Bước đầu tiên trong chuỗi giá trị của các đơn vị quản lý nước là khai thác nước từ các nguồn tự nhiên như sông, nước ngầm, đại dương hoặc hồ chứa. Các nhà quản lý nước và cộng đồng đều quan tâm đến việc hồ chứa hiện đang giữ bao nhiêu nước. Đây không phải là một bài toán dễ giải quyết, vì nó đòi hỏi quá trình phân tích kỹ lưỡng từ dữ liệu khảo sát thực địa đến tính toán thể tích thực tế. Bài viết này sẽ hướng dẫn cách trực quan hóa và phân tích dữ liệu đo đạc địa hình lòng hồ bằng ngôn ngữ R, sử dụng dữ liệu từ hồ chứa Prettyboy ở Maryland, Hoa Kỳ.
Hồ Chứa Prettyboy Và Nguồn Dữ Liệu
Trong quá trình tìm kiếm các khảo sát địa hình lòng hồ công khai, chúng ta có thể khai thác dữ liệu từ website của Cơ quan Khảo sát Địa chất Maryland. Tổ chức này nghiên cứu về địa chất và tài nguyên nước của bang Maryland. Hồ chứa Prettyboy đóng vai trò cung cấp nước cho gần hai triệu cư dân tại thành phố Baltimore và năm quận lân cận. Cơ quan này công bố dữ liệu đo đạc cho các hồ chứa của họ, bao gồm cả các thông số chi tiết về độ sâu và tọa độ.
Trích Xuất, Chuyển Đổi Và Tải Dữ Liệu
Dữ liệu thô được lưu trữ dưới dạng tệp CSV nén. Tệp này có cấu trúc hai dòng tiêu đề, trong đó dòng đầu tiên chứa tên trường và dòng thứ hai chứa đơn vị đo. Dữ liệu bao gồm ba cột chính: Easting, Northing và Depth.
Các giá trị Easting và Northing được định dạng theo phép chiếu UTM. Một điểm thú vị là độ sâu của hồ chứa được tính bằng feet. Trong các khảo sát địa hình lòng hồ, độ sâu thường được đo từ một mốc chuẩn dưới dạng số dương. Mốc số không ở đây chính là mực nước dâng bình thường của hồ chứa. Đoạn mã dưới đây thực hiện quy trình ETL để làm sạch dữ liệu, loại bỏ các điểm trùng lặp và các điểm lỗi ở góc bản đồ.
1library(tidyverse)
2library(RColorBrewer)
3rm(list = ls())
4if (!file.exists("data/PrettyBoy1998.dat")) {
5 download.file("http://www.mgs.md.gov/output/reservoir_bathy/PrettyBoy1998.zip",
6 destfile = "data/prettyboy-1998.zip")
7 unzip("data/prettyboy-1998.zip", exdir = "data")
8 file.remove("data/prettyboy-1998.zip")
9}
10rawdata <- read.csv("data/PrettyBoy1998.dat", skip = 1)
11fsl <- 145
12prettyboy <- rawdata |>
13 rename(easting = 1, northing = 2, depth_ft = 3) |>
14 filter(!duplicated(rawdata) & !(easting %in% range(easting))) |>
15 mutate(depth_m = depth_ft * 0.304)Trực Quan Hóa Dữ Liệu Khảo Sát
Phần trực quan hóa này hiển thị các đường mà tàu khảo sát đã di chuyển để thu thập dữ liệu sonar. Rìa của hồ chứa được đo bằng khảo sát trên cạn và có độ sâu bằng không. Đoạn mã dưới đây định nghĩa một bảng màu kết hợp giữa tông xanh lá cây và xanh dương để phân biệt rõ ràng giữa các vùng ven bờ và vùng nước sâu.
1bathymetry_colours <- c(rev(brewer.pal(3, "Greens"))[-2:-3],
2 brewer.pal(9, "Blues")[-1:-3])
3ggplot(prettyboy) +
4 aes(easting, northing, colour = depth_m) +
5 geom_point(size = .1) +
6 scale_x_continuous(labels = scales::label_comma()) +
7 scale_y_continuous(labels = scales::label_comma()) +
8 coord_equal() + labs(colour = "Depth [m]") +
9 scale_colour_gradientn(colors = bathymetry_colours) +
10 labs(title = "Prettyboy Reservoir Bathymetry (1988)",
11 caption = "Source: Maryland Geological Survey",
12 x = "Easting (UTM NAD83)", y = "Northing (UTM NAD83)") +
13 theme_minimal(base_size = 8)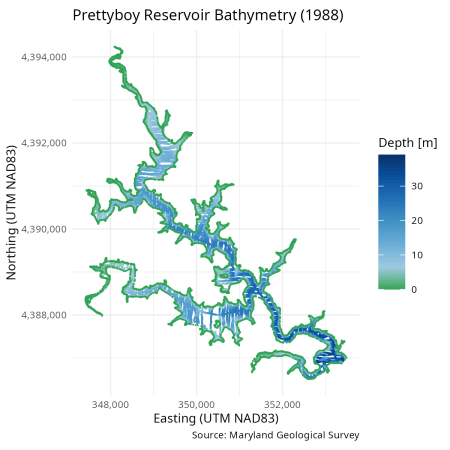
Chuyển Đổi Tọa Độ Và Bản Đồ Hóa
Các tọa độ ban đầu được cung cấp theo hệ tọa độ UTM NAD83 của Bắc Mỹ. Để hiển thị dữ liệu này trên các nền tảng bản đồ hiện đại, chúng ta cần chuyển đổi chúng sang kinh độ và vĩ độ thuộc hệ tọa độ WGS84.
Gói sf là công cụ mạnh mẽ để chuyển đổi các hệ tọa độ. Chúng ta sử dụng mã hiệu EPSG 26918 cho vùng Maryland và chuyển sang EPSG 4326 thường dùng trong Google Maps. Sau đó, gói ggmap sẽ hỗ trợ việc chồng lớp các điểm dữ liệu lên trên hình ảnh vệ tinh thực tế.
1library(sf)
2prettyboy_sf <- st_as_sf(prettyboy,
3 coords = c("easting", "northing"),
4 crs = 26918)
5prettyboy_wgs <- st_transform(prettyboy_sf, crs = 4326)
6coords <- st_coordinates(prettyboy_wgs)
7prettyboy_wgs <- cbind(prettyboy_wgs, coords) |>
8 rename(lon = X, lat = Y) |>
9 st_drop_geometry()
10library(ggmap)
11api <- readLines("data/google-maps.api")
12register_google(key = api)
13prettyboy_map <- get_map(c(mean(prettyboy_wgs$lon),
14 mean(prettyboy_wgs$lat)),
15 zoom = 14, color = "bw")
16ggmap(prettyboy_map, extent = "device") +
17 geom_point(data = as_tibble(prettyboy_wgs),
18 aes(lon, lat, col = depth_m), size = 0.1) +
19 scale_colour_gradientn(colors = bathymetry_colours, name = "Depth [m]") +
20 labs(title = "Prettyboy Reservoir Bathymetry (1988)",
21 caption = "Source: Maryland Geological Survey") +
22 theme_void(base_size = 10)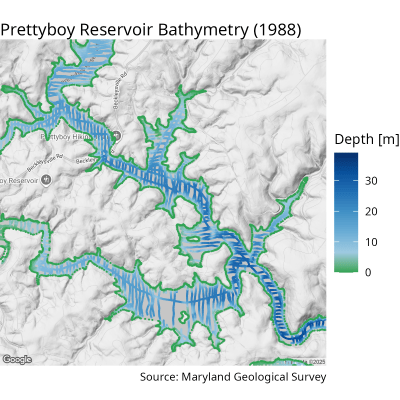
Phân Tích Thể Tích Hồ Chứa Bằng Phương Pháp Nội Suy Lưới
Có hai phương pháp chính để ước tính tổng thể tích của hồ chứa từ dữ liệu đo đạc. Phương pháp truyền thống sử dụng các đường đồng mức để vẽ mặt cắt ngang, sau đó tính diện tích từng phần và nhân với khoảng cách giữa chúng. Tuy nhiên, với sức mạnh tính toán hiện nay, chúng ta thường sử dụng phương pháp nội suy lưới.
Dữ liệu khảo sát chỉ tồn tại dọc theo các đường tàu chạy. Để ước tính thể tích, chúng ta tạo một lưới các ô vuông bao phủ lòng hồ và nội suy độ sâu cho từng ô. Thể tích tổng cộng là tổng của tích diện tích mỗi ô lưới nhân với độ sâu tương ứng của ô đó. Gói akima trong R giúp thực hiện việc nội suy dữ liệu phân tán này một cách hiệu quả. Với khoảng cách lưới là mười mét, kết quả tính toán cho ra thể tích khoảng bảy mươi mốt phẩy năm triệu mét khối, rất sát với con số mà cơ quan chức năng công bố.
1library(akima)
2dx <- 10
3dy <- 10
4x_seq <- seq(min(prettyboy$easting), max(prettyboy$easting), by = dx)
5y_seq <- seq(min(prettyboy$northing), max(prettyboy$northing), by = dy)
6interp_res <- with(prettyboy,
7 interp(x = easting,
8 y = northing,
9 z = depth_m,
10 xo = x_seq,
11 yo = y_seq,
12 duplicate = "strip",
13 linear = TRUE,
14 extrap = FALSE))
15prettyboy_grid <- interp2xyz(interp_res, data.frame = TRUE) |>
16 as_tibble() |>
17 rename(easting = x, northing = y, depth_m = z)
18grid_volume_m3 <- sum(prettyboy_grid$depth_m * dx * dy, na.rm = TRUE)
19grid_volume_m3 / 1e6Chúng ta cũng có thể sử dụng các giá trị nội suy này để tạo ra bản đồ với các đường đồng mức và các mặt cắt ngang của hồ chứa tại các vị trí ngẫu nhiên.
1set.seed(1234)
2northing_sections <- sample(prettyboy_grid$northing, 4)
3prettyboy_sections <- filter(prettyboy_grid, northing %in% northing_sections)
4max_depth <- round(max(prettyboy_sections$depth_m, na.rm = TRUE))
5map <- ggplot(filter(prettyboy_grid)) +
6 aes(easting, northing) +
7 geom_raster(aes(fill = depth_m), interpolate = TRUE) +
8 geom_contour(aes(z = depth_m), colour = "white", alpha = 0.4) +
9 geom_hline(yintercept = northing_sections, col = "orange") +
10 coord_equal() +
11 scale_x_continuous(labels = scales::label_comma()) +
12 scale_y_continuous(labels = scales::label_comma()) +
13 scale_fill_gradientn(
14 colours = c(NA, bathymetry_colours[-1]),
15 na.value = "transparent",
16 guide = guide_colourbar(reverse = TRUE),
17 name = "Depth [m]") +
18 theme_minimal(base_size = 28) +
19 labs(title = "Prettyboy Reservoir",
20 caption = "Source: Maryland Geological Survey",
21 x = "Easting [m]", y = "Northing [m]") +
22 theme(legend.position = "bottom",
23 legend.key.width = unit(2, 'cm'))
24sections <- ggplot(prettyboy_sections) +
25 aes(easting, (fsl - depth_m)) +
26 geom_area(fill = bathymetry_colours[1], alpha = 0.5) +
27 scale_x_continuous(labels = scales::label_comma()) +
28 facet_wrap(~rev(northing), ncol = 1) +
29 coord_cartesian(ylim = c(fsl - 1.1 * max(prettyboy_sections$depth_m, na.rm = TRUE), fsl)) +
30 theme_minimal(base_size = 28) +
31 labs(x = "Easting [m]", y = "Elevation [m]")
32library(gridExtra)
33grid.arrange(map, sections, ncol = 2)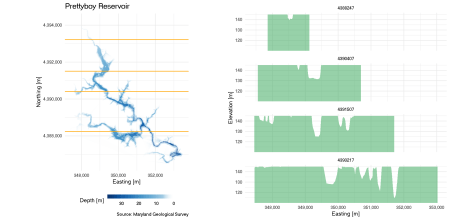
Phương Pháp Mạng Tam Giác Bất Quy Tắc
Phương pháp thứ hai để tính tổng thể tích là sử dụng mạng tam giác bất quy tắc, hay còn gọi là TIN. Một TIN đại diện cho bề mặt bao gồm các mặt tam giác. Khác với phương pháp lưới, mỗi tam giác trong mô hình này có diện tích khác nhau.
Chúng ta sử dụng thuật toán Delaunay để tạo ra các tam giác từ các điểm đo. Sau đó, diện tích của mỗi tam giác được tính bằng công thức diện tích đa giác thông qua tọa độ các đỉnh. Thể tích của mỗi phần tử tam giác bằng diện tích của nó nhân với độ sâu trung bình của ba đỉnh. Phương pháp này cho kết quả tương tự nhưng thường xử lý nhanh hơn vì không cần tạo thêm dữ liệu lưới mới.
1library(geometry)
2library(purrr)
3coords2d <- as.matrix(prettyboy[, c("easting", "northing")])
4tri <- delaunayn(coords2d)
5tin_df <- map_dfr(seq_len(nrow(tri)), function(i) {
6 idx <- tri[i, ]
7 data.frame(
8 tri_id = i,
9 easting = prettyboy$easting[idx],
10 northing = prettyboy$northing[idx],
11 depth_m = prettyboy$depth_m[idx])})
12triangle_area_shoelace <- function(x, y) {
13 abs(x[1] * (y[2] - y[3]) +
14 x[2] * (y[3] - y[1]) +
15 x[3] * (y[1] - y[2])) / 2}
16tin_volume <- tin_df |>
17 dplyr::group_by(tri_id) |>
18 dplyr::summarise(
19 area = triangle_area_shoelace(easting, northing),
20 mean_depth = mean(depth_m),
21 volume = area * mean_depth,
22 .groups = "drop")
23tin_volume_m3 <- sum(tin_volume$volume)
24tin_volume_m3 / 1e6Xây Dựng Biểu Đồ Đặc Tính Dung Tích Hồ Chứa
Cuối cùng, chúng ta cần một biểu đồ giúp chuyển đổi mực nước đo được thành thể tích tương ứng. Phương pháp dễ nhất là sử dụng mô hình lưới đã tạo ở trên. Bằng cách giả định các mực nước khác nhau, chúng ta tính toán thể tích phần nước nằm trên lòng hồ tại mỗi cao trình.
Dữ liệu tính toán cho thấy mối quan hệ giữa mực nước và thể tích tuân theo một hàm hồi quy bậc ba. Với phương trình này, các nhà vận hành hồ chứa có thể nhanh chóng xác định lượng nước hiện có dựa trên cao trình mực nước quan trắc được tại đập.
1levels <- seq(fsl + 15 - round(max(prettyboy$depth_m) / 10) * 10, fsl, by = 1)
2grid_capacity <- tibble(level = levels) |>
3 mutate(volume_m3 = map_dbl(level, \(L) {
4 bed <- fsl - prettyboy_grid$depth_m
5 depth_L <- pmax(0, L - bed)
6 sum(depth_L * dx * dy, na.rm = TRUE)}))
7cubic <- lm(volume_m3 ~ poly(level, 3, raw = TRUE), data = grid_capacity)
8grid_capacity$cubic = predict(cubic)
9ggplot(grid_capacity) +
10 aes(level, volume_m3 / 1e3) +
11 geom_point(col = "grey") +
12 geom_line(aes(level, cubic / 1e3)) +
13 geom_hline(yintercept = grid_volume_m3 / 1e3, linetype = 6, col = "red") +
14 scale_y_continuous(labels = scales::label_comma()) +
15 theme_minimal() +
16 labs(title = "Prettyboy Reservoir Capacity Curve",
17 x = "Water level", y = "Volume (km3)")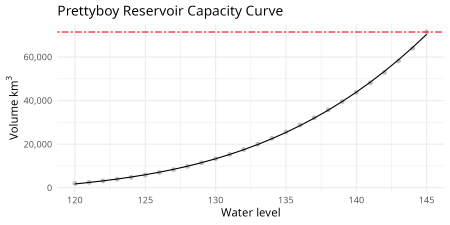
✨ Sự kết hợp giữa các gói xử lý dữ liệu không gian và công cụ thống kê trong R biến những con số khảo sát thô sơ thành thông tin quản lý tài nguyên nước cực kỳ giá trị và trực quan.
Câu hỏi tư duy: Theo bạn, việc thay đổi kích thước ô lưới từ mười mét xuống còn một mét sẽ ảnh hưởng như thế nào đến độ chính xác của ước tính thể tích và chi phí tính toán của hệ thống? Hãy thử thay đổi tham số dx và dy trong đoạn mã trên để kiểm chứng.