Trong các bài viết trước thuộc chuỗi hướng dẫn tích hợp Stata và Python, chúng ta đã tìm hiểu cách sử dụng module Stata Function Interface để xuất dữ liệu từ Stata sang Python. Bài viết hôm nay sẽ giải quyết bài toán ngược lại, đó là làm thế nào để chuyển dữ liệu trực tiếp từ môi trường Python vào Stata một cách hiệu quả. Để minh họa, chúng ta sẽ sử dụng thư viện yfinance của Python để tải dữ liệu lịch sử của chỉ số Dow Jones, sau đó chuyển toàn bộ dữ liệu này sang Stata để xử lý và vẽ đồ thị.
Sử dụng thư viện yfinance để tải dữ liệu tài chính
Bước đầu tiên là gọi thư viện yfinance trong môi trường Python. Chúng ta sẽ dùng phương thức download để lấy dữ liệu cho chỉ số Dow Jones từ trang Yahoo Finance. Phương thức này cần ba thông số cơ bản, bao gồm mã chứng khoán, ngày bắt đầu và ngày kết thúc.
Kết quả trả về sẽ là một data frame của pandas chứa hơn hai nghìn dòng dữ liệu và sáu cột, được đánh chỉ mục theo ngày tháng.
1import yfinance as yf
2dowjones = yf.download("^DJI", start="2010-01-01", end="2019-12-31")
3dowjonesXử lý kiểu dữ liệu chỉ mục trước khi chuyển đổi
Nếu kiểm tra chi tiết cấu trúc dữ liệu, bạn sẽ thấy cột chỉ mục được đặt tên là Date và lưu dưới định dạng datetime. Tuy nhiên, để Stata có thể tiếp nhận thông tin này một cách chính xác, chúng ta bắt buộc phải chuyển đổi cột chỉ mục này thành dạng string. Bạn có thể dùng phương thức astype để tạo một cột mới tên là dowdate chứa các giá trị ngày tháng đã được chuyển sang dạng chuỗi ký tự.
1dowjones['dowdate'] = dowjones.index.astype(str)
2dowjones['dowdate']Dùng SFI để sao chép dữ liệu từ Python sang Stata
Bây giờ chúng ta đã sẵn sàng để chuyển data frame này vào Stata. Đầu tiên, chúng ta cần gọi lớp Data từ module sfi. Tiếp theo, sử dụng phương thức setObsTotal để thiết lập số lượng quan sát trong Stata sao cho khớp với tổng số hàng của data frame trong Python.
Sau khi đã có đủ không gian, bước tiếp theo là tạo các biến trống trong Stata để chứa dữ liệu. Chúng ta sẽ dùng addVarStr để tạo một biến string mười ký tự cho ngày tháng, addVarDouble để tạo biến độ chính xác kép cho giá đóng cửa và addVarInt để tạo biến số nguyên cho khối lượng giao dịch.
Cuối cùng, phương thức store sẽ đảm nhận việc sao chép từng cột từ pandas sang các biến vừa tạo trong Stata.
1from sfi import Data
2Data.setObsTotal(len(dowjones))
3Data.addVarStr("dowdate",10)
4Data.addVarDouble("dowclose")
5Data.addVarInt("dowvolume")
6Data.store("dowdate", None, dowjones['dowdate'], None)
7Data.store("dowclose", None, dowjones['Adj Close'], None)
8Data.store("dowvolume", None, dowjones['Volume'], None)Làm sạch dữ liệu trong Stata
Dữ liệu đã nằm gọn trong Stata, nhưng chúng ta cần thực hiện một số thao tác quản lý dữ liệu trước khi vẽ đồ thị. Biến dowdate hiện đang là chuỗi ký tự, do đó ta cần dùng hàm date để tạo ra một biến thời gian chuẩn của Stata. Đồng thời, biến khối lượng giao dịch đang có giá trị rất lớn, ta sẽ chia cho một triệu để dễ đọc hơn và thêm nhãn dán cụ thể cho từng biến.
1generate date = date(dowdate,"YMD")
2format %tdCCYY-NN-DD date
3replace dowvolume = dowvolume/1000000
4format %10.2fc dowvolume
5label variable dowvolume "DJIA Volume (Millions of Shares)"
6label variable dowclose "DJIA Closing Price"
7list in 1/5, abbreviate(9)Trực quan hóa dữ liệu
Mục tiêu cuối cùng là tạo một đồ thị kết hợp, bao gồm một đường biểu diễn giá đóng cửa và một biểu đồ cột thể hiện khối lượng giao dịch. Lệnh twoway của Stata xử lý yêu cầu này rất trơn tru.
Điểm đáng lưu ý trong mã lệnh bên dưới là việc sử dụng tùy chọn trục tung thứ hai để biểu diễn khối lượng giao dịch ở cạnh phải của đồ thị. Trục bên trái màu xanh lá cây sẽ đại diện cho giá đóng cửa, trong khi trục bên phải màu xanh dương sẽ đại diện cho biểu đồ cột.
1twoway (line dowclose date, lcolor(green) lwidth(medium)) ///
2 (bar dowvolume date, fcolor(blue) lcolor(blue) yaxis(2)), ///
3 title("Dow Jones Industrial Average (2010 - 2019)") ///
4 xtitle("") ytitle("") ytitle("", axis(2)) ///
5 xlabel(, labsize(small) angle(horizontal)) ///
6 ylabel(5000(5000)30000, ///
7 labsize(small) labcolor(green) ///
8 angle(horizontal) format(%9.0fc)) ///
9 ylabel(0(500)3000, ///
10 labsize(small) labcolor(blue) ///
11 angle(horizontal) axis(2)) ///
12 legend(order(1 "Closing Price" 2 "Volume (millions)") ///
13 cols(1) position(10) ring(0))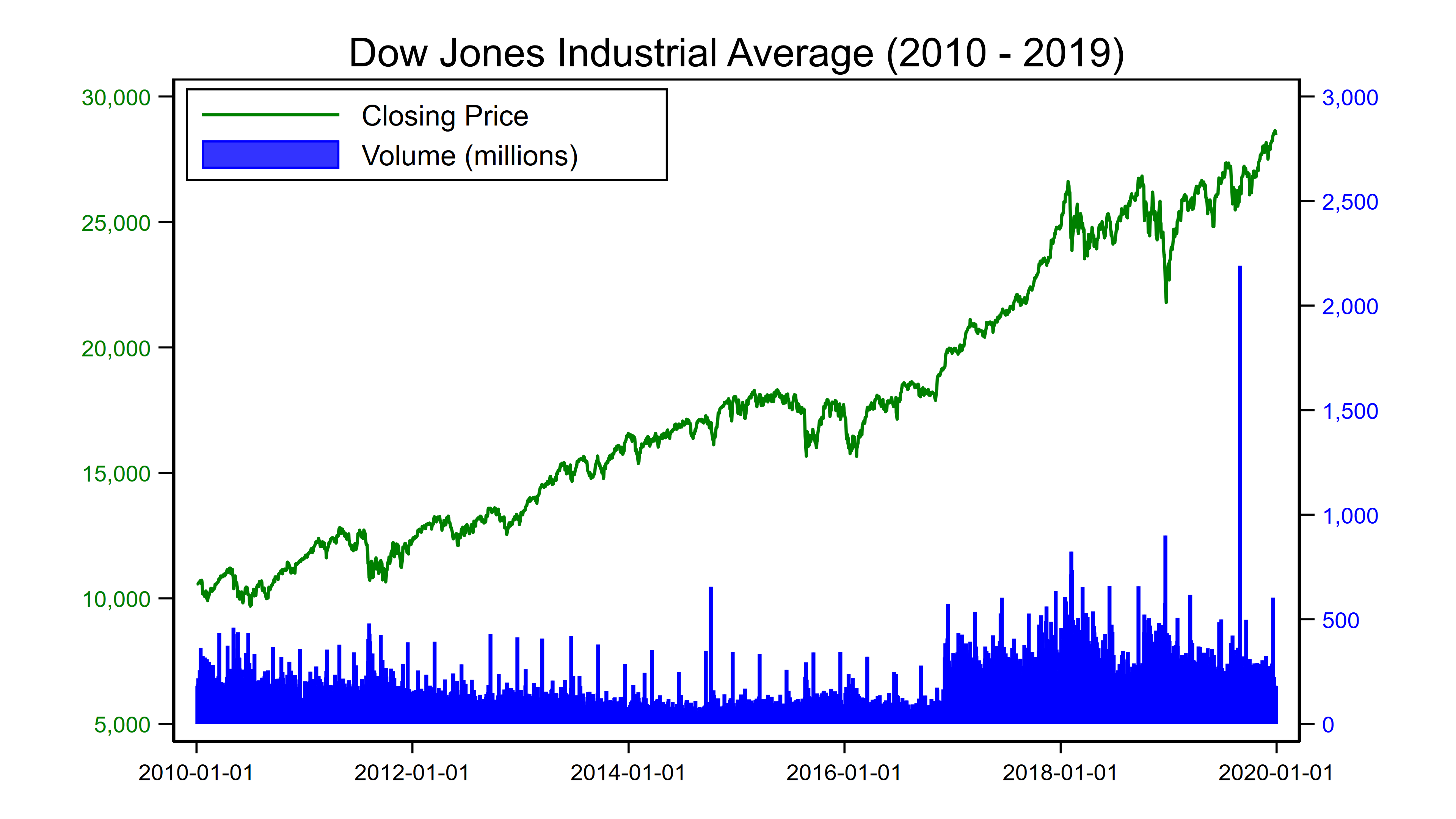
✨ Điểm cốt lõi của kỹ thuật tích hợp này nằm ở khả năng tối ưu hóa quy trình làm việc. Bạn hoàn toàn có thể dùng Python với hệ sinh thái API khổng lồ để tự động hóa việc thu thập dữ liệu thô, sau đó đẩy trực tiếp vào bộ nhớ của Stata để thực hiện các mô hình kinh tế lượng phức tạp mà không cần phải lưu trữ qua các tệp tin trung gian.
Thử thách dành cho bạn: Trong phương thức store của module SFI, chúng ta đã truyền giá trị rỗng cho đối số thứ hai và thứ tư để chép toàn bộ dữ liệu. Nếu bạn chỉ muốn chép đúng năm mươi mốc thời gian đầu tiên từ Python sang Stata, bạn sẽ thay đổi đối số trong phương thức này như thế nào?