Lệnh margins là một công cụ mạnh mẽ trong phần mềm Stata giúp chúng ta tính toán các giá trị dự báo, sai số cận biên và tác động cận biên. Điểm đặc biệt là lệnh này có thể xử lý hầu như mọi dạng hàm của các tham số ước lượng thông qua tùy chọn expression. Bài viết này sẽ hướng dẫn bạn cách xác định mức thay đổi tỷ lệ của biến kết quả khi các biến độc lập thay đổi, sử dụng cả hai phương pháp cho mô hình tuyến tính và phi tuyến tính.
Mô hình tuyến tính với biến nhị phân
Sau khi ước lượng một mô hình hồi quy tuyến tính với kỳ vọng của y khi biết x bằng a cộng b nhân x, chúng ta có thể ước lượng mức thay đổi tỷ lệ của các giá trị dự báo đối với sự thay đổi của x, hay còn gọi là bán co giãn, bằng lệnh margins kèm tùy chọn eydx. Công thức tính bán co giãn sẽ khác nhau tùy thuộc vào việc x là biến liên tục hay biến rời rạc.
Nếu x là biến liên tục, trị số eydx được tính bằng đạo hàm của logarith tự nhiên của y dự báo theo x, bằng đạo hàm của y theo x nhân với một phần y dự báo, và bằng hệ số b chia cho y dự báo.
Khi x là biến rời rạc, về mặt cảm tính chúng ta thường nghĩ công thức sẽ là hiệu số giữa kỳ vọng của y dự báo khi x bằng một và kỳ vọng của y dự báo khi x bằng không, tất cả chia cho kỳ vọng của y dự báo khi x bằng không.
Tuy nhiên, đây không phải là những gì lệnh margins với tùy chọn eydx tính toán. Thay vào đó, margins tính toán sự khác biệt của y dự báo so với mốc cơ sở dưới dạng logarith tự nhiên, cụ thể là kỳ vọng của logarith tự nhiên của y dự báo khi x bằng một trừ đi kỳ vọng của logarith tự nhiên của y dự báo khi x bằng không.
Chúng ta hãy cùng xem xét một ví dụ thực tế bằng cách ước lượng mô hình với một biến liên tục và một biến nhị phân.
1webuse lbw, clear
2quietly regress bwt age i.ui
3margins, eydx(age ui)Chúng ta đã thực hiện hồi quy trọng lượng sơ sinh của trẻ sơ sinh theo tuổi của mẹ là biến liên tục và tình trạng kích thích tử cung là biến nhị phân ui, sau đó tính toán bán co giãn. Chúng ta có thể tự tính toán thủ công các mức thay đổi tỷ lệ này. Mức thay đổi tỷ lệ của giá trị dự báo bwt đối với sự thay đổi của tuổi mẹ được tính bằng hệ số của biến tuổi chia cho giá trị dự báo bwt.
1generate propage = _b[age]/(_b[_cons] + _b[age]*age + _b[1.ui]*ui)
2summarize propageGiá trị trung bình nhận được là 0.003225, hoàn toàn trùng khớp với kết quả bán co giãn mà margins báo cáo.
Bây giờ, chúng ta chuyển sang biến ui. Mức thay đổi tỷ lệ của bwt đối với sự thay đổi của ui theo công thức tỷ lệ thông thường là hiệu số dự báo bwt giữa nhóm ui bằng một và nhóm ui bằng không, chia cho dự báo bwt của nhóm ui bằng không.
1preserve
2replace ui = 0
3predict bwhat0
4replace ui = 1
5predict bwhat1
6generate propui = (bwhat1 - bwhat0)/bwhat0
7summarize propuiLần này, giá trị trung bình âm 0.187989 không trùng khớp với kết quả bán co giãn do margins báo cáo là âm 0.2082485. Như đã giải thích, lệnh margins với tùy chọn eydx không sử dụng công thức tỷ lệ thông thường mà thay thế bằng mức chênh lệch logarith tự nhiên. Chúng ta có thể kiểm chứng điều này:
1generate lnbwt0 = ln(bwhat0)
2generate lnbwt1 = ln(bwhat1)
3generate propui2 = lnbwt1 - lnbwt0
4summarize propui2
5restoreLệnh margins với tùy chọn eydx sử dụng phương pháp dựa trên logarith vì phương pháp này có các đặc tính số học tốt hơn. Ngoài ra, nếu chúng ta có một mô hình với logarith tự nhiên của y ở vế trái, việc biểu diễn đạo hàm đối với biến phân loại dưới dạng sai lệch so với nhóm cơ sở là cách phổ biến để tính toán mức thay đổi tỷ lệ.
Nếu muốn có được mức thay đổi tỷ lệ theo công thức thông thường kèm theo sai số chuẩn tương ứng, chúng ta có thể thực hiện thông qua tùy chọn expression trong lệnh margins.
1margins, expression(_b[1.ui]/(_b[_cons] + _b[age]*age))Trong tùy chọn expression, mẫu số là giá trị dự báo bwt khi ui bằng không, và tử số là chênh lệch dự báo bwt giữa khi ui bằng một và khi ui bằng không. Dòng cảnh báo xuất hiện vì tùy chọn expression không chứa predict hoặc xb, nhưng trong trường hợp này chúng ta hoàn toàn có thể bỏ qua cảnh báo này.
Mô hình tuyến tính với biến phân loại nhiều nhóm
Biến ui là biến nhị phân với hai giá trị không và một. Vậy nếu chúng ta có một biến phân loại với nhiều hơn hai nhóm thì sao? Làm thế nào chúng ta có thể dùng tùy chọn expression để tính mức thay đổi tỷ lệ? Chúng ta muốn tìm mức thay đổi tỷ lệ trong kết quả dự báo khi biến phân loại thay đổi từ nhóm cơ sở sang các nhóm còn lại. Hãy thử nghiệm với biến chủng tộc race có ba nhóm bao gồm da trắng là nhóm một, da đen là nhóm hai và nhóm khác là nhóm ba.
1quietly regress bwt age i.race
2generate double propblack = _b[2.race]/(_b[_cons] + _b[age]*age)
3generate double propother = _b[3.race]/(_b[_cons] + _b[age]*age)
4summarize propblack propother
5margins, expression((_b[2.race]*2.race + _b[3.race]*3.race)/(_b[_cons]+_b[age]*age)) dydx(race)Kết quả tính toán thủ công hoàn toàn khớp với những gì margins báo cáo. Ở đây chúng ta đã kết hợp cả tùy chọn expression và dydx. Sau khi lấy đạo hàm của biểu thức trong expression theo từng nhóm của race, chúng ta thu được các biểu thức thay đổi tỷ lệ tương ứng cho các bà mẹ da đen và các bà mẹ thuộc chủng tộc khác so với nhóm cơ sở là mẹ da trắng.
Việc gộp chung các nhóm vào một biểu thức duy nhất giúp chúng ta có thể ước lượng đồng thời cả hai giá trị cùng với hiệp phương sai của chúng, từ đó dễ dàng thực hiện các kiểm định so sánh sự khác biệt giữa các mức thay đổi tỷ lệ này.
Áp dụng cho các mô hình phi tuyến tính
Phương pháp này có thể được mở rộng cho các mô hình phi tuyến tính, sự khác biệt lớn nhất nằm ở hàm liên kết được sử dụng để tính toán giá trị dự báo. Trong ví dụ tiếp theo, chúng ta sẽ sử dụng mô hình hồi quy probit và hồi quy Poisson.
Đầu tiên là mô hình probit ước lượng xác suất sinh con nhẹ cân dựa trên tuổi và chủng tộc của người mẹ:
1quietly probit low age i.race
2margins, expression((normal(_b[_cons] + _b[age]*age + _b[2.race]*2.race + _b[3.race]*3.race) - normal(_b[_cons] + _b[age]*age))/normal(_b[_cons] + _b[age]*age)) dydx(race)Tiếp theo là mô hình Poisson ước lượng số ca tử vong dựa trên tình trạng hút thuốc và nhóm tuổi, sử dụng pyears làm biến phơi nhiễm:
1webuse dollhill3, clear
2quietly poisson deaths smokes i.agecat, exposure(pyears)
3margins, expression((exp(_b[smokes]*smokes + _b[2.agecat]*2.agecat + _b[3.agecat]*3.agecat + _b[4.agecat]*4.agecat + _b[5.agecat]*5.agecat + _ b[_cons])*pyears - exp(_b[smokes]*smokes + _ b[_cons])*pyears)/(exp(_b[smokes]*smokes + _ b[_cons])*pyears)) dydx(agecat)Lệnh margins hoạt động dựa trên các giá trị dự báo cận biên của biến kết quả, trong đó giá trị dự báo bằng xb đối với hồi quy tuyến tính, bằng hàm phân phối tích lũy chuẩn normal(xb) đối với hồi quy probit, và bằng exp(xb) nhân với biến phơi nhiễm đối với hồi quy Poisson.
Các cú pháp viết tắt hữu ích trong tùy chọn expression
Các dạng hàm được đưa vào tùy chọn expression của lệnh margins có thể tùy biến linh hoạt và phức tạp tùy theo nhu cầu của bạn. Dưới đây là một số cách viết tắt giúp đơn giản hóa câu lệnh. Hãy quay lại với mô hình probit có tương tác chéo giữa tuổi và chủng tộc.
1quietly probit low c.age##i.race
2margins, eydx(age)Thay vì phải viết toàn bộ phương trình dài dòng cho đạo hàm, chúng ta có thể sử dụng cú pháp rút gọn predict(xb) để đại diện cho phần dự báo tuyến tính:
1margins, expression((_b[age] + _b[2.race#c.age]*2.race + _b[3.race#c.age]*3.race)*normalden(predict(xb))/normal(predict(xb)))Hơn thế nữa, biểu thức normal(predict(xb)) có thể được thay thế bằng predict(pr), đại diện cho xác suất của kết quả xảy ra. Tùy chọn expression cho phép chúng ta xây dựng bất kỳ hàm số nào của các tham số ước lượng và đưa chúng vào margins để tận dụng toàn bộ sức mạnh tính toán cũng như các công cụ trực quan hóa như lệnh marginsplot.
1quietly margins r.race, expression((_b[age] + _b[2.race#c.age]*2.race + _b[3.race#c.age]*3.race)*normalden(predict(xb))/normal(predict(xb))) at(age=(14(5)50))
2quietly marginsplot, noci ytitle("expression in -margins-")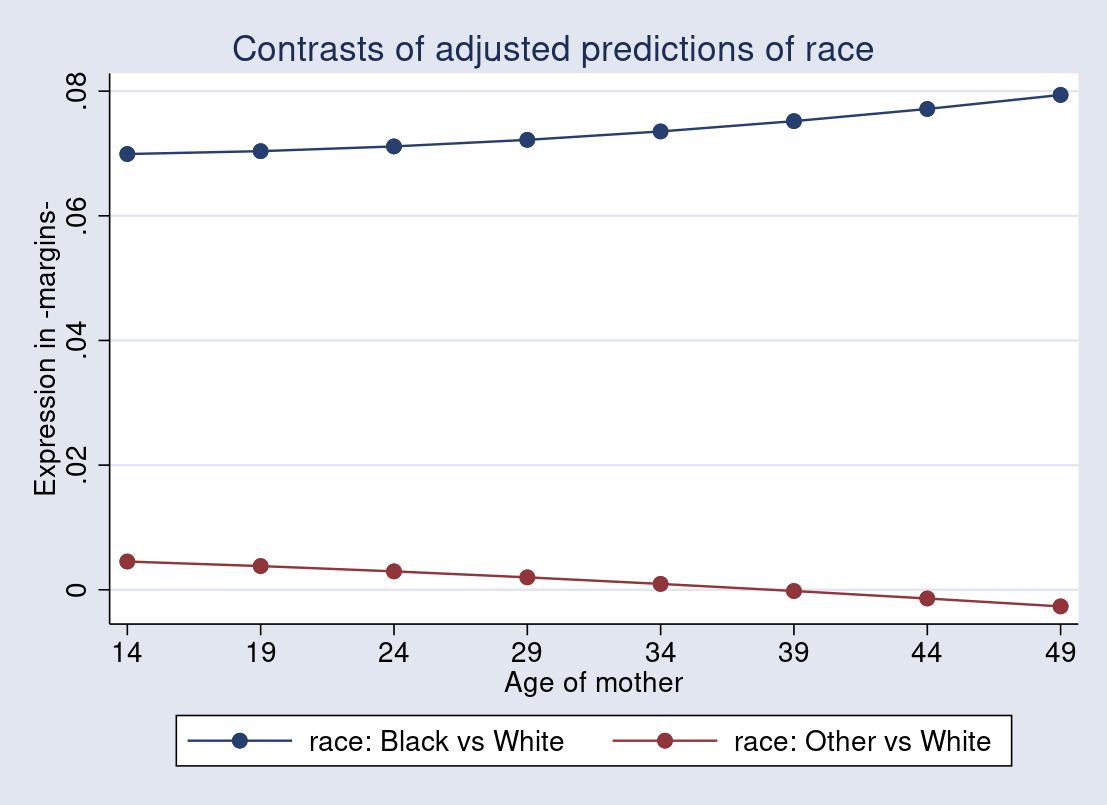
Biểu đồ trên trực quan hóa sự khác biệt về mức thay đổi tỷ lệ trong xác suất sinh con nhẹ cân theo độ tuổi của mẹ giữa các nhóm chủng tộc. Xu hướng phân kỳ nhẹ cho thấy hiệu ứng tương tác nơi yếu tố chủng tộc điều phối mối quan hệ giữa độ tuổi của mẹ và xác suất sinh con nhẹ cân.
Kết luận
Qua bài viết này, chúng ta đã học cách sử dụng tùy chọn expression của lệnh margins trong Stata để tính toán các mức thay đổi tỷ lệ của biến kết quả đối với sự thay đổi của các biến độc lập phân loại trong cả mô hình tuyến tính và phi tuyến tính. Tùy chọn expression là một công cụ cực kỳ linh hoạt, cho phép định hình bất kỳ dạng hàm nào của các tham số ước lượng để thực hiện phân tích cận biên sâu sắc hơn.
✨ Việc nắm vững tùy chọn expression trong lệnh margins giúp bạn vượt qua giới hạn của các công thức mặc định trong Stata. Thay vì bị bó buộc vào các ước lượng bán co giãn dạng log của eydx, bạn hoàn toàn có thể chủ động thiết lập các công thức tính tỷ lệ phần trăm thay đổi thực tế cho bất kỳ mô hình phức tạp nào, giúp báo cáo nghiên cứu trở nên trực quan và chính xác hơn với thực tế kinh tế xã hội.
Trong các mô hình phi tuyến tính như logistic hoặc probit, khi nào việc sử dụng xấp xỉ logarith thông thường thông qua eydx sẽ cho kết quả gần tương đương với công thức thay đổi tỷ lệ thực tế? Hãy thử áp dụng tùy chọn expression để tính toán mức thay đổi tỷ lệ cho một mô hình hồi quy logit sử dụng bộ dữ liệu của riêng bạn và so sánh sai số giữa hai phương pháp này.

