Trong phân tích dữ liệu, việc trình bày kết quả hồi quy một cách rõ ràng và chuyên nghiệp là bước quan trọng để truyền tải thông tin. Với phiên bản Stata 17, lệnh table đã được cải tiến đáng kể, cho phép người dùng tùy biến bảng biểu linh hoạt thông qua tùy chọn command. Bài viết này sẽ hướng dẫn bạn cách tạo một bảng kết quả cho mô hình hồi quy đơn lẻ, từ các thông số thô cho đến một định dạng hoàn chỉnh để xuất sang Microsoft Word.
Khởi tạo bảng cơ bản cho mô hình hồi quy
Trước tiên, chúng ta cần chuẩn bị dữ liệu. Trong ví dụ này, chúng ta sử dụng bộ dữ liệu khảo sát sức khỏe và dinh dưỡng quốc gia để nghiên cứu các yếu tố ảnh hưởng đến tình trạng cao huyết áp.
1webuse nhanes2l
2describe highbp age sex diabetesBộ dữ liệu bao gồm các biến như tuổi, giới tính, chỉ số cao huyết áp và tình trạng tiểu đường. Chúng ta sẽ thực hiện mô hình hồi quy logistic cho biến kết quả nhị phân là cao huyết áp, bao gồm các biến độc lập như tuổi, giới tính, tiểu đường và cả thành phần tương tác giữa tuổi và giới tính.
1logistic highbp c.age##i.sex i.diabetesĐể đưa kết quả này vào bảng biểu, chúng ta sử dụng lệnh table kết hợp với tùy chọn command. Theo mặc định, bảng sẽ hiển thị các hệ số hồi quy, trong trường hợp này chính là tỷ số chênh.
1table () (command result), command(logistic highbp c.age##i.sex i.diabetes)Khám phá và lựa chọn các thành phần kết quả
Stata tự động tạo ra một bộ sưu tập lưu trữ các chiều dữ liệu của bảng. Để biết chúng ta có thể đưa những thông số nào vào bảng, hãy kiểm tra danh sách các cấp độ trong chiều kết quả.
1collect label list result, allTrong danh sách trả về, các cấp độ bắt đầu bằng ký tự _r chính là nội dung của bảng hệ số. Ví dụ, _r_b chứa tỷ số chênh, _r_se chứa sai số chuẩn, và _r_ci chứa khoảng tin cậy. Chúng ta sẽ cập nhật lệnh table để bổ sung các thành phần này.
1table () (command result), command(_r_b _r_se _r_ci : logistic highbp c.age##i.sex i.diabetes)Định dạng số liệu và nhãn tiêu đề
Một bảng biểu chuyên nghiệp cần có định dạng số đồng nhất. Chúng ta sử dụng nformat để giới hạn số chữ số thập phân, sformat để thêm dấu ngoặc vuông cho khoảng tin cậy và cidelimiter để đặt dấu phẩy ngăn cách giữa hai giá trị của khoảng này.
1table () (command result), ///
2command(_r_b _r_se _r_ci : logistic highbp c.age##i.sex i.diabetes) ///
3nformat(%5.2f _r_b _r_se _r_ci) ///
4sformat("[%s]" _r_ci) ///
5cidelimiter(,)Tiếp theo, chúng ta thay đổi nhãn của các cột và tiêu đề mô hình để bảng trở nên dễ hiểu hơn đối với người đọc.
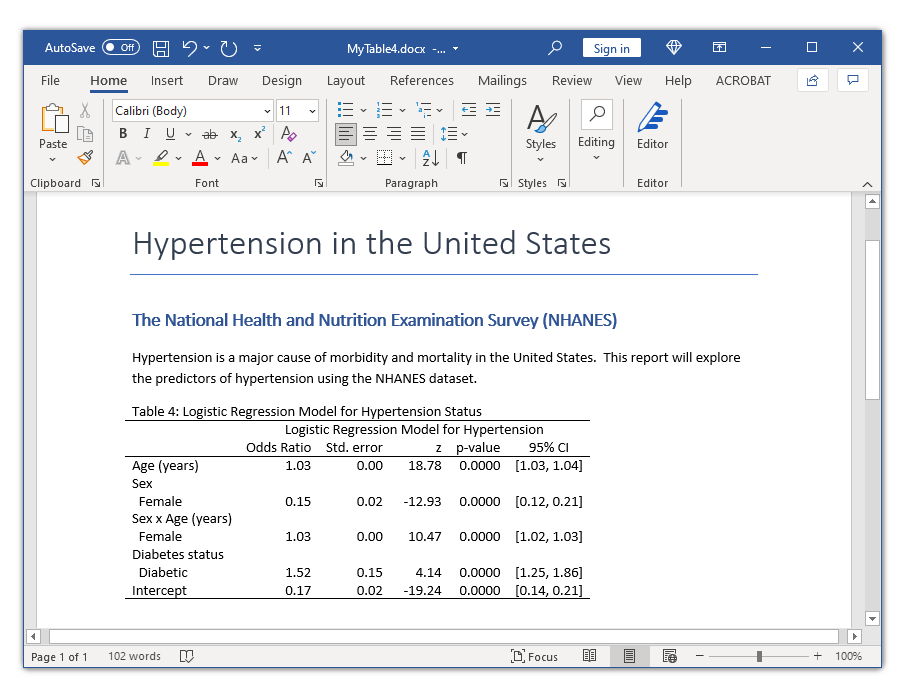
1collect label levels result _r_b "Odds Ratio", modify
2collect label levels command 1 "Logistic Regression Model for Hypertension", modify
3collect previewTinh chỉnh thẩm mỹ cho bảng biểu
Để bảng gọn gàng hơn, chúng ta có thể ẩn đi các mức cơ sở của biến định danh. Ngoài ra, việc sắp xếp nhãn dòng theo kiểu xếp chồng và loại bỏ các đường kẻ dọc sẽ giúp bảng trông thoáng hơn.
1collect style showbase off
2collect style row stack, nobinder delimiter(" x ")
3collect style cell border_block, border(right, pattern(nil))
4collect previewSau khi đã hoàn tất các bước định dạng, bạn có thể bổ sung thêm các cột như giá trị z và p-value để bảng đầy đủ thông tin nhất. Bước cuối cùng là xuất bảng sang Microsoft Word bằng lệnh putdocx.
1putdocx clear
2putdocx begin
3putdocx paragraph, style(Title)
4putdocx text ("Hypertension in the United States")
5collect style putdocx, layout(autofitcontents) title("Table 1: Logistic Regression Model")
6putdocx collect
7putdocx save MyTable.docx, replace✨ Quy trình này không chỉ áp dụng cho hồi quy logistic mà còn có thể thực hiện tương tự với hồi quy tuyến tính, hồi quy probit hoặc bất kỳ mô hình hồi quy nào khác trong Stata bằng cách thay đổi lệnh trong tùy chọn command.
Hãy thử áp dụng quy trình trên với một mô hình hồi quy tuyến tính sử dụng biến kết quả là một biến liên tục trong bộ dữ liệu của bạn. Làm thế nào để bạn thay đổi nhãn của hệ số hồi quy thay vì tỷ số chênh?