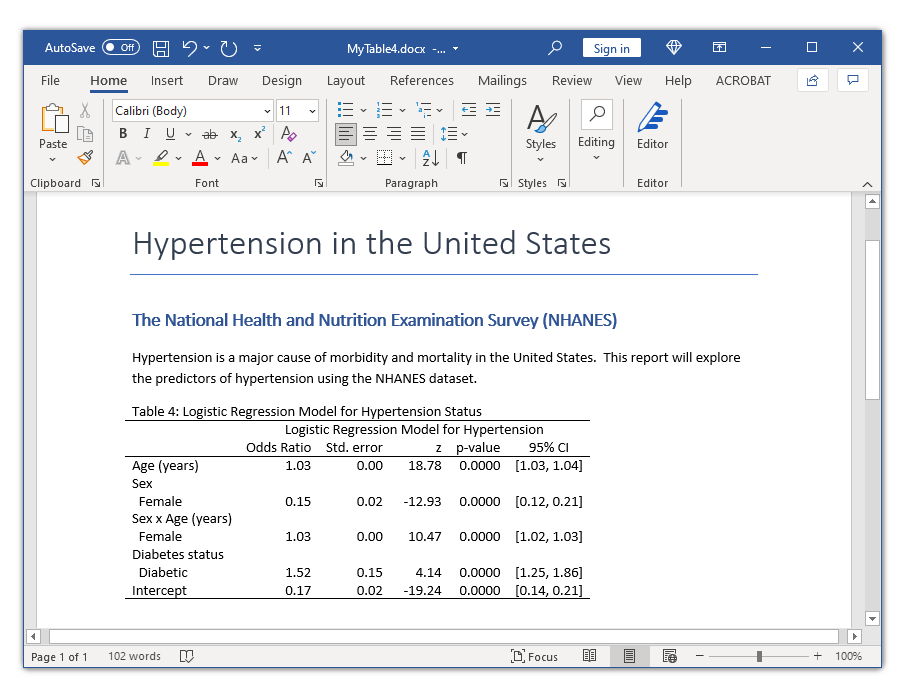
Lưu vào thư mục cá nhân để dùng mọi lúc
Cách tối ưu nhất là lưu các tệp định dạng này vào thư mục cá nhân của hệ thống để có thể gọi ra sử dụng bất cứ lúc nào mà không cần nhớ đường dẫn. Gõ lệnh sysdir để xác định vị trí thư mục cá nhân trên máy tính của bạn.
1. sysdir
2 STATA: C:\Program Files\Stata17\
3 BASE: C:\Program Files\Stata17\ado\base\
4 SITE: C:\Program Files\Stata17\ado\site\
5 PLUS: C:\Users\ChuckStata\ado\plus\
6PERSONAL: c:\ado\personal\
7OLDPLACE: c:\ado\Sau khi biết thư mục đích, bạn lưu trực tiếp tệp stjson vào đó.
1. collect style save "c:\ado\personal\MyLogitStyle", replace
2(style from mylogit saved to file c:\ado\personal\MyLogitStyle.stjson)
3. collect label save "c:\ado\personal\MyLogitLabels", replace
4(labels from mylogit saved to file c:\ado\personal\MyLogitLabels.stjson)Áp dụng định dạng cho các bảng dữ liệu khác
Hãy thử nghiệm phong cách trình bày này với một tập dữ liệu hoàn toàn khác. Chúng ta sẽ mở dữ liệu nghiên cứu về trẻ sơ sinh nhẹ cân và chạy mô hình dự đoán khả năng sinh con dưới 2500 gram.
1. webuse lbw, clear
2(Hosmer & Lemeshow data)
3. describe low age smoke ht
4Variable Storage Display Value
5 name type format label Variable label
6------------------------------------------------------------------------------------------------------------------------
7low byte %8.0g Birthweight<2500g
8age byte %8.0g Age of mother
9smoke byte %9.0g smoke Smoked during pregnancy
10ht byte %8.0g Has history of hypertensionKhi tạo bảng kết quả, chúng ta lại tiếp tục gọi phong cách MyLogitStyle và nhãn MyLogitLabels.
1. table () (command result),
2> command(_r_b _r_se _r_z _r_p _r_ci
3> : logistic low c.age##i.smoke ht)
4> style(MyLogitStyle, override)
5> label(MyLogitLabels)
6----------------------------------------------------------------------------------------------------
7 Odds Ratio Std. error z p-value 95% CI
8----------------------------------------------------------------------------------------------------
9Age of mother 0.92 0.04 -1.85 0.0646 [0.84, 1.01]
10Smoked during pregnancy
11 Smoker 0.36 0.56 -0.66 0.5082 [0.02, 7.37]
12Smoked during pregnancy x Age of mother
13 Smoker 1.08 0.07 1.14 0.2542 [0.95, 1.23]
14Has history of hypertension 3.47 2.15 2.00 0.0456 [1.02, 11.72]
15Intercept 2.16 2.27 0.73 0.4642 [0.28, 16.90]
16----------------------------------------------------------------------------------------------------Định dạng tổng thể của bảng đã hoàn hảo như mong đợi, tuy nhiên tên của các biến số đang quá dài. Chúng ta có thể kiểm tra danh sách nhãn cột và rút gọn chúng lại để bảng trông sắc nét hơn.
1. collect label list colname, all
2 Collection: Table
3 Dimension: colname
4 Label: Covariate names and column names
5Level labels:
6 _cons Intercept
7 _hide
8 age Age of mother
9 c1
10 c2
11 c3
12 c4
13 ht Has history of hypertension
14 smoke Smoked during pregnancySử dụng lệnh modify để tinh chỉnh lại tên biến số cho ngắn gọn.
1. collect label levels colname age "Age", modify
2. collect label levels colname ht "Hypertension", modify
3. collect label levels colname smoke "Smoke", modifyKiểm tra lại thành quả cuối cùng bằng lệnh preview.
1. collect preview
2-------------------------------------------------------------------------
3 Odds Ratio Std. error z p-value 95% CI
4-------------------------------------------------------------------------
5Age 0.92 0.04 -1.85 0.0646 [0.84, 1.01]
6Smoke
7 Smoker 0.36 0.56 -0.66 0.5082 [0.02, 7.37]
8Smoke x Age
9 Smoker 1.08 0.07 1.14 0.2542 [0.95, 1.23]
10Hypertension 3.47 2.15 2.00 0.0456 [1.02, 11.72]
11Intercept 2.16 2.27 0.73 0.4642 [0.28, 16.90]
12-------------------------------------------------------------------------✨ Khả năng lưu và tái sử dụng các phong cách tùy chỉnh cho phép bạn tối ưu hóa hoàn toàn quy trình tạo báo cáo. Dù bạn là nhà nghiên cứu cần định dạng bảng theo tiêu chuẩn khắt khe của các tạp chí khoa học, hay chuyên viên phân tích dữ liệu cần tạo báo cáo định kỳ cho doanh nghiệp, việc đầu tư thời gian xây dựng chuẩn trình bày một lần sẽ mang lại lợi tức khổng lồ về mặt thời gian cho các dự án sau này.
Hãy thử mở một tập dữ liệu bất kỳ mà bạn đang thực hiện phân tích, chạy một mô hình hồi quy đa biến và tự tay thiết lập một phong cách định dạng chuẩn theo đúng yêu cầu từ trường học hoặc công ty của bạn. Bạn lưu trữ tệp định dạng này vào thư mục nào để đảm bảo tính sẵn sàng cao nhất cho những lần chạy mô hình tiếp theo?

