R-vine copulas là một công cụ phân tích mạnh mẽ giúp mô hình hóa sự phụ thuộc phức tạp giữa nhiều biến số trong một tập dữ liệu. Việc tạo ra dữ liệu tổng hợp nhằm phục vụ cho kiểm thử mô hình hoặc chia sẻ thông tin mà không làm lộ dữ liệu nhạy cảm đang trở thành một nhu cầu thiết yếu. Gói esgtoolkit trong R cung cấp một giao diện trực quan và tối ưu để huấn luyện các mô hình R-vine copula, đồng thời mô phỏng sinh ra dữ liệu mới bảo toàn chặt chẽ các đặc tính thống kê của dữ liệu gốc.
Chuẩn bị môi trường và dữ liệu đầu vào
Để bắt đầu, chúng ta cần cài đặt gói esgtoolkit từ kho lưu trữ. Trong bài viết này, tập dữ liệu chuỗi thời gian EuStockMarkets bao gồm các chỉ số chứng khoán châu Âu như DAX, SMI, CAC và FTSE sẽ được sử dụng làm minh họa. Dữ liệu này được chuyển đổi sang dạng tỷ suất sinh lợi logarit thông qua hàm có sẵn của gói.
1devtools::install_github("Techtonique/esgtoolkit")
2library(esgtoolkit)
3y <- esgtoolkit::calculatereturns(ts(EuStockMarkets[1:250, ], start=start(EuStockMarkets), frequency=frequency(EuStockMarkets)), type = "log")Huấn luyện mô hình và chạy mô phỏng
Sau khi đã có dữ liệu tỷ suất sinh lợi, bước tiếp theo là cấu hình và chạy mô phỏng bằng hàm simulate_rvine. Thuật toán sẽ tự động chuyển đổi dữ liệu sang dạng phân phối chuẩn hóa và tìm kiếm cấu trúc cây R-vine copula phù hợp nhất. Quá trình này tính toán qua nhiều vòng lặp để chọn ra kết quả có điểm đánh giá chất lượng cao nhất.
1result <- simulate_rvine(y, n = 500, verbose = TRUE, n_trials = 5)
2print(result)Hệ thống sẽ ghi nhận quá trình khớp mô hình và trả về các thông số cụ thể của cấu trúc D-vine. Các chỉ số như logLik, AIC và BIC được sử dụng để đánh giá độ khít của mô hình. Mỗi cạnh của cây copula sẽ được gán một họ phân phối cụ thể như SBB7, N hoặc SG cùng với các tham số tương quan tau của Kendall. Quá trình mô phỏng trải qua năm lần thử nghiệm, hệ thống sẽ chọn ra bộ dữ liệu có sai số tương quan thấp nhất.
Phân tích và đánh giá chất lượng dữ liệu tổng hợp
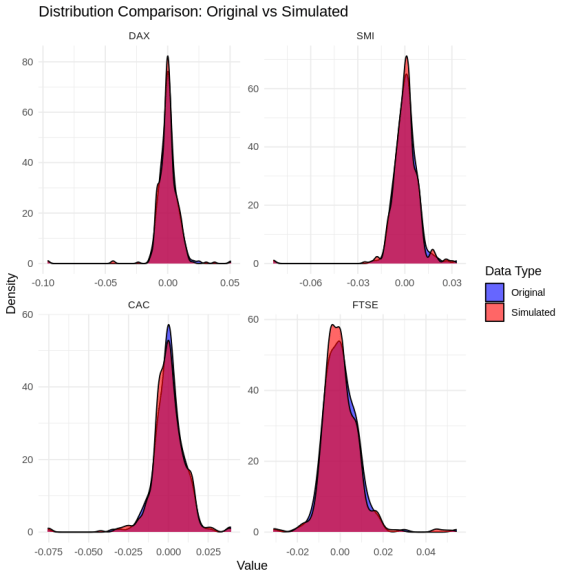
Dữ liệu sinh ra cần được đánh giá kỹ lưỡng để đảm bảo nó phản ánh đúng hành vi của dữ liệu gốc. Bạn có thể gọi các hàm vẽ biểu đồ cơ bản để trực quan hóa sự phân phối hoặc ma trận tương quan giữa các biến số.
1plot(result, type = "distribution")
2plot(result, type = "correlation")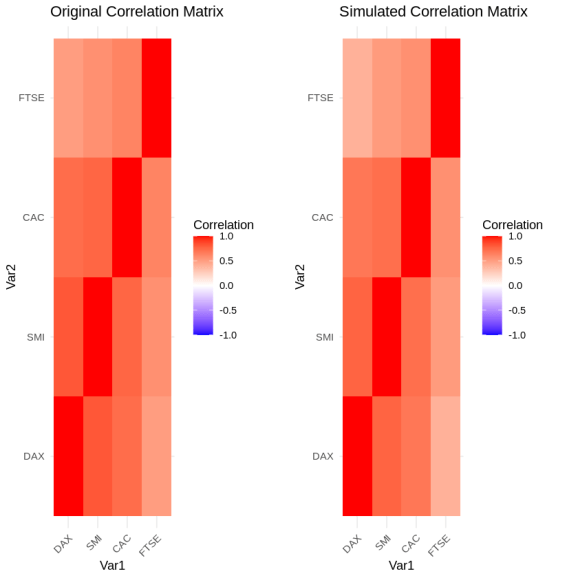
Bên cạnh việc quan sát qua biểu đồ, phần tử diagnostics trong kết quả trả về cung cấp một danh sách chi tiết các ma trận sai số. Hệ thống tính toán sự chênh lệch giữa ma trận tương quan của dữ liệu gốc và dữ liệu tổng hợp theo cả hai phương pháp Kendall tau và Pearson. Giá trị sai số tuyệt đối trung bình càng nhỏ, cùng với p-value cao trong các bài kiểm định phân phối, chứng tỏ dữ liệu mô phỏng càng sát với thực tế.
1str(result$diagnostics)
2sim_data <- result$simulated_data
3head(sim_data)Kết quả xuất ra sẽ là một bảng dữ liệu mới gồm các cột DAX, SMI, CAC và FTSE với năm trăm quan sát, mang đầy đủ tính chất của thị trường tài chính ban đầu nhưng hoàn toàn là các con số được tổng hợp nhân tạo.
✨ Việc ứng dụng R-vine copulas kết hợp với kỹ thuật chọn lọc vòng lặp nhiều lần giúp giảm thiểu tối đa sự biến dạng của ma trận tương quan, giải quyết triệt để bài toán mất mát thông tin khi sinh dữ liệu nhân tạo cho các chuỗi thời gian tài chính phức tạp.
Dựa vào danh sách kết quả diagnostics, bạn sẽ làm cách nào để quyết định xem việc tăng số vòng lặp mô phỏng lên hai mươi lần có thực sự cải thiện đáng kể sai số tương quan Pearson hay chỉ làm tăng chi phí tính toán phần cứng?